Keras GRU 文字识别
GRU(Gated Recurrent Unit)是LSTM的一个变体,也能克服RNN无法很好处理远距离依赖的问题。
GRU的结构跟LSTM类似,不过增加了让三个门层也接收细胞状态的输入,是常用的LSTM变体之一。
LSTM核心模块:
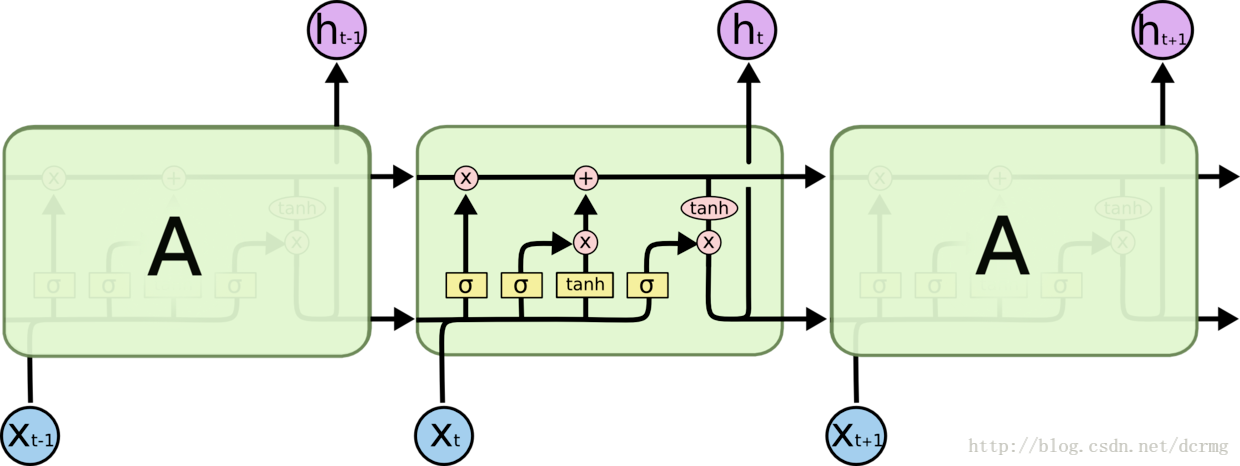
这一核心模块在GRU中变为:
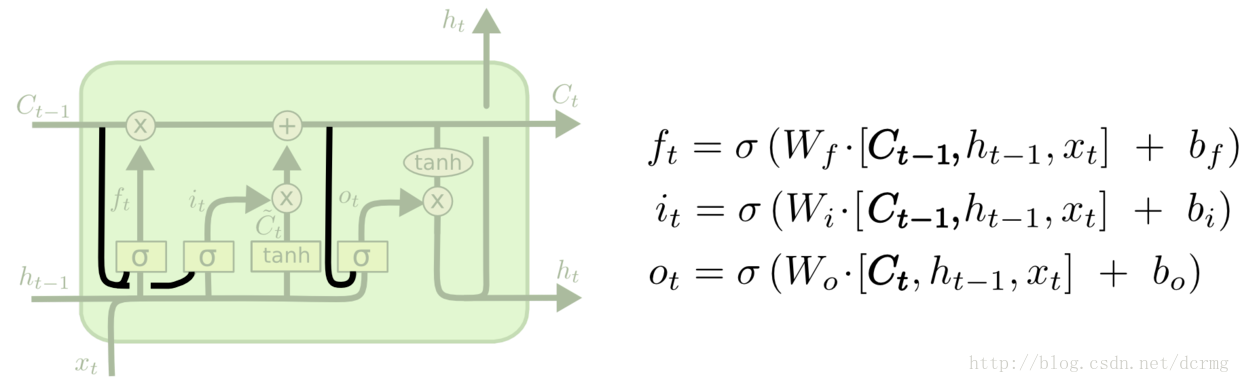
CTC网络结构定义:
def get_model(height,nclass):
input = Input(shape=(height,None,1),name='the_input')
m = Conv2D(64,kernel_size=(3,3),activation='relu',padding='same',name='conv1')(input)
m = MaxPooling2D(pool_size=(2,2),strides=(2,2),name='pool1')(m)
m = Conv2D(128,kernel_size=(3,3),activation='relu',padding='same',name='conv2')(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,2),name='pool2')(m)
m = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same',name='conv3')(m)
m = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same',name='conv4')(m)
m = ZeroPadding2D(padding=(0,1))(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,1),padding='valid',name='pool3')(m)
m = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same',name='conv5')(m)
m = BatchNormalization(axis=1)(m)
m = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same',name='conv6')(m)
m = BatchNormalization(axis=1)(m)
m = ZeroPadding2D(padding=(0,1))(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,1),padding='valid',name='pool4')(m)
m = Conv2D(512,kernel_size=(2,2),activation='relu',padding='valid',name='conv7')(m)
m = Permute((2,1,3),name='permute')(m)
m = TimeDistributed(Flatten(),name='timedistrib')(m)
m = Bidirectional(GRU(rnnunit,return_sequences=True),name='blstm1')(m)
m = Dense(rnnunit,name='blstm1_out',activation='linear')(m)
m = Bidirectional(GRU(rnnunit,return_sequences=True),name='blstm2')(m)
y_pred = Dense(nclass,name='blstm2_out',activation='softmax')(m)
basemodel = Model(inputs=input,outputs=y_pred)
labels = Input(name='the_labels', shape=[None,], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
model = Model(inputs=[input, labels, input_length, label_length], outputs=[loss_out])
sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)
#model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer='adadelta')
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
model.summary()
return model,basemodel____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
the_input (InputLayer) (None, 32, None, 1) 0
____________________________________________________________________________________________________
conv1 (Conv2D) (None, 32, None, 64) 640 the_input[0][0]
____________________________________________________________________________________________________
pool1 (MaxPooling2D) (None, 16, None, 64) 0 conv1[0][0]
____________________________________________________________________________________________________
conv2 (Conv2D) (None, 16, None, 128) 73856 pool1[0][0]
____________________________________________________________________________________________________
pool2 (MaxPooling2D) (None, 8, None, 128) 0 conv2[0][0]
____________________________________________________________________________________________________
conv3 (Conv2D) (None, 8, None, 256) 295168 pool2[0][0]
____________________________________________________________________________________________________
conv4 (Conv2D) (None, 8, None, 256) 590080 conv3[0][0]
____________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D) (None, 8, None, 256) 0 conv4[0][0]
____________________________________________________________________________________________________
pool3 (MaxPooling2D) (None, 4, None, 256) 0 zero_padding2d_1[0][0]
____________________________________________________________________________________________________
conv5 (Conv2D) (None, 4, None, 512) 1180160 pool3[0][0]
____________________________________________________________________________________________________
batch_normalization_1 (BatchNorm (None, 4, None, 512) 16 conv5[0][0]
____________________________________________________________________________________________________
conv6 (Conv2D) (None, 4, None, 512) 2359808 batch_normalization_1[0][0]
____________________________________________________________________________________________________
batch_normalization_2 (BatchNorm (None, 4, None, 512) 16 conv6[0][0]
____________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D) (None, 4, None, 512) 0 batch_normalization_2[0][0]
____________________________________________________________________________________________________
pool4 (MaxPooling2D) (None, 2, None, 512) 0 zero_padding2d_2[0][0]
____________________________________________________________________________________________________
conv7 (Conv2D) (None, 1, None, 512) 1049088 pool4[0][0]
____________________________________________________________________________________________________
permute (Permute) (None, None, 1, 512) 0 conv7[0][0]
____________________________________________________________________________________________________
timedistrib (TimeDistributed) (None, None, 512) 0 permute[0][0]
____________________________________________________________________________________________________
blstm1 (Bidirectional) (None, None, 512) 1181184 timedistrib[0][0]
____________________________________________________________________________________________________
blstm1_out (Dense) (None, None, 256) 131328 blstm1[0][0]
____________________________________________________________________________________________________
blstm2 (Bidirectional) (None, None, 512) 787968 blstm1_out[0][0]
____________________________________________________________________________________________________
blstm2_out (Dense) (None, None, 5531) 2837403 blstm2[0][0]
____________________________________________________________________________________________________
the_labels (InputLayer) (None, None) 0
____________________________________________________________________________________________________
input_length (InputLayer) (None, 1) 0
____________________________________________________________________________________________________
label_length (InputLayer) (None, 1) 0
____________________________________________________________________________________________________
ctc (Lambda) (None, 1) 0 blstm2_out[0][0]
the_labels[0][0]
input_length[0][0]
label_length[0][0]
====================================================================================================
Total params: 10,486,715
Trainable params: 10,486,699
模型: 模型包含5500个中文字符,包括常用汉字、大小写英文字符、标点符号、特殊符号(@、¥、&)等,可以在现有模型基础上继续训练。
训练: 样本保存在data文件夹下,使用LMDB格式; train.py是训练文件,可以选择保存模型权重或模型结构+模型权重,训练结果保存在models文件夹下。
测试: test.py是中文OCR测试文件
识别效果:
济南华富锻造有限公司

夺得铜牌后,福民爱流下了激动的泪水。“石川
Itturnedoutthat328girswerenamedAbcdeintheUnitedstates

工程(含训练模型)地址: http://download.csdn.net/download/dcrmg/10248818
Keras GRU 文字识别的更多相关文章
- 图像文字识别(OCR)用什么算法小结
说明:主要考虑深度学习的方法,传统的方法不在考虑范围之内. 1.文字识别步骤 1.1detection:找到有文字的区域(proposal). 1.2classification:识别区域中的文字. ...
- emgucv文字识别
今天讲如何通过emgucv中的函数来实现文字识别.总体的过程可以分为以下几步: 1.读取要识别的图片 2.对图片进行灰度变换 3.调用emgu.cv.ocr的类tessract中的recognize方 ...
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- 斯坦福第十八课:应用实例:图片文字识别(Application Example: Photo OCR)
18.1 问题描述和流程图 18.2 滑动窗口 18.3 获取大量数据和人工数据 18.4 上限分析:哪部分管道的接下去做 18.1 问题描述和流程图
- 怎么给OCR文字识别软件重编文档页面号码
ABBYY FineReader Pro for Mac OCR文字识别软件处理文档时,在FineReader文档中,页面的加载顺序即是页面的导入顺序,完成导入之后,文档的所有页面均会被编号,各编号会 ...
- 对OCR文字识别软件的扫描选项怎么设置
说到OCR文字识别软件,越来越多的人选择使用ABBYY FineReader识别和转换文档,然而并不是每个人都知道转换质量取决于源图像的质量和所选的扫描选项,今天就给大家普及一下这方面的知识. ABB ...
- 给OCR文字识别软件添加图像的方法
ABBYY FineReader 12是一款OCR图片文字识别软件,而且强大的它现在还可使用快速扫描窗口中的快速打开.扫描并保存为图像或任务自动化任务,在没有进行预处理和OCR的ABBYY FineR ...
- 怎么提高OCR文字识别软件的识别正确率
在OCR文字识别软件当中,ABBYY FineReader是比较好用的程序之一,但再好的识别软件也不能保证100%的识别正确率,用户都喜欢软件的正确率高一些,以减轻识别后修正的负担,很多用户也都提过这 ...
- OCR文字识别软件许可文件被误删了怎么办
使用任何一款软件,都会有误操作的情况发生,比如清理文件时一不小心删除了许可文件,对于ABBYY FineReader 12这样一款OCR文字识别软件,因失误错误删除了许可文件该怎么办呢?今天就来给大家 ...
随机推荐
- Linux开发工具教程
今天把上个星期写的Linux开发工具相关的教程整理一下,方便阅读: 1.第一课 GCC入门: 2.第二课 GCC入门之静态库以及共享库: 3.第三课 Makefile文件的制作(上) : 4.第四课 ...
- webservice -- cxf客户端调用axis2服务端
背景: 有个项目, 需要由第三方提供用户信息, 实现用户同步操作, 对方给提供webservice接口(axis2实现)并也使用axis2作主客户端调用我方提供的webservice接口 起初, 由于 ...
- Google ProtocolBuffer
https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/index.html 1. Protocol Buffers 简介 Protocol Buff ...
- module.exports和exports得区别
对module.exports和exports的一些理解 可能是有史以来最简单通俗易懂的有关Module.exports和exports区别的文章了. exports = module.exports ...
- Linux设备驱动程序加载/卸载方法 insmod和modprobe命令
linux加载/卸载驱动有两种方法. 1.modprobe 注:在使用这个命令加载模块前先使用depmod -a命令生成modules.dep文件,该文件位于/lib/modules/$(uname ...
- 【WIN7】windows\system32 下的几乎所有文件的简单说明【2】
1: System32的详解 C:\WINDOWS\system32... 2: 3: 这个 system32 文件夹中包含了大量的用于 Windows 的文件. 这里主要用于存储 DLL 文件, ...
- C++二阶构造函数
转自:http://blog.51cto.com/9291927/1896411 一.构造函数的问题 构造函数存在问题: A.构造函数只提供自动初始化成员变量的机会 B.不能保证初始化逻辑一定成功,如 ...
- LAMP脚本
A goal is a dream with a deadline. Much effort, much prosperity. 环境:CentOS release 6.5 2.6.32-431.e ...
- HTTP与抓包
HTTP就是超文本传输协议,底层使用socket TCP长连接,基于请求与响应,是同步请求. socket 绝对多数语言都是支持socket的,底层走的是二进制传输. HTTP协议实际上是对Socke ...
- Android -- UI布局管理,相对布局,线性布局,表格布局,绝对布局,帧布局
1. 相对布局 <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmln ...