(原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标、最大判定边界、核函数、SVM使用方法、多分类问题等,Machine learning课程地址为:https://www.coursera.org/course/ml
大家对于支持向量机(SVM)可能会比较熟悉,是个强大且流行的算法,有时能解决一些复杂的非线性问题。我之前用过它的工具包libsvm来做情感分析的研究,感觉效果还不错。NG在进行SVM的讲解时也同样建议我们使用此类的工具来运用SVM。
(一)优化目标(Optimization objective)
首先回顾一下逻辑回归(logistic regression):
objective function: 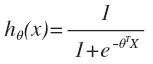
Decision boundary:
- if y = 1,we want hθ(x) ≈ 1 即 θTx » 0
- if y = 0,we want hθ(x) ≈ 0 即 θTx « 0
Cost Function:
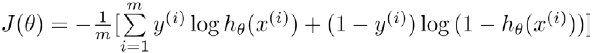
Goal: Min J(θ)
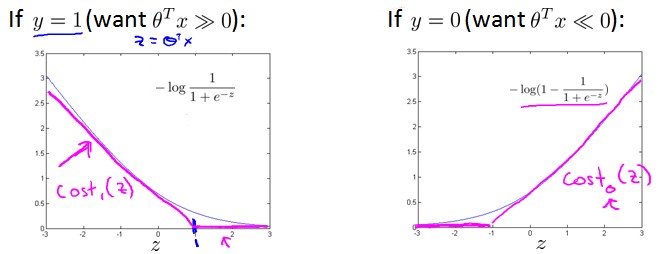
其中J(θ)中的log项如下图中的蓝色曲线所示,可见该部分始终≠0。而对于SVM,我们使用紫色折线所示的分段的折线作为代价函数(cost function中的log部分)。
SVM的cost Function:
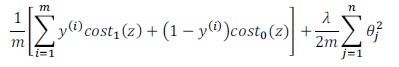
为最小化J(θ),理想中令J(θ)→0,那么:
- if y = 1,对于cost1(z),when z ≥ 1,cost1(z) = 0;
- if y = 0,对于cost0(z),when z ≤ -1,cost1(z) = 0;
调整SVM的cost Function:
- 去掉1/m(对最优化结果不影响);
- 令C = 1/λ,使得cost function中的正则项主要控制代价函数(J(θ)左部分)部分;
调整后SVM的cost Function:
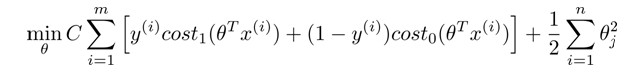
PS:调整后的J(θ)是一个凸函数(convex function),故求解时不会陷入局部最优。
(二)SVM最大判定边界(Large Margin Classifier)
假设C取一个很大的值,为Min J(θ),就要求J(θ)中左边的部分尽量小,理想中→0,那么:
- y=1时,令Cost1(θTx)=0,即θTx ≥ 1(not just ≥ 0);
- y=0时,令Cost0(θTx)=0,即θTx ≤ -1(not just < 0);
decision boundary:
definition:能将所有样本点很好分类的h(x)边界,由于SVM可以找到一个与样本点之间有最大间隔的判定边界,故也叫做最大间隔分类器(Large Margin Classifier)。
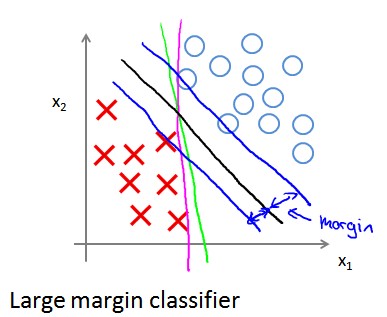
例如,对于下图所示的分类问题,绿色、紫色和黑色直线都可以作为分类boundary,SVM就是尝试找到黑色直线这样的boundary,它距两个类相对较远。
C对boundary的影响:
假设我们的样本点分布如下图所示:
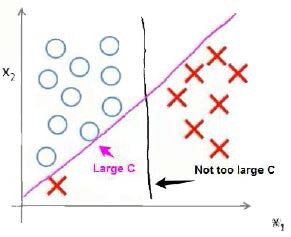
若data中存在一个明显的异常值,若C较大,SVM的判定边界为紫色直线;若C较小,SVM的判定边界为黑色直线。所以,我们可以的到结论:C值越小,SVM对异常数据越不敏感。
可以看出,C的取值可以在分类是否犯错和margin的大小上做一个平衡。
(三)SVM形成Large Margin 的数学原因
从上一节中可以看出,当C较大时,会形成Large Margin Classification。
有人可能会问“为什么SVM是Large Margin Classification?”,下面就从数学的角度来解释。
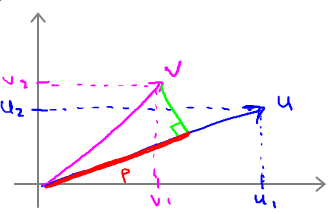
1.向量内积(inner product)
假设向量u、v是二维向量,那么u·v=uTv=u1v1+u2v2。在坐标系上表现为:将v投影到u上,其投影长度为p(u、v同向则p>0,反向则p<0),即u·v=uTv=||u||·||v||·cosθ = ||u||·p = u1v1+u2v2。其中 ||u|| = sqrt(u12+u22)。
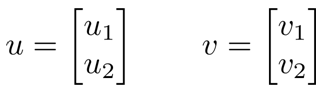
 |
 |
2.SVM Decision Boundary
回到之前的问题,“为什么选用较大的C会得到Large Margin Classification?”,当C较大,Min J(θ)时,要求J(θ)→0,那么 J(θ)只剩下右边的θ求和部分,现假设θ0=0,只剩下θ1和θ2:
Goal:
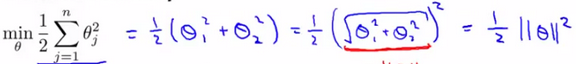
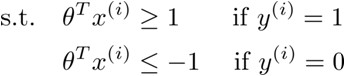
由于θTx(i) = p(i)·||θ|| = θ1x1(i) + θ2x2(i),p是x在θ上的投影,则cost Function的边界改为:
- y=1时,要求Cost1(θTx)=0,那么p·||θ|| ≥ 1
- y=0时,令Cost0(θTx)=0,那么p·||θ|| ≤ -1
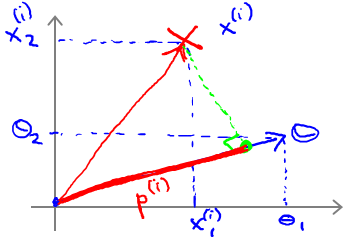
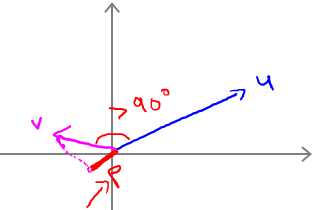
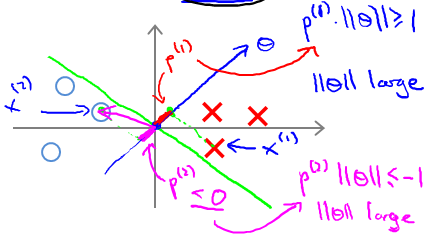
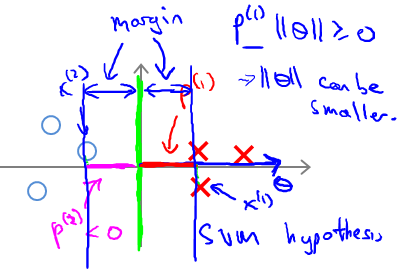
那么对下图所示的data set,绿色直线表示decision boundary,蓝色线表示θ向量。紫色为样本点在θ上面的投影。
已知 boundary与θ向量呈90°.对于左边图所示的decision boundary,可见样本点在θ上面的投影非常小,即P很小,因此很难满足(y=1时,p·||θ|| ≥ 1;y=0时,p·||θ|| ≤ -1)的条件。因为,在p很小的情况下,只能使||θ||很大,这样就违背了 min 1/2*||θ||2,故这不是SVM得到的 boundary。同理,右边这个图中的 boundary就是比较好的,两边的数据在θ上面的投影都很大,这样||θ||就可以很小,这样按照cost Function求解就可以得到有large margin的 boundary了。
 |
 |
(四)核函数(Kernels)
在之前的学习中,我们知道对于非线性的问题我们可以通过构造多项式来拟合Decision boundary。
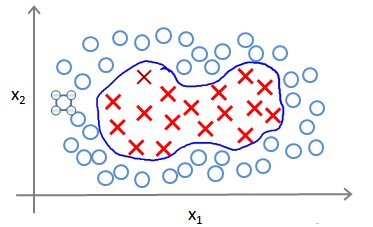
为得到上图中的边界,我们的模型可能是θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+...,用新特征f来替换模型中的项,如f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22,...,那么hθ(x)=f1+f2+...+fn。除了对特征进行组合之外,还有没有其他的方法构造f1,f2,f3么?
给定样本x,计算x与我们预先选定的地标(landmarks)l(1),l(2),l(3)的近似度作为特征f1,f2,f3。
eg:
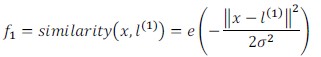
其中||x-l(1)||2 是x的所有特征与地标l(1)之间的距离之和,similarity(x,l(1))是高斯核函数(Gaussian Kernel)。
- if x 距离 l(1)很近,那么f1≈e0 ≈ 1;
- if x距离l(1)很远,那么f1≈e-(large number) ≈ 0;
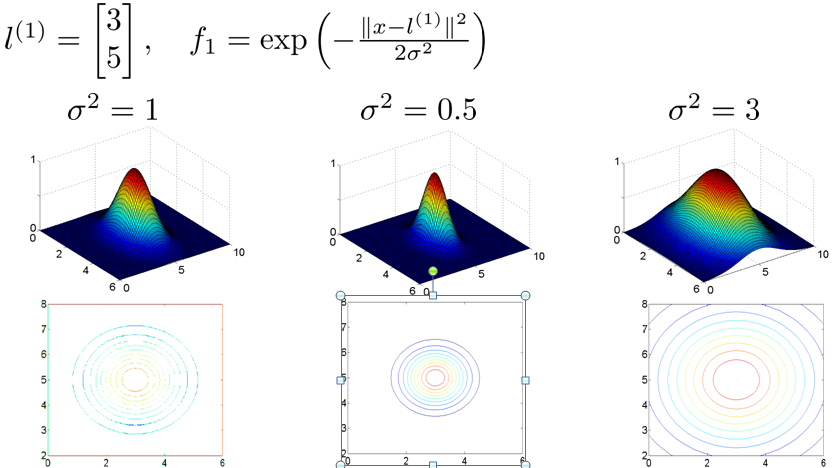
现假设训练集样本有两个特征x1,x2,给定地标l(1)和σ值。下图中水平面坐标为x1,x2,垂直坐标为f。因此当x与l(1)重合时具有最大值。随x改变f的变化速率受σ2影响。
SVM核函数的运用:
如下图所示,当预测实例x处于紫色点位置,可以看出x离l(1)较近,离l(2),l(3)较远,故f1≈1,f2,f3≈0。因此hθ(x)=θ0+θ1f1+θ2f2+θ3f3>0,预测y=1。同理当预测实例x处于绿色点位置,也预测y=1。若预测实例x处于蓝色点位置,可见x离l(1),l(2),l(3)三个地标都较远,预测y=0。

这样,图中红色的曲线便是我们依据训练实例和地标得到的判定边界。
PS:预测时,我们采用的特征并非训练实例本身,而是通过核函数计算出的新特征f1,f2,f3。
Landmark的选择:
通常,我们根据data set的数量来选择地标的数量。即若data set中有m个样本,则选取m个landmark。且令l(1)=x(1),l(2)=x(2),...,l(m)=x(m)。那么对于训练样本x(i):
- f0(i) = 1
- f1(i)=similarity(x(i),l(1))
- f2(i)=similarity(x(i),l(2))
- ...
- fi(i)=similarity(x(i),l(i)) = similarity(x(i),x(i))=1
- ...
- fm(i)=similarity(x(i),l(m))
SVM的使用步骤:
objective function:给定x,计算x的新特征f,若θTf ≥ 0,预测y=1。否则y=0.
cost function: 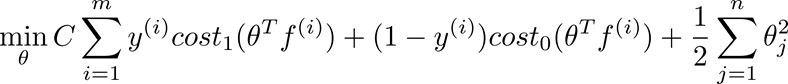
有人会问:“为什么在逻辑回归中没有使用核函数呢?”其实在逻辑回归中我们也可以使用核函数,但是计算会非常耗时。
其他核函数:
以下这些核函数的目标也是根据training set和landmarks之间的距离来创建新的特征,这些核函数要满足Mercer's定理。
- 多项式核函数(Polynomial Kernel)
- 字符串核函数(String kernel)
- 卡方核函数( chi-square kernel)
- 直方图交集核函数(histogram intersection kernel)
(五)SVM的使用
我们在这里不介绍SVM Min J(θ)的方法,可以使用软件包(libsvm,liblinear等)。在使用这些软件包时,我们通常需要选择适当的核函数和C参数。
PS:
- 若使用高斯核函数,在使用前需对数据进行缩放。
- 如果我们不采用复杂的函数或training set特征多而样本数较少时,也可以不使用核函数(或linear kernel)的SVM。
C和σ2对SVM的影响:
- C较大(λ较小)时,可能会过拟合(Low bias, high variance);
- C较小(λ较大)时,可能会欠拟合(High bias, low variance);
- σ2较大时,High bias, low variance;
- σ2较小时,Low bias, high variance;
(六)多分类问题(Multi-class classification)
可使用one-vs.-all 方法:类似雨之前讲的逻辑回归的多分类问题的解决,对于k个类,需要训练k个模型,得到k个参数向量θ,选择θTx的最大值对应的分类。实际上,很多软件包都有内置的多分类功能,可以直接使用。
(七)逻辑回归 vs. SVM
n: number of features ;
m: number of training examples;
| 逻辑回归/(linear knenal)的SVM | 高斯核函数的SVM |
|
对m而言n要大很多; n较小,m较大:如n在1-1000之间,而m>50000; |
n较小,m大小适中:如n在1-1000之间,m在10-10000之间; |
PS:神经网络在上述三种情况下都有很好的表现,但是训练神经网络可能会非常慢。
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Support Vector Machines部分作业的核心代码:
1.gaussianKernel.m
sim=exp(-sum((x1-x2).^2)/(2*sigma^2));
2.dataset3Params.m
step = [0.01,0.03,0.1,0.3,1,3,10,30];
J = zeros(length(step));
for i = 1:length(step)
for j = 1:length(step)
C = step(i);
sigma = step(j);
model = svmTrain(X,y,C,@(x1,x2)gaussianKernel(x1,x2,sigma));
predict = svmPredict(model,Xval);
J(i,j) = mean(double(predict ~= yval));
end
end min_c=1;
min_s=1;
for i=1:length(step)
for j=1:length(step)
if J(i,j)<J(min_c,min_s)
min_c=i;
min_s=j;
end
end
end C=step(min_c);
sigma=step(min_s);
3.processEmail.m
for i=1:length(vocabList)
temp = strcmp(str,vocabList{i});
if temp == 1
word_indices = [word_indices;i];
end
end;
4.emailFeatures.m
x(word_indices) = 1;
(原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines的更多相关文章
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念.优化目标.聚类中心等内容:特征降维包括降维的缘由.算法描述.压缩重建等内容.coursera上面Andrew NG的Mach ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 在Linear Regression部分出现了一些新的名词,这些名 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 5) Neural Networks Learning
本栏目内容来自Andrew NG老师的公开课:https://class.coursera.org/ml/class/index 一般而言, 人工神经网络与经典计算方法相比并非优越, 只有当常规方法解 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
随机推荐
- 【Python学习笔记】Coursera课程《Python Data Structures》 密歇根大学 Charles Severance——Week6 Tuple课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week6 Tuple 10 Tuples 10.1 Tuples A ...
- UVALive 7040 Color
题目链接:LA-7040 题意为用m种颜色给n个格子染色.问正好使用k种颜色的方案有多少. 首先很容易想到的是\( k * (k-1)^{n-1}\),这个算出来的是使用小于等于k种颜色给n个方格染色 ...
- Redis、mongdb、memcached的个人总结
有测试的实例:http://colbybobo.iteye.com/blog/1986786 详细描述优缺点:https://www.cnblogs.com/binyue/p/4582550.html
- js cookies的使用及介绍 (非常详细)
设置cookie 每个cookie都是一个名/值对,可以把下面这样一个字符串赋值给document.cookie:document.cookie="userId=828";如果要一 ...
- NOI openjudge 1792.迷宫
一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由n * n的格点组成,每个格点只有2种状态,.和#,前者表示可以通行后者表示不能通行.同时当Extense处在某个格点时,他只 ...
- hdu 2881(LIS变形)
Jack's struggle Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65535/65535 K (Java/Others) ...
- 通过kubeadm安装kubernetes 1.7文档记录[docker容器方式]
参照了网上N多文档,不一一列表,共享精神永存!!!! ================================================== 获取所有安装包 安装包分为两类,rpm安装包 ...
- hdu5798
官方题解: 考虑去掉abs符号,发现只有相邻两个数的最高位被影响了才会影响abs的符号,所以可以按照最高位不一样的位置分类,之后考虑朴素枚举x从0到2^20,每次的复杂度是O(400),无法通过,考虑 ...
- jQuery源码浅析
这几天看了下jQuery源码,有些收获,解答了我以前对jQuery的疑问,现在我把收获分享给大家. 一.jQuery为何弄成自执行函数,以及为何在引用了jquery文件之后,可以通过$或jQuery来 ...
- ionic3包还原使用yarn命令执行步骤(解决ionic3懒加载报找不到 module的错误)
使用cnpm 还原ionic3.6的依赖包的时候 可以正常还原,但是使用懒加载就会报找不到 module 的错误.最简单的解决办法是删除node_modules 挂个vpn 重新执行npm insta ...