scrapy框架解读--深入理解爬虫原理

scrapy框架结构图:
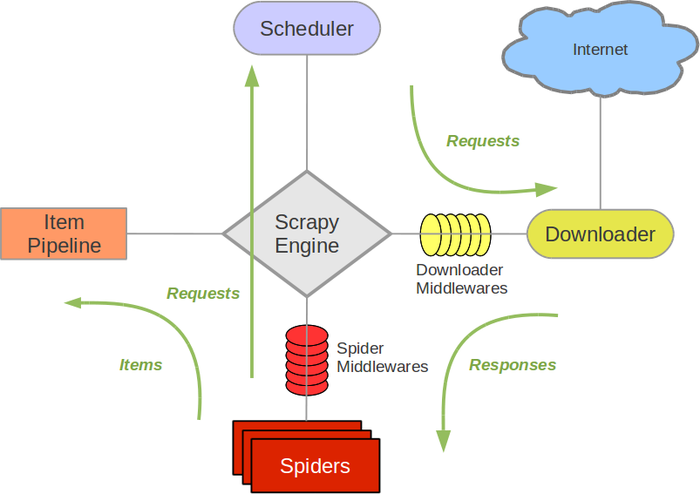
组成部分介绍:
Scrapy Engine:
负责组件之间数据的流转,当某个动作发生时触发事件Scheduler:
接收requests,并把他们入队,以便后续的调度Downloader:
负责抓取网页,并传送给引擎,之后抓取结果将传给spiderSpiders:
用户编写的可定制化的部分,负责解析response,产生items和URLItem Pipeline:
负责处理item,典型的用途:清洗、验证、持久化Downloader middlewares:
位于引擎和下载器之间的一个钩子,处理传送到下载器的requests和传送到引擎的response(若需要在Requests到达Downloader之前或者是responses到达spiders之前做一些预处理,可以使用该中间件来完成)Spider middlewares:
位于引擎和抓取器之间的一个钩子,处理抓取器的输入和输出
(在spiders产生的Items到达Item Pipeline之前做一些预处理或response到达spider之前做一些处理)
Scrapy中的数据流:
- Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的spider,并向该spider请求第一个要爬取的url(s);
- 引擎从spider中获取到第一个要爬取的url并在调度器(scheduler)以requests调度;
- 引擎向调度器请求下一个要爬取的url;
- 调度器返回下一个要爬取的url给引擎,引擎将url通过下载器中间件(请求requests方向)转发给下载器(Downloader);
- 一旦页面下载完毕,下载器生成一个该页面的responses,并将其通过下载器中间件(返回responses方向)发送给引擎;
- 引擎从下载器中接收到responses并通过spider中间件(输入方向)发送给spider处理;
- spider处理responses并返回爬取到的Item及(跟进的)新的resquests给引擎
- 引擎将(spider返回的)爬取到的Item给Item Pipeline,将(spider返回的)requests给调度器;
- (从第二部)重复直到(调度器中没有更多的request)引擎关闭该网站
中间件的编写:
down loader middle ware – 查看文档151页
spider middle wares – 查看文档162页
scrapy框架解读--深入理解爬虫原理的更多相关文章
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- Scrapy框架实战-妹子图爬虫
Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难.即便是在一些小型的项目上,用scrapy甚至比用requests.urllib.urllib2更方便,简单,效率也更高.废话不多说, ...
- Scrapy框架解读
1. Scrapy组件a. 主体部分i. 引擎(Scrapy):处理整个系统的数据流处理,触发事务(框架核心)ii. 调度器(Scheduler):1) 用来接受引擎发过来的请求, 压入队列中, 并在 ...
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 网络爬虫第五章之Scrapy框架
第一节:Scrapy框架架构 Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- python高级之scrapy框架
目录: 爬虫性能原理 scrapy框架解析 一.爬虫性能原理 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 1.同步执行 impor ...
- 都是干货---真正的了解scrapy框架
去重规则 在爬虫应用中,我们可以在request对象中设置参数dont_filter = True 来阻止去重.而scrapy框架中是默认去重的,那内部是如何去重的. from scrapy.dupe ...
随机推荐
- IO流入门-第十一章-PrintStream_PrintWriter
DataInputStream和DataOutputStream基本用法和方法示例 /* java.io.PrintStream:标准的输出流,默认打印到控制台,以字节方式 java.io.Print ...
- Centos 软链接命令(十)
链接命令:ln (link) ln -s [源文件] [目标文件] 功能描述:生成链接文件 选项: -s 创建软链接 硬链接特征: 1,拥有相同的i节点和存储block块,可以看作是同一个文件: 2 ...
- JVM的JIT机制
因为 JVM 的 JIT 机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译成为机器码从而提高执行速度.
- 从es中拉取全部数据/大量数据 使用scroll+scan避免深分页
es一次请求默认返回的数据条数是10条,可以通过设置size参数来控制返回数据的条数: 如果要返回很多数据,可以把size设置的很大,不过elastic search默认size最大不能超过1万. 那 ...
- windows下安装Composer提示缺少openssl的解决方法
在Windows环境下安装Composer(注:Composer要求PHP版本在5.3.2+),你可能会遇到这种安装失败的情况:出错信息是 "The openssl extension is ...
- 从库函数解析STM32地址映射
STM32的存储映射是靠基地址和地址偏移实现的. 32位的M3有4GB的寻址空间,其中用于片上外设的有512MB,基地址为0x40000000. M3各外设基地址,包括片上外设.片上静态RAM和FLA ...
- 009-shiro与spring web项目整合【三】验证码、记住我
一.验证码 1.自定义FormAuthenticationFilter 需要在验证账号和名称之前校验验证码 /** * * <p>Title: CustomFormAuthenticati ...
- node.js---sails项目开发(3)
1.为新建的sails数据库新建一个用户,首先连接数据库 mongo localhost:27017 (1)显示所有数据库 (2)切换数据库 show dbs use sails 新建一个用户 账 ...
- Python高阶函数-闭包
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回. 在这里我们首先回忆一下python代码运行的时候遇到函数是怎么做的. 从python解释器开始执行之后,就在内存中开辟了一个空间 每当 ...
- insert获取主键、联合关联查询
联合查询