在Caffe中使用 DIGITS(Deep Learning GPU Training System)自定义Python层
注意:包含Python层的网络只支持单个GPU训练!!!!!
Caffe 使得我们有了使用Python自定义层的能力,而不是通常的C++/CUDA。这是一个非常有用的特性,但它的文档记录不足,难以正确实现本演练将向您展示如何使用DIGHT来学习实现Python层。
注意:这个特性(自定义python层)在你是使用Cmake编译Caffe或者使用Deb 包来安装Caffe的时候自动被包含。如果你使用Make,你将需要将你的Makefile.config中的"WITH_PYTHON_LAYER := 1"解注释来启用它。
给MNIST添加遮挡
对于这个例子,我们将在MNIST数据集上训练LeNet,但是我们将建立一个python层,来实现在图片喂进网络之前,截取掉它的四分之一。这模拟遮挡的数据,这样将会训练出一个对遮挡更加鲁棒的模型。
比如 变成
变成
创建数据集
首先,仿照这个教程(https://github.com/NVIDIA/DIGITS/blob/master/docs/GettingStarted.md#creating-a-dataset)来使用DIGITS创建MNIST数据集(假设你还没有创建)
创建Python文件
接下来你将创建一个包含你的Pyhon层定义的Python文件。打开一个文本编辑器,然后创建一个包含如下内容的文件。
import caffe
import random class BlankSquareLayer(caffe.Layer): def setup(self, bottom, top):
assert len(bottom) == 1, 'requires a single layer.bottom'
assert bottom[0].data.ndim >= 3, 'requires image data'
assert len(top) == 1, 'requires a single layer.top' def reshape(self, bottom, top):
# Copy shape from bottom
top[0].reshape(*bottom[0].data.shape) def forward(self, bottom, top):
# Copy all of the data
top[0].data[...] = bottom[0].data[...]
# Then zero-out one fourth of the image
height = top[0].data.shape[-2]
width = top[0].data.shape[-1]
h_offset = random.randrange(height/2)
w_offset = random.randrange(width/2)
top[0].data[...,
h_offset:(h_offset + height/2),
w_offset:(w_offset + width/2),
] = 0 def backward(self, top, propagate_down, bottom):
pass
其中,top和bottom是包含一个或者多个blob的列表或者数组,访问其中的每一个blob使用下标index,如top[index],访问其中的数据使用top[index].data,也就是一个四维向量[N,C,H,W]。
创建一个模型
注意:如果你以前没有使用DIGITS创建一个模型,在创建之前,你可以参照教程(https://github.com/NVIDIA/DIGITS/blob/master/docs/GettingStarted.md#training-a-model)学习。
- 点击主页上的
New Model > Images > Classification。 - 从数据集列表中选择MNIST数据集。
- 单击“
Use client side file”,并选择先前创建的Python文件。 - 点击
LeNetunderStandard Networks > Caffe。 - 点击右边显示的
Customize链接。
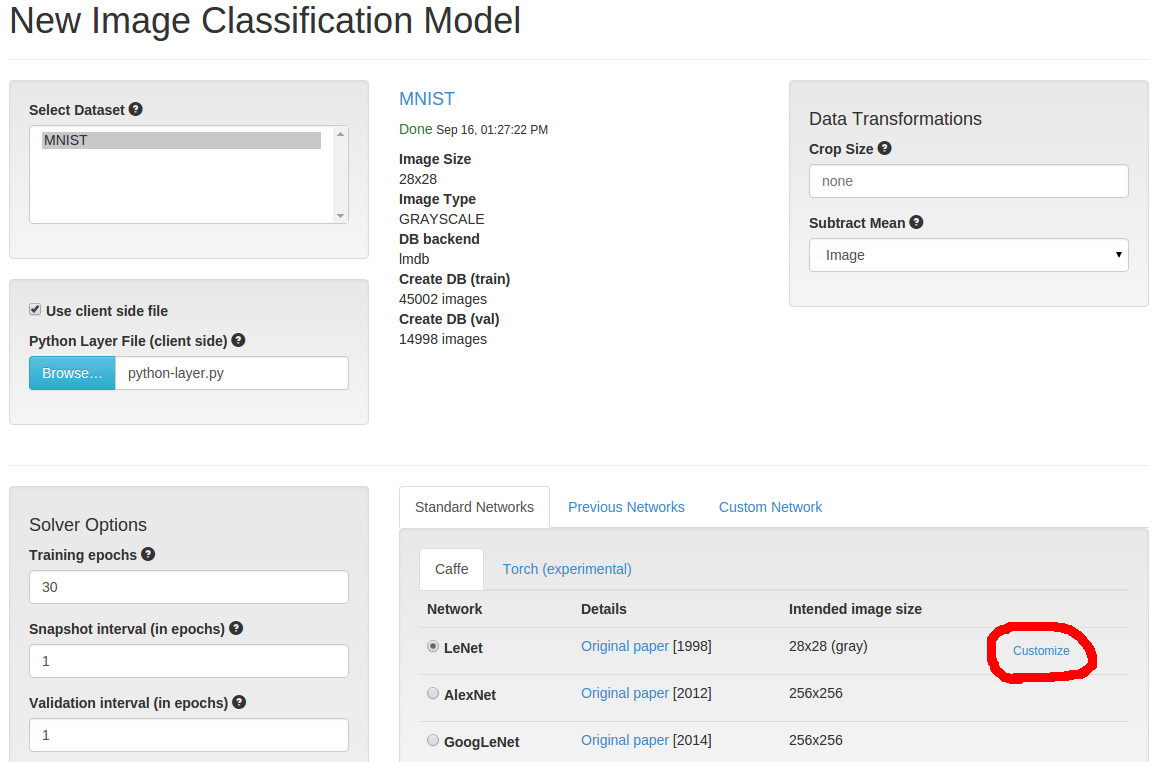
这将把我们带到一个窗口,我们可以自定义LeNet来添加自定义的Python层。我们将在scale层和conv层之间插入我们的层。找到这些层(从顶部的几行),并插入这段prototxt代码的片段:
layer {
name: "blank_square"
type: "Python"
bottom: "scaled"
top: "scaled"
python_param {
module: "digits_python_layers"
layer: "BlankSquareLayer"
}
}
当你点击Visualize,你将看到如下图:
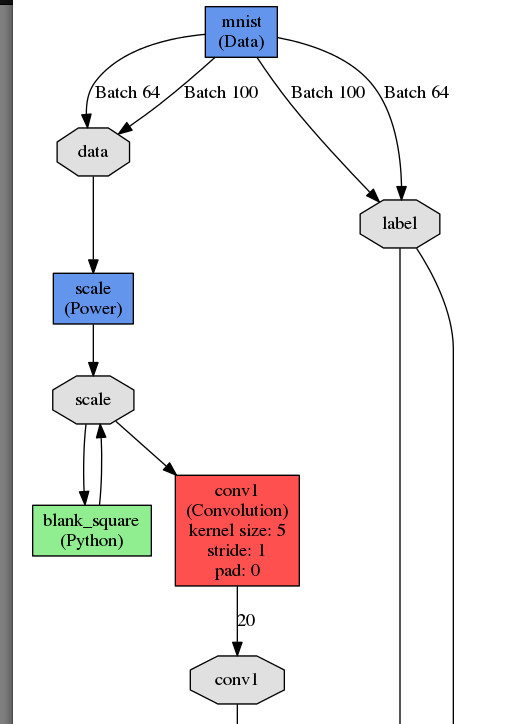
然后给模型一个名字,点击Create。你将会看到模型训练会话开始。如果你注意,你你将会发现这个模型会比默认的LeNet网络精度低,这是为什么呢?
注意:当前的caffe版本不支持在有Python层的网络上使用多GPU。如果你向使用Python层,那么你需要使用但GPU来训练。详见:https://github.com/BVLC/caffe/issues/2936
测试模型
现在开始比较有趣的部分。在MNIST测试集中选择一张图片,然后将它上传到 Test a single image(在页面的底下)
然后点击Show visualizations 和 statistics! 原始的图片将显示在左上,然后是它的预测类型。在Visualization 列,你会看到减去均值的图像作为数据激活的结果。
就在它下面,你会看到将图像从[0~255 ]缩小到[-1~1 ]的结果。你也会看到一个随机的四分之一的图像已经被删除-这是得益于我们的Python层!
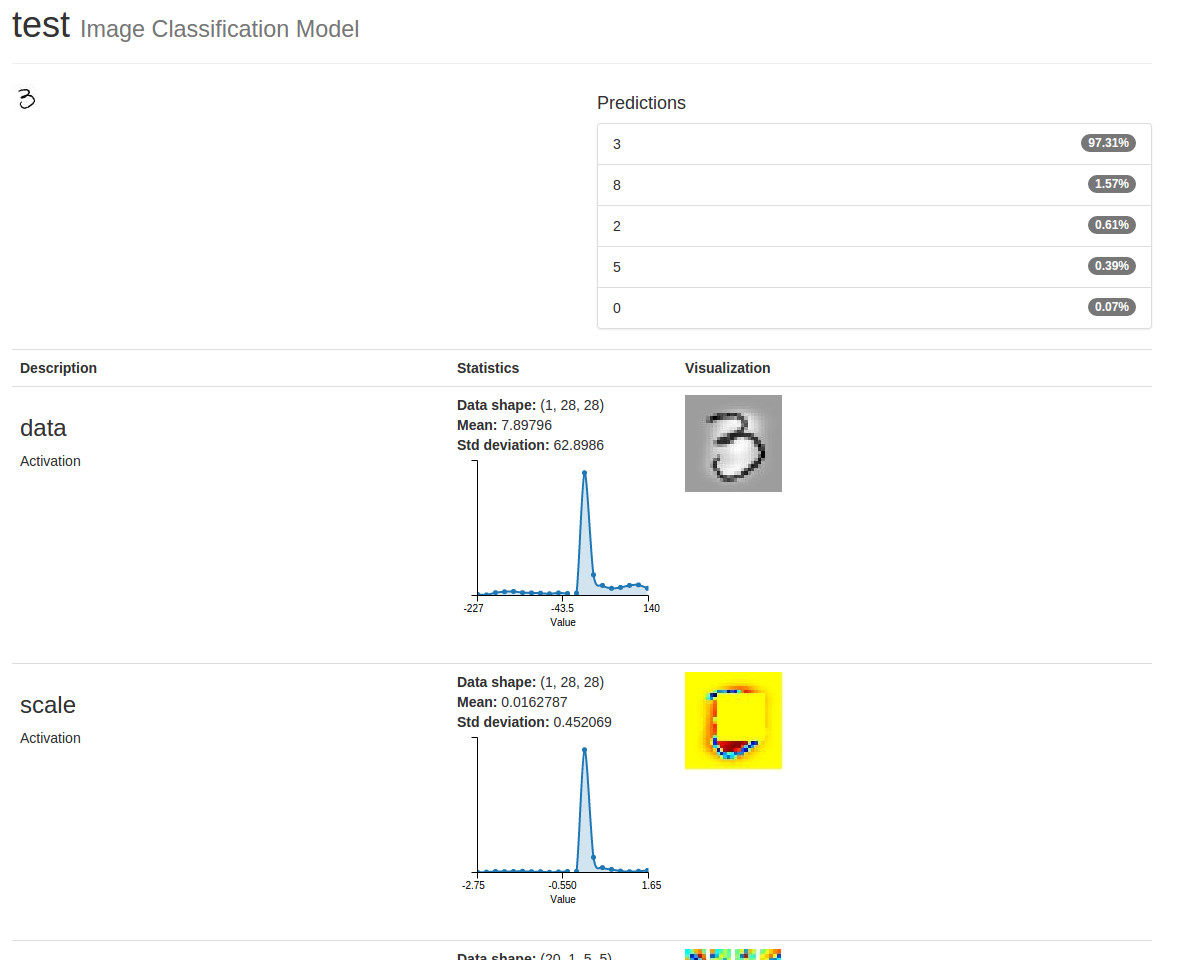
注意:第二个激活显示为彩色热图,即使底层数据仍然是单通道的,并且可以显示为灰度图像。“数据”激活被视为一种特殊情况,所有其他激活都被转换为热图。
在Caffe中使用 DIGITS(Deep Learning GPU Training System)自定义Python层的更多相关文章
- TVM优化Deep Learning GPU算子
TVM优化Deep Learning GPU算子 高效的深度学习算子是深度学习系统的核心.通常,这些算子很难优化,需要HPC专家付出巨大的努力. 端到端张量IR / DSL堆栈TVM使这一过程变得更加 ...
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- caffe: test code for Deep Learning approach
#include <stdio.h> // for snprintf #include <string> #include <vector> #include &q ...
- 吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第三周:浅层神经网络(Shallow neural networks) -课程笔记
第三周:浅层神经网络(Shallow neural networks) 3.1 神经网络概述(Neural Network Overview) 使用符号$ ^{[
- Top Deep Learning Projects in github
Top Deep Learning Projects A list of popular github projects related to deep learning (ranked by sta ...
- Deep Learning(深度学习)学习笔记整理
申明:本文非笔者原创,原文转载自:http://www.sigvc.org/bbs/thread-2187-1-3.html 4.2.初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎样的表 ...
- 【转载】Deep Learning(深度学习)学习笔记整理
http://blog.csdn.net/zouxy09/article/details/8775360 一.概述 Artificial Intelligence,也就是人工智能,就像长生不老和星际漫 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- P4035 [JSOI2008]球形空间产生器
题目描述 有一个球形空间产生器能够在 nn 维空间中产生一个坚硬的球体.现在,你被困在了这个 nn 维球体中,你只知道球面上 n+1n+1 个点的坐标,你需要以最快的速度确定这个 nn 维球体的球心坐 ...
- 2018牛客多校第四场 J.Hash Function
题意: 给出一个已知的哈希表.求字典序最小的插入序列,哈希表不合法则输出-1. 题解: 对于哈希表的每一个不为-1的数,假如他的位置是t,令s = a[t]%n.则这个数可以被插入当且仅当第s ~ t ...
- cgroups 命令集
cgroups 命令集 最后介绍,功能最为强大的控制组(cgroups)的用法.cgroups 是 Linux 内核提供的一种机制,利用它可以指定一组进程的资源分配. 具体来说,使用 cgroups, ...
- cmder 添加到右键菜单
管理员权限打开cmde 输入: cmder /register all 回车,OK
- [zabbix]zabbix分区表操作步骤
Q&A: 1.mul key: . 如果Key是空的, 那么该列值的可以重复, 表示该列没有索引, 或者是一个非唯一的复合索引的非前导列 . 如果Key是PRI, 那么该列是主键的组成部分 . ...
- HDU 1074状压DP
Doing Homework Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...
- mysql concat update中拼接字符串
mysql> select id,avatar from tf_user; +----+--------------+ | id | avatar | +----+--------------+ ...
- Nginx简介及使用Nginx实现负载均衡的原理【通俗易懂,言简意赅】【转】
Nginx 这个轻量级.高性能的 web server 主要可以干两件事情: 直接作为http server(代替apache,对PHP需要FastCGI处理器支持): 另外一个功能就是作为反向代理服 ...
- 南阳ACM 题目275:队花的烦恼一 Java版
队花的烦恼一 时间限制:3000 ms | 内存限制:65535 KB 难度:1 描述 ACM队的队花C小+经常抱怨:"C语言中的格式输出中有十六.十.八进制输出,然而却没有二进制输出, ...
- 在MVC5中使用Ninject 依赖注入
各大主流.Net的IOC框架性能测试比较 : http://www.cnblogs.com/liping13599168/archive/2011/07/17/2108734.html 使用NuGet ...