关于mysql开元数据库的几个随想
现在已经是凌晨了,昨天晚上写了我人生中的第一篇笔记,觉得没什么可写的,写了一个多小时都没写出什么,现在突然想写点东西了,这是一个比较有趣的问题,前两个月换了新工作,记得当初面试这份工作的时候面试到第三关(项目经理这关)的时候,他问到了我用过什么数据库,因为在回答过程中无意中说了oracle数据库是百万级别的数据库,mysql是中小型数据库的时候,面试经理反问我说听说现在的淘宝用的数据库就是mysql,这个怎么解释呢?说真的当时我真的不知道怎么解释,只是知道mysql是开元的,而oracle不是,所以当时的回答是:首先mysql是开元的,而oracle不是,而且像马云现在业务做的这么大,并不是他一个人在撑着的,而他能干别人干不了的事情的原因是他有很多聪明的员工,当然要看他的工程师怎么用咯!虽然我觉得这个回答不是正确的,但是说出自己的思路和理解总比不说或者说不会好吧!好吧!事实的确是这样。但经过工作之余时间的查看文档现在给这个问题做一个总结:
首相要声明一点的是MYSQL是开元的,开元的意味着MYSQL发展的很快,会变得很优秀,而且MYSQL说是一个数据库倒不如说是一种存储的规则,mysql的工作原理也简单明了,在最外层到里层分为 connectors、(连接管理器,包括安全的认证)、connection pool(连接池,挂你缓冲用户连接、线程处理)、management Service(系统管理和控制工具)、 &utilities、sql interface(sql接口,接手用户的sql命令、返回用户需要查询的结果)、parser(解析器,解析sql命令)、optimizer(查询优化器,历史调优执行过程策略方案处理)、cache&buffers(查询缓存)、storage engines(存储引擎)、file&logs。
通过配置mysql集群存储方案,可以提高性能和有较好的用错性,具有不共享、分布式节点框架的特点
读写分离
一台 Mysql 作为独立的数据库无法满足实际需求。在实际生产环境中,不论是安全性,高可
用性,还是高并发性等各个方面,单独一台 Mysql 都不足以满足业务需求。
故而现在的做法多为:通过主从复制(Master-Slave)的方式来实现数据同步,再通过读写分离
(MySQL-Proxy)来提升数据库的并发负载能力。使用这种方式进行开发部署,可以较好的解决
业务需求
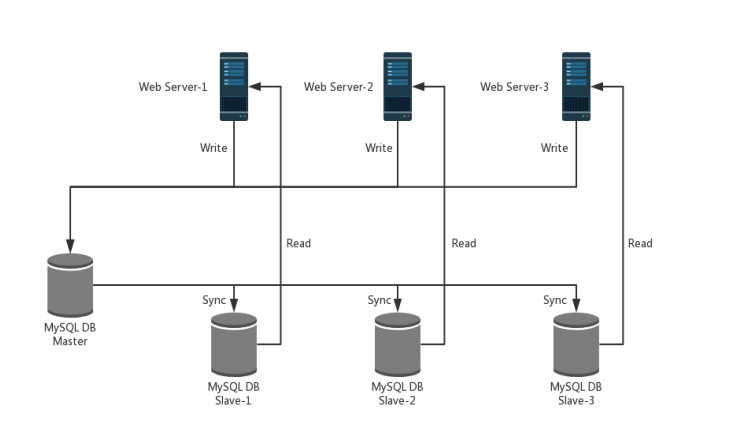
读写分离的原理:
让 Mater 处理增、改、删(INSERT、UPDATE、DELETE)操作,而 Slave 处理查询(SELECT)操作。
可以通过 MySQL-Proxy 实现读写分离,进行 MySQL-Proxy 读写分离至少需要有以下配置:
1. 数据库 Master 主服务器 x1
2. 数据库 Slave 从服务器 x1
3. MySQL-Proxy 调度服务器 x1
通过以下操作,可以实现读写分离,下列操作都是在 MySQL-Proxy 调度服务器上进行的。
1. MySQL 的安装与配置
2. 检查系统所需软件包
3. 编译安装 Lua
4. 安装配置 MySQL-Proxy
5. 配置并使用 rw-splitting.lua 读写分离脚本
完成以上操作后,即可测试读写分离效果。暂时关闭主从复制功能,连接 MySQL-Proxy,插
入任意记录。查询将发现没有新记录。分别登录到主从服务器查询,发现主服务器有插入记
录,从服务器没有。通过验证,MySQL 的读写分离已经达成,所有的写操作均在 Master 完
成。这样做,就避免了多个数据库同时写入可能造成的数据库不一致性。
此外,所有的读操作分摊给了各个 Slave,以此减轻数据库压力。
跨地区容灾
这里简单介绍一下使用双机热备进行跨地区容灾。
双机热备,简单来讲,就是令两个数据库保持状态自动同步。对于处于双机热备当中的数据
库,对其中任何一个进行操作都可以自动同步到另外一个,这样,就保持两个数据库当中的
数据始终一致。
这种方式有两个好处:
1. 异地容灾,其中一个坏了可以切换到另一个。
2. 负载均衡,可以将请求分摊到其中任何一台上,提高网站吞吐量。
备份工作原理:
两个原始数据相同的数据库 A 和 B,A 数据库中执行过的 sql 语句在 B 数据库里也同步执行一
遍,通过这样,A、B 数据库就可以一直保持同步。
上面是查阅资料找到的一些资料,这些资料足以证明mysql可提供配置和使用的方式很灵活,根据实际的数据特点配置合理的集群数据库的确有可能打赢oracle这个百万级别的数据库,而且通过灵活的配置反倒有更多的优点,例如容错和容灾性、没有百万级别数据库的那种笨重,后期未婚迁移灵活。
关于mysql开元数据库的几个随想的更多相关文章
- Hive的安装与部署(MySQL作为元数据库)
Hive的安装与部署(MySQL作为元数据) (开始之前确保Hadoop环境已经启动,确保Linux下的MySQL已经安装好) 1. 安装Hive (1)下载安装包 可从apache上下载hi ...
- hive安装用mysql作为元数据库,mysql的设置
mysql的设置 在要作为元数据库的mysql服务器上建立hive数据库: #建立数据库 create database if not exists hive; #设置远程登录的权限 GRANT AL ...
- Xampp apache与mySQL开不了 解决办法
Xampp安装后,打开Xampp control panel. 点击Apache对应的Start,开不了.原因是系统的服务占用了80端口,所以要么结束系统服务,要么修改apache端口. 个人比较喜欢 ...
- MySQL开发面试题
……继上一篇MySQL的开发总结之后,适当的练习还是很有必要的…… SQL语法多变,不敢保证唯一,也不敢保证全对,如果错误欢迎指出,即刻修改. 一.现有表结构如下图 TABLENAME:afinfo ...
- MySQL常用:Got a packet bigger than 'max_allowed_packet' bytes & MySQL开远程服务
1. 数据导入时出现错误 Got a packet bigger than 'max_allowed_packet' bytes 通过终端进入mysql控制台 mysql>show VARIAB ...
- 安装cloudera manager使用mysql作为元数据库
1.首次安装好mysql数据库后,会生成一个随机密码,使用如下办法找到: cat /var/log/mysqld.log |grep password 2.首次安装好mysql数据库后,第一次登陆进去 ...
- mysql开发之join语句学习
内连接:inner join -- 全外链接:full outer 左外连接:left outer 右外连接:right outer 交叉连接:cross内连接,两个表中重复部分全外连接,两个表所有字 ...
- hive上mysql元数据库配置
hive调试信息显示模式: ./hive -hiveconf hive.root.logger=DEBUG,console 非常有用. 默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只 ...
- 在Ubuntu上安装Mysql For Python
安装: 首先安装pip,并且把pip更新到最小版本 apt-get install python-pip pip install -U pip 安装mysql开发包 apt-get install p ...
随机推荐
- redis存储数据的时候
使用redis存储数据的时候,有时候为了查看的方便,通常会有层级或者说是目录, 这时候我们在set的时候,需要将key值使用“:”的符号来区分层级关系,比如:set(“a:b”, “123”),那么在 ...
- 一、hadoop 及 hadoop的环境搭建
一.Hadoop引言 Hadoop是在2006年雅虎从Nutch(给予Java爬虫框架)工程中剥离一套分布式的解决方案.该方案参考了Goggle的GFS(Google File System)和Map ...
- iOS获取通讯录所有联系人信息
以下是2种方式: 第一种方法: GetAddressBook.h #import <Foundation/Foundation.h> @interface GetAddressBook : ...
- Apache常规配置说明
Apache配置文件:conf/httpd.conf.(注意:表示路径时使用‘/’而不使用‘\’,注释使用‘#’) 1. ServerRoot:服务器根目录,也就是Apache的安装目录,其他的目录配 ...
- hive优化-数据倾斜优化
数据倾斜解决方法,通常从以下几个方面进行考量: 业务上丢弃 • 不参与关联:在on条件上直接过滤 • 随机数打散:比如 null.空格.0等“Other”性质的特殊值 倾斜键记录单独处理 • ...
- lr中常用函数以str开头函数
对各函数的定义: strcat( ):添加一个字符串到另一个字符串的末尾.strncat (拼接指定长度字符串) --粘贴操作 ...
- POJ-3436:ACM Computer Factory (Dinic最大流)
题目链接:http://poj.org/problem?id=3436 解题心得: 题目真的是超级复杂,但解出来就是一个网络流,建图稍显复杂.其实提炼出来就是一个工厂n个加工机器,每个机器有一个效率w ...
- 3329: Xorequ
3329: Xorequ https://www.lydsy.com/JudgeOnline/problem.php?id=3329 分析: 因为a+b = a^b + ((a&b)<& ...
- Calendar 实现日历实例
import java.text.ParseException; import java.util.Calendar; import java.util.GregorianCalendar; impo ...
- 只需两步,rails支持CSV格式导出
一.Controller最上方添加 require 'csv' 二.方法里面添加 format.csv do csv_string = CSV.generate do |csv| csv <&l ...