win7下idea远程连接hadoop,运行wordCount
1.将hadoop-2.6.1.tar.gz解压到本地
配置环境变量
HADOOP_HOME
E:\kaifa\hadoop-2.6.1\hadoop-2.6.1
HADOOP_BIN_PATH
%HADOOP_HOME%\bin
HADOOP_PREFIX
%HADOOP_HOME%
配置path
E:\kaifa\jdk1.7.0_21\bin;%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
2.用idea新建一个maven项目
导入hadoop依赖包
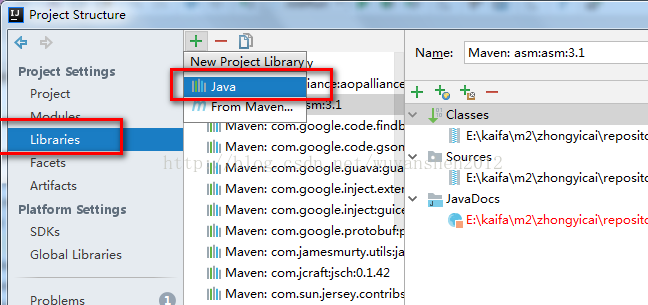
File>Project Structure>Project Settings>Libraries,点+号然后选择Java,然后选择解压出来的hadoop-2.6.1文件夹下share\hadoop\下的jar包
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.hadoop261</groupId>
<artifactId>myhadoop</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.1</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
</dependencies> <build>
<finalName>${project.artifactId}</finalName>
</build>
WcMapper.java
package hadoop.test; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer; public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// IntWritable one=new IntWritable(1);
String line=value.toString();
StringTokenizer st=new StringTokenizer(line);
//StringTokenizer "kongge"
while (st.hasMoreTokens()){
String word= st.nextToken();
context.write(new Text(word),new IntWritable(1)); //output
}
}
}
McReducer.java
package hadoop.test; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /**
* Created by iespark on 2/26/16.
*/
public class McReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable i:iterable){
sum=sum+i.get();
}
context.write(key,new IntWritable(sum));
}
}
JobRun.java
package hadoop.test; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* Created by iespark on 2/26/16.
*/
public class JobRun {
public static void main(String[] args){
Configuration conf=new Configuration();
try{
Job job = Job.getInstance(conf, "word count");
onfiguration conf, String jobName
job.setJarByClass(JobRun.class);
job.setMapperClass(WcMapper.class);
job.setReducerClass(McReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//解决No job jar file set. User classes may not be found. See Job or Job#setJar(String)报错的问题
job.setJar("E:\\idea2017workspace\\myhadoop\\out\\artifacts\\myhadoop_jar\\myhadoop.jar"); FileInputFormat.addInputPath(job,new Path(args[0]));
FileSystem fs= FileSystem.get(conf);
Path op1=new Path(args[1]);
if(fs.exists(op1)){
fs.delete(op1, true);
System.out.println("存在此输出路径,已删除!!!");
}
FileOutputFormat.setOutputPath(job,op1);
System.exit(job.waitForCompletion(true)?0:1);
}catch (Exception e){
e.printStackTrace();
}
}
}
3.设置jar包的生成位置
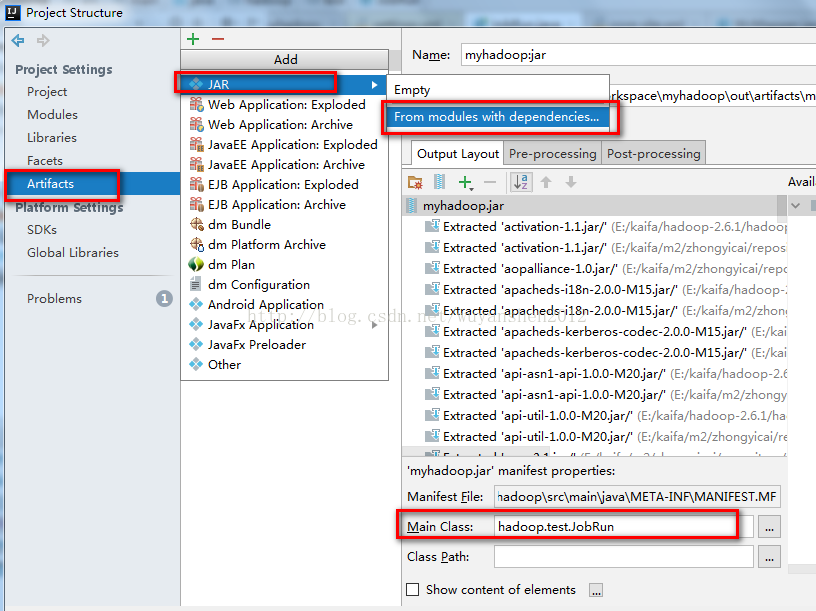
注意最下面的Main Class别忘记选择
然后把这个路径放在JobRun.jar中的
job.setJar("E:\\idea2017workspace\\myhadoop\\out\\artifacts\\myhadoop_jar\\myhadoop.jar");
3.在sources文件夹中新增core-site.xml和log4j.properties文件
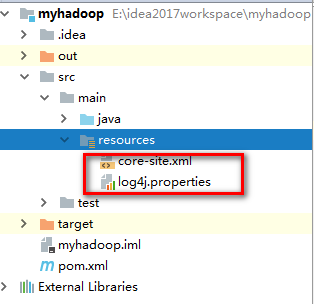
core-site.xml 配置内容和你的hadoop集群的配置一样
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<!--配置namenode的地址--> <property>
<name>fs.defaultFS</name>
<value>hdfs://10.102.19.229:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///data/hadoop/data/tmp</value>
</property>
</configuration>
log4j.properties文件可以将hadoop-2.6.1下的hadoop-2.6.1\etc\hadoop中的log4j.properties复制过来,不用修改!
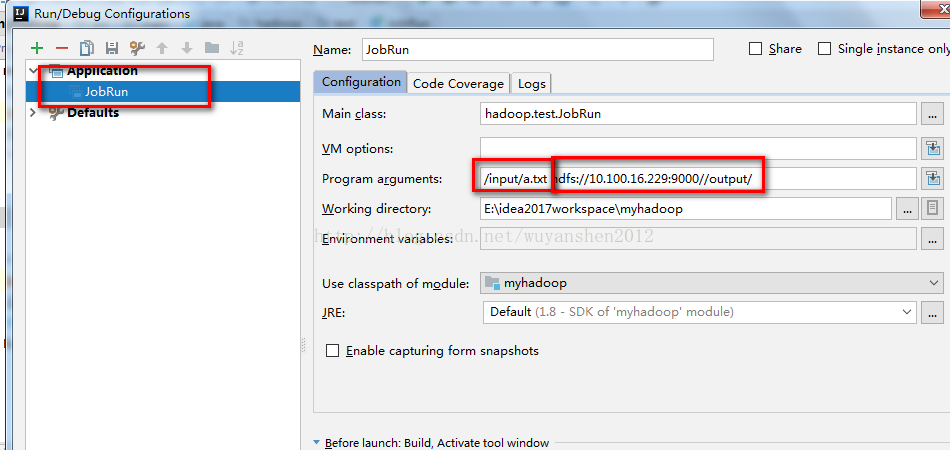
4.配置运行参数
我们可以直接在JobRun.java右键运行,但是还少两个参数,一个是输入路径,一个是输出路径,下面Program arguments中的第一个是输入路径,第二个是输出路径。
注意:1.这两个路径中间要用空格隔开!
2.这两个路径都是你hadoop上hdfs文件系统中的路径,不是你win7本地的路径!
3.输入路径的a.txt是你要处理的文件,需要自己新建:hadoop fs -mkdir /input hadoop fs -put ./a.txt /input
我的a.txt的内容是:
speak good cloud speek good good cloud speak english
EOF
运行结果就是统计每个单词出现了几次
5.运行
看到下面的输出,我们就成功远程到了linux上的hadoop并执行了wordCount程序!

我们到linux控制台查看运行结果:
可以看到有了output文件夹(input是我们自己建的)
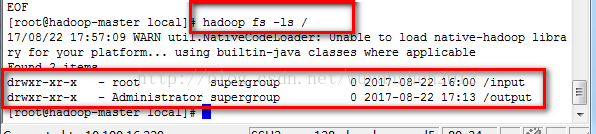
我们可以用
hadoop fs -ls /output
继续查看,看到有两个文件,part-r-00000就是运行的结果!

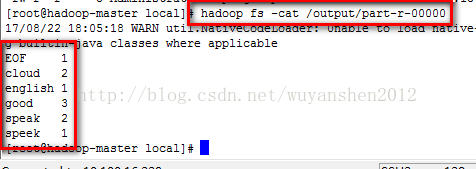
我们用
hadoop fs -cat /output/part-r-00000
查看执行结果
温馨提醒:为了以防空指针等一些莫名其妙的的错误在此处需要把你的hadoop的配置文件里面的core-site.xml、hdfs-site.xml和log4j.properties复制过来放在你的 src目录下。然后在开始运行你的程序了。在此处我们准备做测试的文件放在集群根目录下的data下。所需需要在你的hdfs文件系统的根目录创建data文件夹,并上传你要的测试文件。
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=Administrator, access=WRITE, inode="/":root:supergroup:drwxr-xr报错
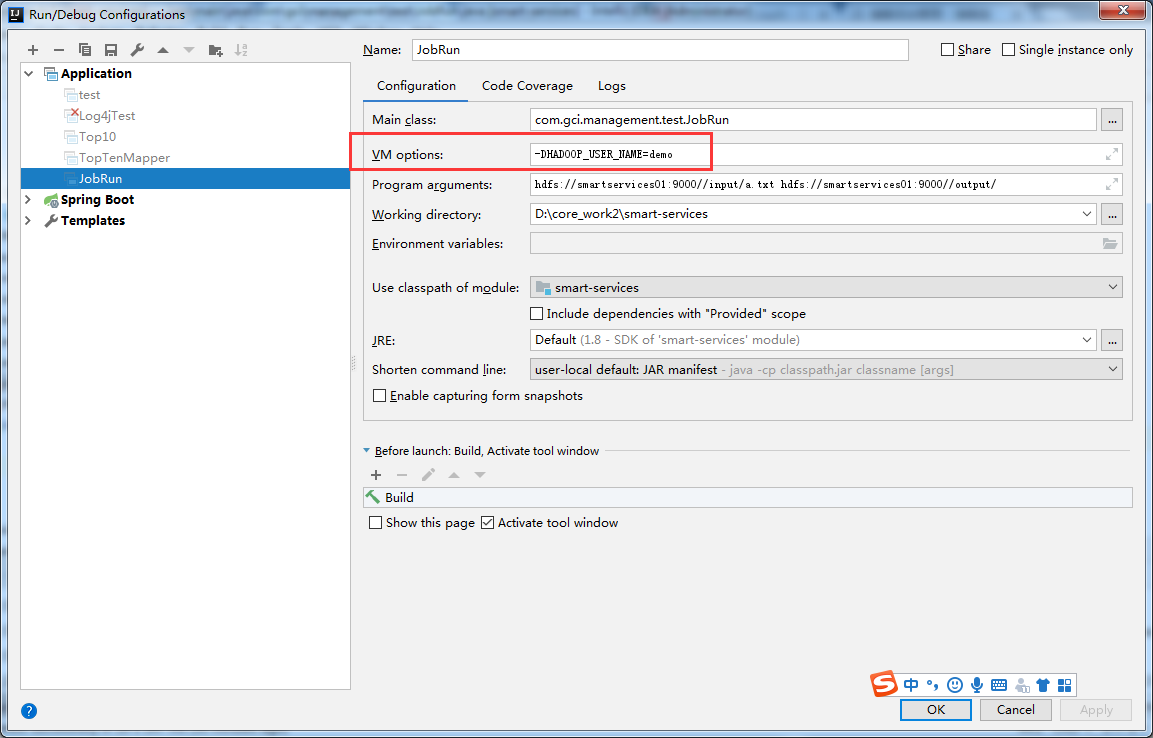
至此,我们成功在win7下远程调用linux的hadoop-2.6.1运行了wordCount程序!
---------------------
作者:龙丿一
来源:CSDN
原文:https://blog.csdn.net/wuyanshen2012/article/details/77482892
版权声明:本文为博主原创文章,转载请附上博文链接!
win7下idea远程连接hadoop,运行wordCount的更多相关文章
- windows下eclipse远程连接hadoop错误“Exception in thread"main"java.io.IOException: Call to Master.Hadoop/172.20.145.22:9000 failed ”
在VMware虚拟机下搭建了hadoop集群,ubuntu-12.04,一台master,三台slave.hadoop-0.20.2版本.在 master机器上利用eclipse-3.3连接hadoo ...
- windows下eclipse远程连接hadoop集群开发mapreduce
转载请注明出处,谢谢 2017-10-22 17:14:09 之前都是用python开发maprduce程序的,今天试了在windows下通过eclipse java开发,在开发前先搭建开发环境.在 ...
- Eclipse远程连接Hadoop
Windows下面调试程序比在Linux下面调试方便一些,于是用Windows下的Eclipse远程连接Hadoop. 1. 下载相应版本的hadoop-eclipse-plugin插件,复制到ecl ...
- IDEA远程连接Hadoop
IDEA远程连接Hadoop Win 1.Hadoop配置 下载并配置到本地环境 HADOOP_HOME D:\Tools\hadoop-2.7.7\hadoop-2.7.7 HADOOP_PREFI ...
- C# WinForm判断Win7下是否是管理员身份运行
原文:C# WinForm判断Win7下是否是管理员身份运行 如果程序不是以管理员身份运行,操作本地文件会提示:System.UnauthorizedAccessException异常 Vista 和 ...
- MySQL可以通过phpmyadmin连接,但是无法通过SqlYog(Windows)或Sequel Pro(Mac)下进行远程连接
更改数据库密码: update user set password=passworD("sunjingyu0509!") where user='root'; flush priv ...
- redis在Linux下的远程连接
1.redis在Linux下的远程连接: $ redis-cli -h host -p port -a password 如何连接到主机为 127.0.0.1,端口为 6379 ,密码为 mypass ...
- [Linux][Hadoop] 运行WordCount例子
紧接上篇,完成Hadoop的安装并跑起来之后,是该运行相关例子的时候了,而最简单最直接的例子就是HelloWorld式的WordCount例子. 参照博客进行运行:http://xiejiangl ...
- win7下用SSH连接linux虚拟机
本文来自转载:原文 [需求] 在win7环境下用SSH(SecureShell)连接本地的一台虚拟机上ubuntu(11.10)系统 [环境] win7,ubuntu,vmware(8.0) [方案 ...
随机推荐
- Selenium 入门到精通系列:五
Selenium 入门到精通系列 PS:显式等待.隐式等待.强制等待方法 例子 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2019 ...
- Android 简介
一 Android起源 android: 机器人 android是google公司开发的基于Linux2.6的免费开源操作系统 2005 Google收购 Android Inc. 开始 Dalvik ...
- wordlist 4
wordlist 4 desolate 啥啥啥lete adj. 荒凉的:无人烟的 repression depression n. 抑制,[心理] 压抑:镇压 / n. 沮丧:忧愁:抑郁症: spe ...
- ## 在webapp上使用input:file, 指定capture属性调用默认相机,摄像,录音功能
在iOS6下开发webapp,使用inputz之file,很有用 <input type="file" accept="image/*" capture= ...
- 【QT】常用类
官方文档 doc QWidget QWidget类是所有用户界面对象的基类. 窗口部件是用户界面的一个基本单元:它从窗口系统接收鼠标.键盘和其它事件,并且在屏幕上绘制自己. 每一个窗口部件都是矩形的, ...
- 函数重载(overload)和函数重写(override)
1. 前言: 在C++中有两个非常容易混淆的概念,分别是函数重载(overload)和函数重写(overwirte).虽然只相差一个字,但是它们两者之间的差别还是非常巨大的. 而通过深入了解这两个概念 ...
- ubuntu ssh配置
Secure Shell (SSH) is a cryptographic network protocol for operating network services securely over ...
- nginx web服务器的安装使用
nginx是一个web服务器(高性能web服务器),类似于apache服务器和iis服务器,由于nginx服务器具有轻量级高并发的特点,目前nginx的使用已经超越了apache. nginx介绍:n ...
- vue学习笔记(五):对于vuex的理解 + 简单实例
优点:通过定义和隔离状态管理中的各种概念并强制遵守一定的规则,我们的代码将会变得更结构化且易维护.使用vuex来引入外部状态管理,将业务逻辑切分到组件外,可以避免重复的从服务端抓取数据. 详情请参考官 ...
- VUE中组件的使用
关于vue组件引用 使用Nodejs的方法 被引用的组件要暴露 module.exports={}; 引用时 用 var abc= require("组件的路径") 然后 就可以用 ...