Andrew Ng机器学习编程作业:Logistic Regression
编程作业文件:
1. Logistic Regression (逻辑回归)
有之前学生的数据,建立逻辑回归模型预测,根据两次考试结果预测一个学生是否有资格被大学录取。
载入学生数据,第1,2列分别为两次考试结果,第3列为录取情况。
% Load Data
% The first two columns contain the exam scores and the third column contains the label.
data = load('ex2data1.txt');
X = data(:, [1, 2]); y = data(:, 3);
1.1 可视化数据
在实现任何机器学习算法之前,如果可能的话将数据可视化总是挺不错的。根据图1,完成plotData.m中的代码。作业中提供了答案,可以直接将下面代码复制到PlotData.m中,也可以自己写。
plotData.m填写代码:
% Find Indices of Positive and Negative Examples
pos = find(y==1); neg = find(y == 0);
% Plot Examples
plot(X(pos, 1), X(pos, 2), 'k+','LineWidth', 2, 'MarkerSize', 7);
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y','MarkerSize', 7);
或者循环画点
for i = 1:size(X,1)
if y(i) == 1
plot(X(i,1),X(i,2),"k+","LineWidth",2,"MarkerSize",7)
else
plot(X(i,1),X(i,2),"ko","MarkerFaceColor",'y',"MarkerSize",7);
end
end
画出的图像如图一所示

1.2 实现逻辑回归
1.2.1 热身训练:sigmoid函数
逻辑回归的的假设函数定义如下:
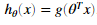
函数g是sigmoid函数定义如下:
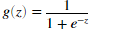
在sigmoid.m中实现sigmoid函数,调用sigmoid函数,如果输入0结果应该是0.5,输入一个很大的正数结果应该是接近1,输入一个很小的负数结果应该是接近0。
sigmoid代码如下:
g = 1./(1+exp(-1*z))
exp()求每个元素的e次幂。1./求每个元素的倒数。
1.2.2 成本函数和梯度
下面需要在costFunction.m 文件中实现成本函数和梯度,逻辑回归的成本函数为:

梯度为:
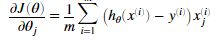
完成这两个函数后,调用下面这段代码成本函数的值为0.693,梯度的值大概为 -0.1000,-12.0092和 -11.2628。
costFunction.m 添加代码:
J = (1/m)*sum(-y.*log(1./(1+exp(-X*theta)))-(1-y).*log(1-1./(1+exp(-X*theta)))); grad = ((1/m)*sum((1./(1+exp(-X*theta))-y).*X))'
成本函数:X*thetah获得m*1的矩阵,y也是m*1的矩阵,所以可以做点乘运算。再通过sum函数获取所有元素的和。
梯度:(1./(1+exp(-X*theta))-y)获得m*1的矩阵,X为m*3的矩阵。将两者做点成运算,对应的列向量的元素相乘获得m*3的矩阵,使用sum函数,将用一个列向量每个元素相加,获得1*3的矩阵,在矩阵转置获得3*1的梯度。
结果:


1.2.3使用fminunc函数学习参数
之前我们通过梯度下降找到线性回归参数,我们写出价值函数和梯度,然后迭代采用梯度下降,这次我们不用梯度下降步骤,而是使用Matlab内置函数fminunc函数计算成本与theta参数。
fminunc是Matlab的一个优化求解器,来求无约束条件的函数极小值。在逻辑回归中我们希望通过参数优化J(theta),所以可以通过fminunc函数来找到最好的theta。给定固定的数据集(输入X与输出y),我们还需要给定fminunc函数如下输入:
- 我们希望优化的参数的初始值
- 成本函数和梯度
有无条件约束通常指的是参数有没有条件约束。比如参数theta,如果theta取值小于1则为有条件约束。
fminunc的一些其他介绍:
- 将GradObj设置为on表明同时返回成本值和参数值。MaxIter 设置为400,表明最少迭代400次。
- 指定我们需要求最小值函数,我们使用@(t)(costFunction(t,X,y)),优化参数t,使用自定义的函数costFunction(t,X,y)。
- 如果正确完成costFunction(t,X,y),fminunc将会收敛到正确的参数,并返回价值与参数theta。我们不需要写自己写迭代与学习速率。我们只需要指定价值函数与梯度。
调用下面代码,通过fminunc获得的最终theta值将会被用来绘制数据集的决策边界。绘制的图如图2所示:

1.2.4 评估逻辑回归
使用完成的逻辑回归模型预测学生会不会被大学录取。与评估测模型的准确率为多少。
如一个学生成绩为45与85,使用这个逻辑回归模型我们会看到他被录取的概率为0.776。
在 predict.m中填写代码,给定数据集与学习到的参数theta,这个预测函数应该产生1或0预测值。
predict.m中的代码:
p = round(sigmoid(X*theta))
round函数:四舍五入到最近整数。
结果:


2. 正则化逻辑回归
这部分,使用正则化逻辑回归预测制造工厂的微芯片通过质量检测的概率。每个芯片都会经过两次测试,有部分芯片的测试与是否通过质量检测历史数据,建立正则化回归模型。
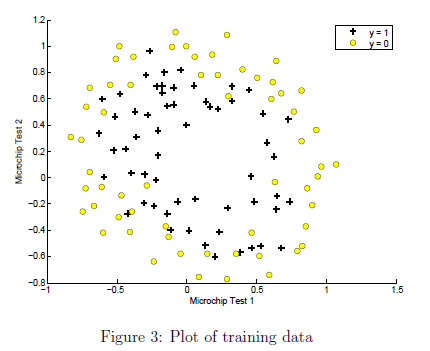
2.1 可视化数据
与之前一样,先在图上绘制数据。使用之前写的plotData绘制的图像如图三所示:
绘制代码:
data = load('ex2data2.txt');
X = data(:, [1, 2]); y = data(:, 3);
plotData(X, y);
% Put some labels
hold on;
% Labels and Legend
xlabel('Microchip Test 1')
ylabel('Microchip Test 2')
% Specified in plot order
legend('y = 1', 'y = 0')
hold off;
通过图三可以看到,正负例子不能通过直线划分。因此我们不能直接使用逻辑回归。
2.2 特征映射
一种解决不能通过直线分割数据集的方式是为每个数据建立更多的特征。在mapFeature.m文件中提供了映射函数。将x1,x2每个次幂映射到了多项式。

建立映射后,我们的输入X的两个特征应该被转换为28个特征。逻辑回归模型训练更高维的特征,使我们能绘制更复杂决策边界。
使用下面代码建立特征映射:
% Add Polynomial Features
% Note that mapFeature also adds a column of ones for us, so the intercept term is handled
X = mapFeature(X(:,1), X(:,2));
虽然特征映射可以让我们建立更有表现性的分类器,但同时也会让我们的模型过度拟合,在下一节我们会实现正则化逻辑回归,我们也会看到正则化是如何帮助我们克服过度拟合问题。
2.3 价值函数和梯度
现在我们需要实现正则化逻辑回归的价值函数和梯度,在costFunctionReg.m完成代码。
正则化逻辑回归价值函数:
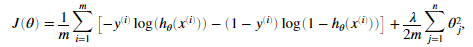
正则化逻辑回归价梯度:
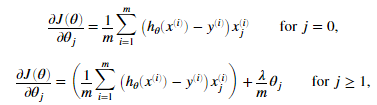
我们需要注意:对与参数theta0是不需要正则化的,因此在Matlab代码中,下标应该从2开始,2代表thean1。
costFunctionReg.m中的代码:
J = (1/m)*sum(-y.*log(1./(1+exp(-X*theta)))-(1-y).*log(1-1./(1+exp(-X*theta))))+lambda/(2*m)*sum(theta(2:size(theta)).^2); grad = ((1/m)*sum((1./(1+exp(-X*theta))-y).*X))';
grad(2:size(theta)) = grad(2:size(theta))+lambda/m*theta(2:size(theta));
价值函数前面部分代码与逻辑回归代码相同,只是加了参数的惩罚部分,对下标为2开始的theta惩罚。
梯度也同理,从下标为2的theta开是正则化。
调用下面代码对于theta初始化为0,我们会看到结果 0.693。
% Initialize fitting parameters
initial_theta = zeros(size(X, 2), 1); % Set regularization parameter lambda to 1
lambda = 1; % Compute and display initial cost and gradient for regularized logistic regression
[cost, grad] = costFunctionReg(initial_theta, X, y, lambda);
fprintf('Cost at initial theta (zeros): %f\n', cost);
结果:

2.3.1 使用fminunc学习参数
完成costFunctionReg.m,即提供了价值函数与梯度,运行下面代码会获得优化的参数。
2.4 绘制决策边界
为了帮助我们可视化分类器,作业提供了 plotDecisionBoundary函数帮助我们绘制非线性决策边界,绘制的图像如图4所示

2.5 选做的练习
在这一部分,我们会尝试这个数据集的不同的正则参数,理解正则化如何帮助我们阻止过度拟合。注意随着参数lambda的改变决策边界的改变。当lambda非常小的时候,我们的分类器将会让几乎所有的训练数据正确,因而绘制了非常复杂的决策边界,造成了过度拟合。如图5所示:
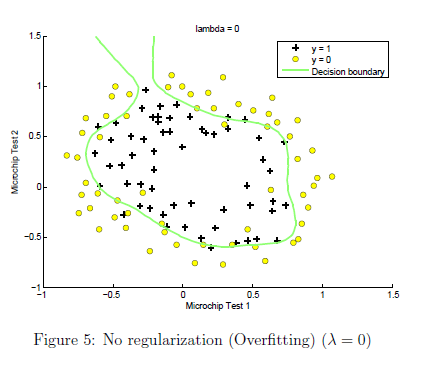
这不是一个好的决策边界,比如当 x =(0.25,1.5)y = 1。在图中就是错误的预测。当lambda大一点的时候,将会产生一个稍简单的决策边界,但还是会很好的区分正负。当时当lambda特别大的时候,就不会得到好的决策边界了,就会欠拟合,如图六所示。

通过下面代码观察
- 决策边界是如何随着lambda的值改变的
- 训练集的精度是如何变化的。
% Initialize fitting parameters
initial_theta = zeros(size(X, 2), 1); lambda = 1;
% Set Options
options = optimoptions(@fminunc,'Algorithm','Quasi-Newton','GradObj', 'on', 'MaxIter', 1000); % Optimize
[theta, J, exit_flag] = fminunc(@(t)(costFunctionReg(t, X, y, lambda)), initial_theta, options);
% Plot Boundary
plotDecisionBoundary(theta, X, y);
hold on;
title(sprintf('lambda = %g', lambda)) % Labels and Legend
xlabel('Microchip Test 1')
ylabel('Microchip Test 2') legend('y = 1', 'y = 0', 'Decision boundary')
hold off; % Compute accuracy on our training set
p = predict(theta, X);
fprintf('Train Accuracy: %f\n', mean(double(p == y)) * 100);
Andrew Ng机器学习编程作业:Logistic Regression的更多相关文章
- Andrew Ng机器学习编程作业: Linear Regression
编程作业有两个文件 1.machine-learning-live-scripts(此为脚本文件方便作业) 2.machine-learning-ex1(此为作业文件) 将这两个文件解压拖入matla ...
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 4—反向传播神经网络
课程笔记 Coursera—Andrew Ng机器学习—课程笔记 Lecture 9_Neural Networks learning 作业说明 Exercise 4,Week 5,实现反向传播 ba ...
- Andrew NG 机器学习编程作业3 Octave
问题描述:使用逻辑回归(logistic regression)和神经网络(neural networks)识别手写的阿拉伯数字(0-9) 一.逻辑回归实现: 数据加载到octave中,如下图所示: ...
- Andrew NG 机器学习编程作业2 Octave
问题描述:用逻辑回归根据学生的考试成绩来判断该学生是否可以入学 这里的训练数据(training instance)是学生的两次考试成绩,以及TA是否能够入学的决定(y=0表示成绩不合格,不予录取:y ...
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 2——逻辑回归
作业说明 Exercise 2,Week 3,使用Octave实现逻辑回归模型.数据集 ex2data1.txt ,ex2data2.txt 实现 Sigmoid .代价函数计算Computing ...
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 3—多分类逻辑回归和神经网络
作业说明 Exercise 3,Week 4,使用Octave实现图片中手写数字 0-9 的识别,采用两种方式(1)多分类逻辑回归(2)多分类神经网络.对比结果. (1)多分类逻辑回归:实现 lrCo ...
- Andrew Ng机器学习 二: Logistic Regression
一:逻辑回归(Logistic Regression) 背景:假设你是一所大学招生办的领导,你依据学生的成绩,给与他入学的资格.现在有这样一组以前的数据集ex2data1.txt,第一列表示第一次测验 ...
- Andrew Ng机器学习编程作业:Regularized Linear Regression and Bias/Variance
作业文件: machine-learning-ex5 1. 正则化线性回归 在本次练习的前半部分,我们将会正则化的线性回归模型来利用水库中水位的变化预测流出大坝的水量,后半部分我们对调试的学习算法进行 ...
- Andrew NG 机器学习编程作业5 Octave
问题描述:根据水库中蓄水标线(water level) 使用正则化的线性回归模型预 水流量(water flowing out of dam),然后 debug 学习算法 以及 讨论偏差和方差对 该线 ...
随机推荐
- zookeeper伪分布式安装
本文介绍zookeeper伪分布式安装. 所谓 “伪分布式集群” 就是在1台PC中启动多个zookeeper的实例.“完全分布式集群” 是每1台PC启动1个ZooKeeper实例. 由于我的测试环境P ...
- matplotlib 添加注释的方式
matplotlib 添加注释的方式 matplotlib.pyplot.annotate Annotate the point xy with text s s : str The text of ...
- hadoop集群的配置文件
export JAVA_HOME=/home/hadoop/apps/jdk1..0_131 1.hadoop-env.sh中配置JAVA_HOME export HADOOP_YARN_USER=/ ...
- spring security 一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架
Spring Security是一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架.它提供了一组可以在Spring应用上下文中 配置的Bean,充分利用了Spring ...
- [转]OpenMP中的private/firstprivate/lastprivate/threadprivate之间的比较
转自:http://blog.csdn.net/gengshenghong/article/details/6985431 private/firstprivate/lastprivate/threa ...
- android 开发积累
1.ListView滚动黑屏问题 ListView滚动时,数据项变成黑色 问题解决办法:通过添加 android:cacheColorHint = "#00000000" 将背景设 ...
- C++ 类模板四(typename关键字)
- python笔记6:常用模块
模块,模块就是封装了特殊功能的代码. 模块分为三种: 自定义模块 第三方模块 内置模块 1.自定义模块 自定义模块就是自己定义的模块,如何import自定义模块,如下: (1)主程序与模块程序在同一目 ...
- 用n(0)次求一个数组里面最大子数组的和(数组可以输入负数)
今天老师布置了题目上的任务,可谓是杀死人脑细胞不偿命呐... 在课上叽叽咕咕的讨论了一节课也没有答案,只得出几个备选方案,一个是通过枚举法将数组里面的子数组和一个个列出来然后在进行比较,可想而知(n2 ...
- C语言程序设计-同一天生日[综合应用]
[问题描述] 在一个有200人的大班级中,存在两个人生日相同的概率非常大,现给出每个学生的学号,出生月日,试找出所有生日相同的学生. [输入形式] 第一行为整数n,表示有n个学生,n<=200. ...