Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客
Spark standalone简介与运行wordcount(master、slave1和slave2)
开篇要明白
(1)spark-env.sh 是环境变量配置文件
(2)spark-defaults.conf
(3)slaves 是从节点机器配置文件
(4)metrics.properties 是 监控
(5)log4j.properties 是配置日志
(5)fairscheduler.xml是公平调度
(6)docker.properties 是 docker
(7)我这里的Spark standalone模式的安装,是master、slave1和slave2。
(8)Spark standalone模式的安装,其实,是可以不需安装hadoop的。(我这里是没有安装hadoop了,看到有些人写博客也没安装,也有安装的)
(9)为了管理,安装zookeeper,(即管理master、slave1和slave2)
首先,说下我这篇博客的Spark standalone模式的安装情况
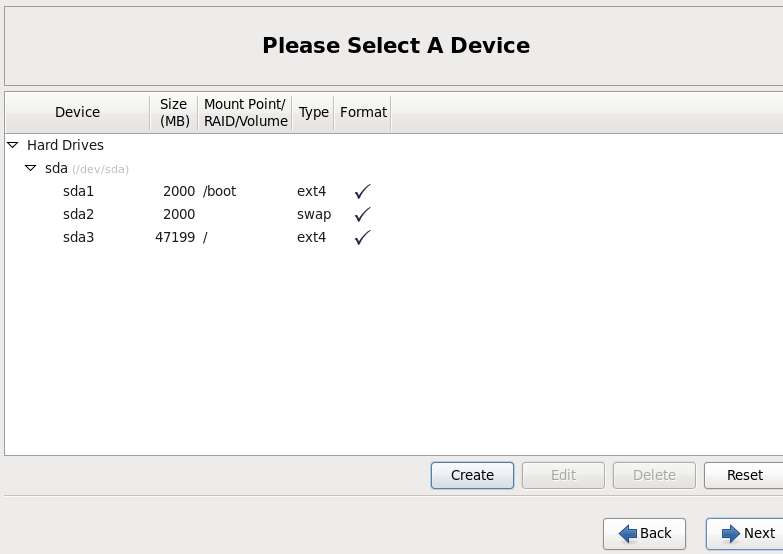
我的安装分区如下,四台都一样。
关于如何关闭防火墙
我这里不多说,请移步
hadoop 50070 无法访问问题解决汇总
关于如何配置静态ip和联网
我这里不多说,我的是如下,请移步
CentOS 6.5静态IP的设置(NAT和桥接联网方式都适用)
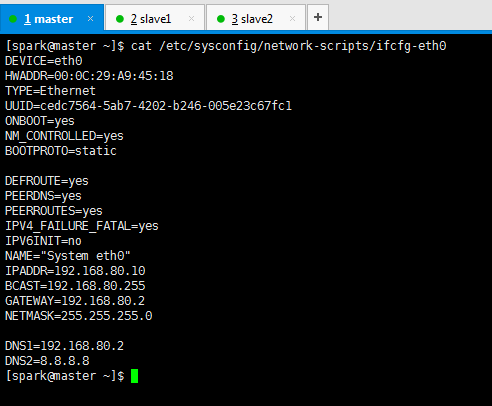
DEVICE=eth0
HWADDR=00:0C:29:A9:45:18
TYPE=Ethernet
UUID=50fc177a-f282-4c83-bfbc-cb0f00b92507
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0" IPADDR=192.168.80.10
BCAST=192.168.80.255
GATEWAY=192.168.80.2
NETMASK=255.255.255.0 DNS1=192.168.80.2
DNS2=8.8.8.8

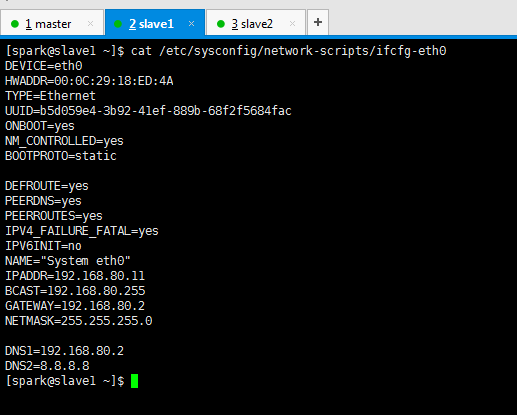
DEVICE=eth0
HWADDR=00:0C:29:18:ED:4A
TYPE=Ethernet
UUID=b5d059e4-3b92-41ef-889b-68f2f5684fac
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
IPADDR=192.168.80.11
BCAST=192.168.80.255
GATEWAY=192.168.80.2
NETMASK=255.255.255.0 DNS1=192.168.80.2
DNS2=8.8.8.8
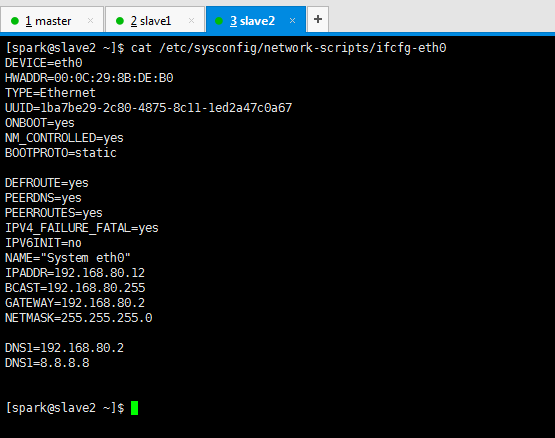
DEVICE=eth0
HWADDR=00:0C:29:8B:DE:B0
TYPE=Ethernet
UUID=1ba7be29-2c80-4875-8c11-1ed2a47c0a67
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
IPADDR=192.168.80.12
BCAST=192.168.80.255
GATEWAY=192.168.80.2
NETMASK=255.255.255.0 DNS1=192.168.80.2
DNS1=8.8.8.8
关于新建用户组和用户
我这里不多说,我是spark,请移步
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
关于安装ssh、机器本身、机器之间进行免密码通信和时间同步
我这里不多说,具体,请移步。在这一步,本人深有感受,有经验。最好建议拍快照。否则很容易出错!
机器本身,即master与master、slave1与slave1、slave2与slave2。
机器之间,即master与slave1、master与slave2。
slave1与slave2。
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz 的集群搭建(3节点和5节点皆适用)
关于如何先卸载自带的openjdk,再安装
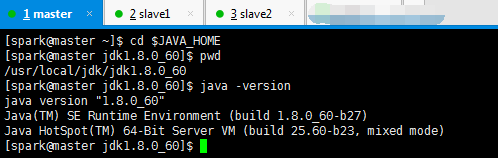
我这里不多说,我是jdk-8u60-linux-x64.tar.gz,请移步
我的jdk是安装在/usr/local/jdk下,记得赋予权限组,chown -R spark:spark jdk
Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置
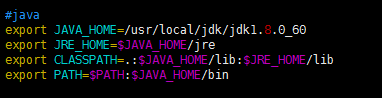
#java
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
关于如何安装scala
不多说,我这里是scala-2.10.5.tgz,请移步
我的scala安装在/usr/local/scala,记得赋予用户组,chown -R spark:spark scala
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的集群搭建(单节点)(CentOS系统)

#scala
export SCALA_HOME=/usr/local/scala/scala-2.10.5
export PATH=$PATH:$SCALA_HOME/bin
关于如何安装spark
我这里不多说,请移步见
我的spark安装目录是在/usr/local/spark/,记得赋予用户组,chown -R spark:spark sparl
只需去下面的博客,去看如何安装就好,至于spark的怎么配置。请见下面的spark standalone模式的配置文件讲解。
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的集群搭建(单节点)(CentOS系统)

#spark
export SPARK_HOME=/usr/local/spark/spark-1.6.1-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
关于zookeeper的安装
我这里不多说,请移步
hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建(含zookeeper集群安装)
以及,之后,在spark 里怎么配置zookeeper。
Spark standalone简介与运行wordcount(master、slave1和slave2)
这里,我带大家来看官网
http://spark.apache.org/docs/latest
http://spark.apache.org/docs/latest/spark-standalone.html
http://spark.apache.org/docs/latest/spark-standalone.html#starting-a-cluster-manually
Spark Standalone部署配置---通过脚本启动集群
修改如下配置:
● slaves--指定在哪些节点上运行worker。
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# # A Spark Worker will be started on each of the machines listed below.
slave1
slave2
● spark-defaults.conf---spark提交job时的默认配置
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# # Default system properties included when running spark-submit.
# This is useful for setting default environmental settings. # Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
大家,可以在这个配置文件里指定好,以后每次不需在命令行下指定了。当然咯,也可以不配置啦!(我一般是这里不配置,即这个文件不动它)
spark-defaults.conf (这个作为可选可不选)(是因为或者是在spark-submit里也是可以加入的)(一般不选,不然固定死了)(我一般是这里不配置,即这个文件不动它)
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/sparkHistoryLogs
spark.eventLog.compress true
spark.history.fs.update.interval 5
spark.history.ui.port 7777
spark.history.fs.logDirectory hdfs://master:9000/sparkHistoryLogs
● spark-env.sh—spark的环境变量
#!/usr/bin/env bash #
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# # This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site. # Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# - SPARK_CLASSPATH, default classpath entries to append # Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_CLASSPATH, default classpath entries to append
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos # Options read in YARN client mode
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_EXECUTOR_INSTANCES, Number of executors to start (Default: 2)
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_YARN_APP_NAME, The name of your application (Default: Spark)
# - SPARK_YARN_QUEUE, The hadoop queue to use for allocation requests (Default: ‘default’)
# - SPARK_YARN_DIST_FILES, Comma separated list of files to be distributed with the job.
# - SPARK_YARN_DIST_ARCHIVES, Comma separated list of archives to be distributed with the job. # Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_IP, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_INSTANCES, to set the number of worker processes per node
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers # Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0) export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export SCALA_HOME=/usr/local/scala/scala-2.10.5 export SPARK_MASTER_IP=192.168.80.10
export SPARK_WORKER_MERMORY=1G (官网上说是1g)
# SPARK_MASTER_WEBUI_PORT=8888 (这里自行可以去修改,我这里不做演示) 注意:SPARK_MASTER_PORT默认是8080,SPARK_MASTER_WEBUI_PORT默认是7077
因为,我说了,我的这篇博文定位是对spark的standalone模式的安装,所以,它是可以不用安装hadoop的,所以这里就不需配置hadoop了。
你们大家若有看到这里要配置,比如HADOOP_HOME和HADOOP_CONF_DIR等。那是spark的yarn模式的安装。!!!(注意)
● 在打算作为master的节点上启动集群—sbin/start-all.sh

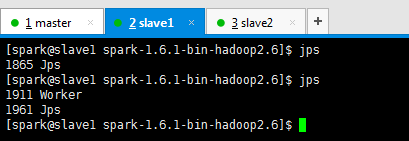
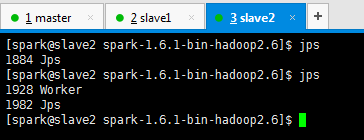
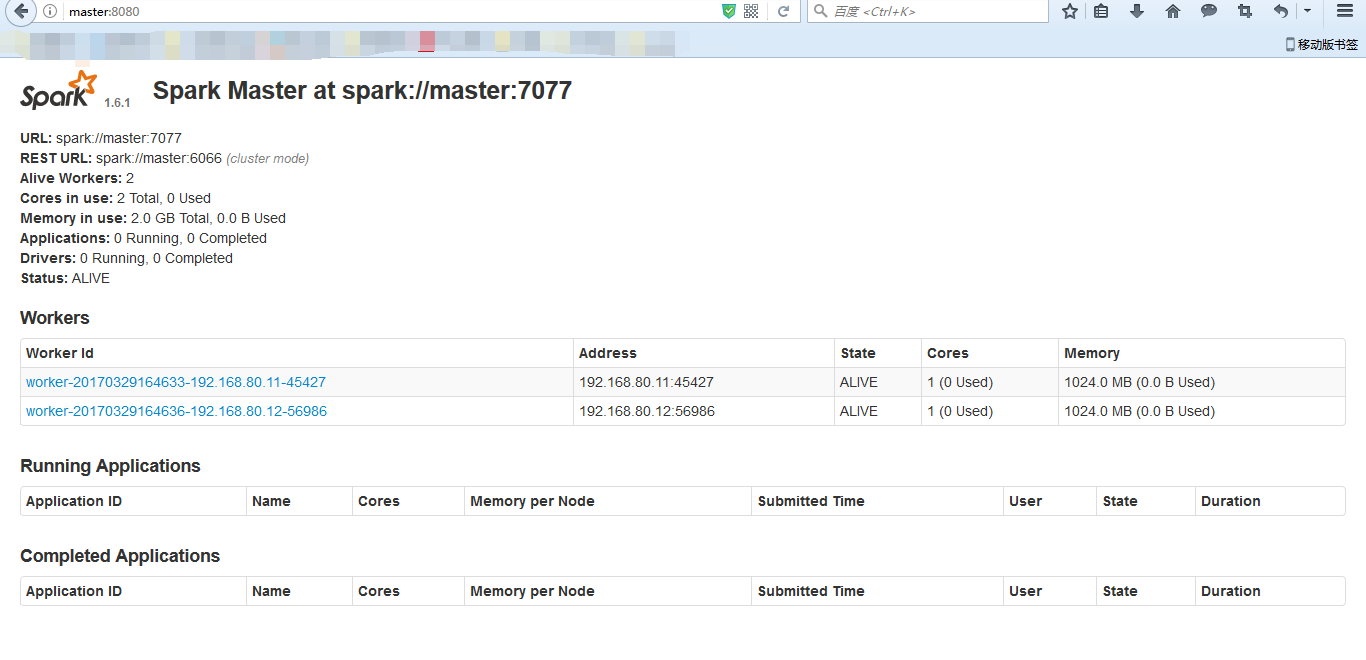
Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)的更多相关文章
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- [会装]Spark standalone 模式的安装
1. 简介 以standalone模式安装spark集群bin运行demo. 2.环境和介质准备 2.1 下载spark介质,根据现有hadoop的版本选择下载,我目前的环境中的hadoop版本是2. ...
- 【原】Spark Standalone模式
Spark Standalone模式 安装Spark Standalone集群 手动启动集群 集群创建脚本 提交应用到集群 创建Spark应用 资源调度及分配 监控与日志 与Hadoop共存 配置网络 ...
- Spark Standalone模式应用程序开发
作者:过往记忆 | 新浪微博:左手牵右手TEL | 能够转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明博客地址:http://www.iteblog.com/文章标题:<Spar ...
- 关于spark standalone模式下的executor问题
1.spark standalone模式下,worker与executor是一一对应的. 2.如果想要多个worker,那么需要修改spark-env的SPARK_WORKER_INSTANCES为2 ...
- Spark Standalone模式HA环境搭建
Spark Standalone模式常见的HA部署方式有两种:基于文件系统的HA和基于ZK的HA 本篇只介绍基于ZK的HA环境搭建: $SPARK_HOME/conf/spark-env.sh 添加S ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark standalone模式单节点启动多个executor
以前为了在一台机器上启动多个executor都是通过instance多个worker来实现的,因为standalone模式默认在一台worker上启动一个executor,造成了很大的不便利,并且会造 ...
- Spark Standalone模式伪分布式环境搭建
前提:安装好jdk1.7,hadoop 安装步骤: 1.安装scala 下载地址:http://www.scala-lang.org/download/ 配置环境变量: export SCALA_HO ...
随机推荐
- Python相关基础
1>变量: 2>条件判断与缩进: sex = raw_input("Please input your gender:") if sex == "girl&q ...
- Apache Shiro 10分钟之旅!
欢迎来到Apache Shiro 10分钟之旅! 希望通过这个简单.快速的示例,可以让你对应用程序中使用Shiro有个深入的了解.嗯,10分钟你应该可以搞定它. 概述 Apache Shiro是什么? ...
- Oracle定時email通知
small_program_task 這張表的資料是待發送的email通知,再次之前已經有一個job會定時掃描固定時間內未接收到小程式回報狀態將其寫入到該表,send_flag為N,表示為寄過通知.e ...
- centos6和7的防火墙开关
CentOS6.5查看防火墙的状态: 1 [linuxidc@localhost ~]$service iptable status 显示结果: 1 2 3 4 5 [linuxidc@localho ...
- 张小龙演讲PPT
35条核心要点 一.产品经理要求 1.了解人性 2.了解群体心理 3.产品经理像上帝一样,可建造系统,制定规则,让群体在系统中演化 4.提高自己的艺术品位.质量要求品位/细节体验品位:作品而非产品:工 ...
- leecode刷题(10)-- 旋转图像
leecode刷题(10)-- 旋转图像 旋转图像 描述: 给定一个 n × n 的二维矩阵表示一个图像. 将图像顺时针旋转 90 度. 说明: 你必须在原地旋转图像,这意味着你需要直接修改输入的二维 ...
- QTREE5 - Query on a tree V(LCT)
题意翻译 你被给定一棵n个点的树,点从1到n编号.每个点可能有两种颜色:黑或白.我们定义dist(a,b)为点a至点b路径上的边个数. 一开始所有的点都是黑色的. 要求作以下操作: 0 i 将点i的颜 ...
- 2017qcon大会的一点想法(安全人才如何不被淘汰?)
2017 qcon 上海专门设立了“直击黑产,业务安全的攻与防”专题,通过这次专题的了解和学习,让我对黑产的攻防有了更深入认识. 1. 安全防护趋势 2017 qcon 上海专门设立了“直击黑产,业务 ...
- centos6安装mysql5.7
RPM包安装与卸载mysql 建议:装完mysql后立刻创建一个密码,不然下次登录的时候会有问题.原因是mysql 5.7会自动创建一个临时密码,过期失效,可以到grep "password ...
- Windows下Jmeter安装出现Not able to find Java executable or version问题解决方案
安装好java1.8.jmeter4.0,并java -version正常,jmeter也能正常使用.某一次使用突然出现Not able to find Java executable or vers ...