Hadoop生态圈介绍及入门(转)
|
本帖最后由 howtodown 于 2015-4-2 23:15 编辑 问题导读
1.Hadoop生态圈介绍了哪些组件,分别都是什么?
2.大数据与Hadoop是什么关系?
本章主要内容:
你可能听别人说过,我们生活在“大数据”的环境中。技术驱动着当今世界的发展,计算能力飞速增长,电子设备越来越普遍,因特网越来越容易接入,与此同时,比以往任何时候都多的数据正在被传输和收集。
企业正在以惊人的速度产生数据。仅Facebook每天就会收集 250 TB 的数据。Thompson Reuters News Analytics (汤普森路透社新闻分析)显示,现在数字数据的总量比2009年的1ZB(1ZB等同于一百万 PB)多了两倍多,到 2015 年有可能将达到7.9ZB,到 2020 年则有可能会达到35ZB。其他调查机构甚至做出了更高的预测。
随着企业产生并收集的数据量增多,他们开始认识到数据分析的重要性。但是,他们必须先有效地管理好自己拥有的大量信息。这会产生新的挑战:怎样才能存储大量的数据?怎样处理它们?怎样高效地分析它们?既然数据会增加,又如何构建一个可扩展的解决方案?
不仅研究人员和数据科学家要面对大数据的挑战。几年前,在Google+ 大会上,计算机书籍出版者Tim O’Reilly引用过Alistair Croll的话,“这些产生了大量的无明显规律数据的公司,正在被那些产生了相对较少的有规律数据的新创公司取代……”。简而言之,Croll想要说,除非你的企业“理解”你拥有的数据,否则你的企业无法与那些“理解”自身数据的公司抗衡。
企业已经意识到:大数据与商业竞争、态势感知、生产力、科学和创新等密切相关,分析这些大数据能够获得巨大的效益。因为商业竞争正在驱动大数据分析,所以大多数企业认同O’Reilly和Croll的观点。他们认为当今企业的生存依赖于存储、处理和分析大量信息的能力,依赖于是否掌控了接受大数据挑战的能力。
如果你阅读这本书,你将会熟悉这些挑战,熟悉Apache的Hadoop,并且知道Hadoop可以解决哪些问题。本章主要介绍大数据的前景和挑战,并且概述Hadoop及其组件生态圈。可以利用这些组件构建可扩展、分布式的数据分析解决方案。
1.1 当大数据遇到Hadoop 由于“人力资本”是一个无形的、对成功至关重要的因素,所以多数企业都认为他们的员工才是他们最有价值的财产。其实还有另外一个关键因素——企业所拥有的“信息”。信息可信度、信息量和信息可访问性可以增强企业信息能力,从而使企业做出更好的决策。
要理解企业产生的大量的数字信息是非常困难的。IBM指出在过去仅仅两年的时间里产生了世界90%的数据。企业正在收集、处理和存储这些可能成为战略资源的数据。十年前,Michael Daconta, Leo Obrst, and Kevin T.Smith (Indianapolis: Wiley, 2004)写的一本书《The Semantic Web: A Guide to the Future of XML, Web Services, and Knowledge Management》中有句格言“只有拥有最好的信息,知道怎样发现信息,并能够最快利用信息的企业才能立于不败之地”。
知识就是力量。问题是,随着收集的数据越来越多,传统的数据库工具将不能管理,并且快速处理这些数据。这将导致企业“淹没”在自己的数据中:不能有效利用数据,不能理解数据之间的联系,不能理解数据潜在的巨大力量。
人们用“大数据”来描述过于庞大的数据集,这些数据集一般无法使用传统的用于存储、管理、搜索和分析等过程的工具来处理。大数据有众多来源,可以是结构型的,也可以是非结构型的;通过处理和分析大数据,可以发现内部规律和模式,从而做出明智选择。
什么是大数据的挑战?怎么存储、处理和分析如此大的数据量,从而从海量数据中获取有用信息?
分析大数据,需要大量的存储空间和超级计算处理能力。在过去的十年中,研究人员尝试了各种的方法来解决数字信息增加带来的问题。首先,把重点放在了给单个计算机更多的存储、处理能力和内存等上面,却发现单台计算机的分析能力并不能解决问题。随着时间的推移,许多组织实现了分布式系统(通过多台计算机分布任务),但是分布式系统的数据分析解决方案往往很复杂,并且容易出错,甚至速度不够快。
在2002年,Doug Cutting和Mike Cafarella开发一个名为Nutch的项目(专注于解决网络爬虫、建立索引和搜索网页的搜索引擎项目),用于处理大量信息。在为Nutch项目解决存储和处理问题的过程中,他们意识到,需要一个可靠的、分布式计算方法,为Nutch收集大量网页数据。
一年后,谷歌发表了关于谷歌文件系统(GFS)和MapReduce的论文,MapReduce是一个用来处理大型数据集的算法和分布式编程平台。当意识到集群的分布式处理和分布式存储的前景后,Cutting和Cafarella把这些论文作为基础,为Nutch构建分布式平台,开发了我们所熟知的Hadoop分布式文件系统(HDFS)和MapReduce。
在2006年,Yahoo在为搜索引擎建立大量信息的索引的过程中,经历了“大数据”挑战的挣扎之后,看到了Nutch项目的前景,聘请了Doug Cutting,并迅速决定采用Hadoop作为其分布式架构,用来解决搜索引擎方面的问题。雅虎剥离出来Nutch项目的存储和处理部分,形成Apache基金的一个开源项目Hadoop,与此同时Nutch的网络爬虫项目保持自己独立性。此后不久,雅虎开始使用Hadoop分析各种产品应用。该平台非常有效,以至于雅虎把搜索业务和广告业务合并成一个单元,从而更好地利用Hadoop技术。
在过去的10年中,Hadoop已经从搜索引擎相关的平台,演变为最流行通用的计算平台,用于解决大数据带来的挑战。它正在快速成为下一代基于数据的应用程序的基础。市场研究公司IDC预计,到2016年,Hadoop驱动的大数据市场将超过23亿美元。自从2008年建立第一家以Hadoop为中心的公司Cloudera之后,几十家基于Hadoop的创业公司吸引了数亿美元的风险投资。简而言之,Hadoop为企业提供了一个行之有效的方法,来进行大数据分析。
1.1.1 Hadoop:迎接大数据挑战 Apache的Hadoop通过简化数据密集型、高度并行的分布式应用的实现,以此迎接大数据的挑战。世界各地的企业、大学和其它组织都在使用Hadoop,Hadoop把任务分成任务片,分布在数千台计算机上,从而进行快速分析,并分布式存储大量的数据。Hadoop利用大量廉价的计算机,提供了一个可扩展强,可靠性高的机制;并利用廉价的方式来存储大量数据。Hadoop还提供了新的和改进的分析技术,从而使大量结构化数据的复杂分析变为可能。
Hadoop与以前的分布式方法的区别:
此外,Hadoop隐藏了复杂的分布式实现过程,提供了一种简单的编程方法。从而,Hadoop得以提供强大的数据分析机制,包括以下内容:
对于大多数Hadoop用户而言,Hadoop最重要的特征是,将业务规划和基础设施维护进行了清晰的划分。为那些专注于商业业务的用户,隐藏了Hadoop的基础设施的复杂性,并提供了一个易于使用的平台,从而使复杂的分布式计算的问题简单化。
1.1.2 商业界的数据科学 Hadoop的存储和处理大数据的能力经常与“数据科学”挂钩。虽然该词是由彼得·诺尔在20世纪60年代提出的,但是直到最近才引起人们广泛关注。美国雪域大学杰弗里·斯坦顿德教授把“数据科学”定义为“一个专注于搜集、分析、可视化、管理和大量信息保存的新兴领域”。
通常将“数据科学”这一术语用在商业业务分析中,与实际中的“大数据”学科有很大的不同。在数据科学中,业务分析师通过研究现有商业运作模式,来提升业务。
数据科学的目标是从数据提取出数据的真正含义。数据科学家基于数学、统计分析、模式识别、机器学习、高性能计算和数据仓库等来工作,通过分析数据来发现事物发展趋势,并基于收集到的信息开发新业务。
在过去的几年中,许多数据库和编程方面的业务分析师成为了数据科学家。他们在Hadoop生态圈中,使用高级的SQL工具(比如:Hive或者实时Hadoop查询工具)进行数据分析,以做出明智的业务决策。
不只是“一个大数据库”
在本书后面会深入讲解Hadoop,但在此之前,让我们先消除这样的误区——Hadoop仅仅是数据分析师使用的工具。因为对于那些熟悉数据库查询的人,Hadoop工具(如Hive和实时Hadoop查询)提供了较低的门槛,所以一些人认为Hadoop仅仅是以数据库为中心的工具。
此外,如果你正在试图解决的问题超出了数据分析的范畴,并涉及到真正的“科学数据”的问题,这时,SQL数据挖掘技术将明显变得不再实用。例如,大多数问题的解决,需要用到线性代数和其它复杂的数学应用程序,然而,这些问题都不能用SQL很好地解决。
这意味着,使用Hadoop工具是解决这类问题的最好办法。利用Hadoop的MapReduce编程模型,不但解决了数据科学的问题,而且明显简化了企业级应用创建和部署的过程。可以通过多种方式做到这一点——可以使用一些工具,这些工具往往要求开发者具备软件开发技能。例如,通过使用基于Oozie的应用程序进行协调(在本书后面将详细介绍Oozie),可以简化多个应用程序的汇集过程,并非常灵活地链接来自多个工具的任务。在本书中,你会看到Hadoop在企业中的实际应用,以及什么时候使用这些工具。
目前Hadoop的开发,主要是为了更好地支持数据科学家。Hadoop提供了一个强大的计算平台,拥有高扩展性和并行执行能力,非常适合应用于新一代功能强大的数据科学和企业级应用。并且,Hadoop还提供了可伸缩的分布式存储和MapReduce编程模式。企业正在使用Hadoop解决相关业务问题,主要集中在以下几个方面:
类似的例子数不胜数。企业正在逐步使用Hadoop进行数据分析,从而作出更好的战略决策。总而言之,数据科学已经进入了商界。
不仅仅是针对商业的大数据工具
虽然这里的大多数例子针对于商业,但是Hadoop也被广泛应用在科学界和公有企业。
最近一项由美国科技基金会进行的研究指出,医疗研究人员已经证明,大数据分析可以被用于分析癌症患者的信息,以提高治疗效果(比如,苹果创始人乔布斯的治疗过程)。警察部门正在使用大数据工具,来预测犯罪可能的发生时间和地点,从而降低了犯罪率。同样的调查也表明,能源方面的官员正在利用大数据工具,分析相关的能量损耗和潜在的电网故障问题。
通过分析大数据可以发现模型和趋势,提高效率,从而用新方法来作出更好的决策。
1.2 Hadoop生态圈 架构师和开发人员通常会使用一种软件工具,用于其特定的用途软件开发。例如,他们可能会说,Tomcat是Apache Web服务器,MySQL是一个数据库工具。
然而,当提到Hadoop的时候,事情变得有点复杂。Hadoop包括大量的工具,用来协同工作。因此,Hadoop可用于完成许多事情,以至于,人们常常根据他们使用的方式来定义它。
对于一些人来说,Hadoop是一个数据管理系统。他们认为Hadoop是数据分析的核心,汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。对于其他人,Hadoop是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。还有一些人认为Hadoop作为一个开源社区,主要为解决大数据的问题提供工具和软件。因为Hadoop可以用来解决很多问题,所以很多人认为Hadoop是一个基本框架。
虽然Hadoop提供了这么多的功能,但是仍然应该把它归类为多个组件组成的Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其它进行数据分析的专门工具。
1.3 HADOOP核心部件 随着时间的推移,Hadoop生态圈越来越大,图1-1给出了Hadoop核心组件。
<ignore_js_op>
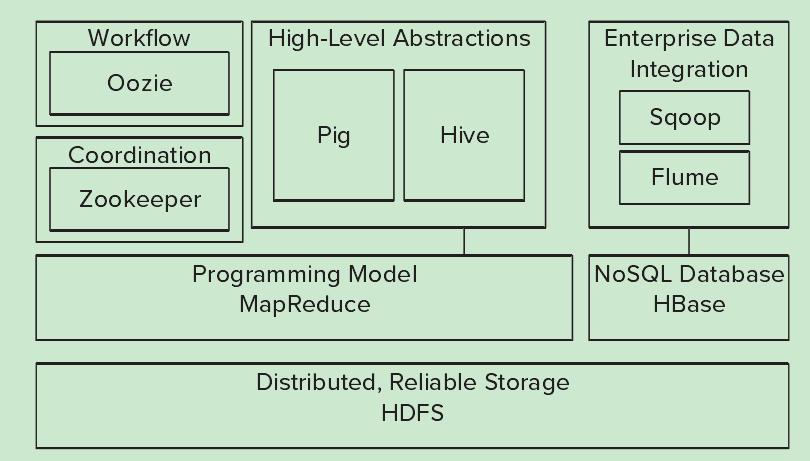 图1:Hadoop生态圈的核心组成组件
从图1-1的底部开始,Hadoop生态圈由以下内容组成:
Hadoop的生态圈还包括以下几个框架,用来与其它企业融合:
除了在图1-1所示的核心部件外,Hadoop生态圈正在不断增长,以提供更新功能和组件,如以下内容:
Hadoop家族成员正在逐步增加。在本书中,主要涉及到了三个新的Apache Hadoop孵化项目。
孵化项目演变到Apach项目的过程
下面将会简要介绍Apache基金会的运作方式,以及Apache各种项目及其彼此之间的联系。Apache的个人会员共同治理整个组织,Apache提供项目的创建、成熟和回收。
新的项目开始于“孵化器”。建立Apache孵化器,是为了帮助新项目加入Apache。Apache提供管理和检验,经过筛选后,再建立新的项目或者子项目。在创建孵化项目后,Apache会评估项目的成熟度,并负责将孵化器中的项目“毕业”到Apache项目或子项目。孵化器也会由于各种原因而终止一些项目。
要查看孵化器中项目(当前的、孵化成功的、暂时停止的和回收的)的完整列表,可以通过此网址:http://incubator.apache.org/projects/index.html。
当今大多数的Hadoop方面的书籍,要么专注于Hadoop生态圈中某个独立组件的描述,要么介绍如何使用Hadoop业务分析工具(如Pig和Hive)。尽管这些方面也很重要,但是这些书籍通常没有进行深入的描述,并不能帮助架构师建立基于Hadoop的企业级应用或复杂应用。
1.4 Hadoop发行版本 虽然Hadoop是开源的Apache(和现在GitHub)项目,但是在Hadoop行业,仍然出现了大量的新兴公司,以帮助人们更方便地使用Hadoop为目标。这些企业大多将Hadoop发行版进行打包、改进,以确保所有的软件一起工作,并提供技术支持。现在,Apache自己也在开发更多的工具来简化Hadoop的使用,并扩展其功能。这些工具是专有的,并有所差异。有的工具成为了Apache Hadoop家族中新项目的基础。其中,有些是经过Apache2许可的开源GitHub项目。尽管所有这些公司都基于Apache Hadoop发行版,但是他们都与Hadoop的愿景有了细微的不同——应该选取哪个方向,怎样完成它。
这些公司之间最大的区别是:Apache源代码的使用。除了MapR公司之外,都认为Hadoop应该由Apache项目的代码定义。相反,MapR认为Apache的代码只是实施参考,可以基于Apache提供的API来实现自己的需求。这种方法使得MapR做出了很大的创新,特别是在HDFS和HBase方面,MapR让这两个基本Hadoop的存储机制更加可靠、更加高性能。MapR还推出了高速网络文件系统(NFS),可以访问HDFS,从而大大简化了一些企业级应用的集成。
有两个关注度较高的Hadoop发行版,分别由亚马逊和微软发布。两者都提供Hadoop的预安装版本,运行于相应的云服务平台(Amazon or Azure),提供PaaS服务。它们都提供了扩展服务,允许开发人员不仅能够利用Hadoop的本地HDFS,也可以通过HDFS映射利用微软和雅虎的数据存储机制(Amazon的S3,和Azure的Windows Azure存储机制)。亚马逊还提供了,在S3上面保存和恢复HBase内容的功能。
表1-1展示了主要的Hadoop发行版的主要特点。
表1: 不同的Hadoop供应商
当然,大量的发行版让你疑惑“我应该使用哪个发行版?”当公司/部门决定采用一个具体的版本时,应该考虑以下几点:
技术细节——包括Hadoop的版本、组件、专有功能部件等等。
易于部署——使用工具箱来实现管理的部署、版本升级、打补丁等等。
易于维护——主要包括集群管理、多中心的支持、灾难恢复支持等等。
成本——包括针发行版的实施成本、计费模式和许可证。
企业集成的支持——Hadoop应用程序与企业中其他部分的集成。
版本的选择依赖于,你打算利用Hadoop来解决哪些问题。本书中的讨论与版本无关,因为笔者看中的是每个发行版提供的价值。
1.5 用Hadoop开发企业级应用 为了满足大数据带来的新挑战,需要重新思考构建数据分析的程序的方式。传统的在数据库中存储数据,构建应用程序的方法,对于大数据处理将不再有效。主要因为:
因此,一个典型的基于Hadoop的企业级应用如图1-2所示。在这些应用中,包括数据存储层、数据处理层、实时访问层和安全层。要实现这种体系结构,不仅需要理解Hadoop组件所涉及的API,而且需要理解他们的功能和局限性,以及每个组件在整体架构中的作用。
如图1-2所示,数据存储层包括源数据和中间数据。源数据主要来自这些外部数据源,外部数据源包括企业应用程序、外部数据库、执行日志和其它数据源。中间数据结果来自Hadoop的执行过程,它们被Hadoop的实时应用程序使用,并交付给其他应用程序和终端用户。
<ignore_js_op>
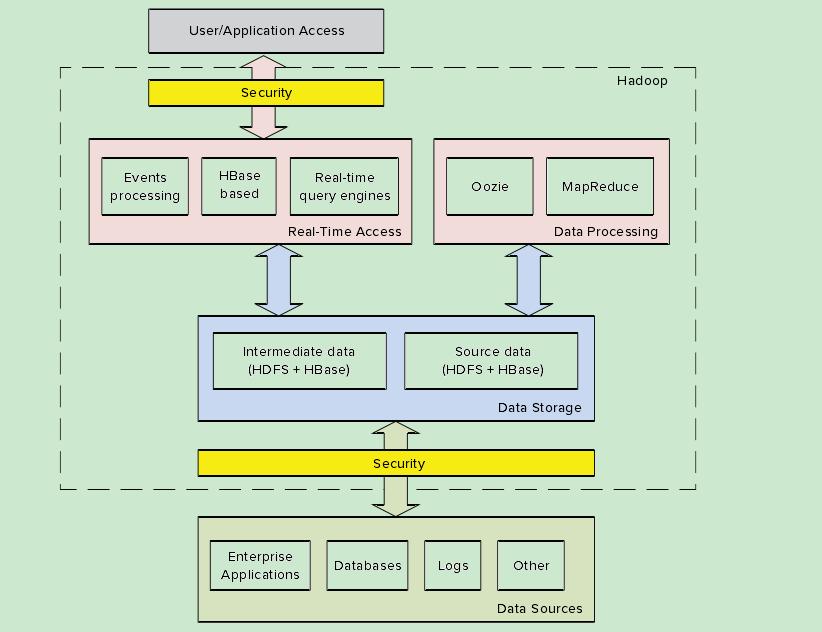 图1-2: Hadoop企业级应用
可以使用不同的机制将源数据转移到Hadoop,包括:Sqoop,Flume,直接安装HDFS作为一个网络文件系统(NFS),或者利用Hadoop的实时服务和应用程序。在HDFS中,新的数据不会覆盖现有数据,而是新建一个数据版本。这一点很重要,因为HDFS是一个“写一次”的文件系统。
对于数据处理层,Oozie预处理源数据,并将其转换为中间数据。不同于源数据,中间数据会被覆盖,没有多个版本,所以中间数据量不会很大。
对于实时访问层,Hadoop的实时应用程序既支持直接数据访问,也支持基于数据集的访问。这些应用程序读取基于Hadoop的中间数据,并将源数据存储在Hadoop。该应用程序也可以用于服务用户,或者用于其它企业的Hadoop集成。
源数据用来存储和初步处理数据,中间数据用于传递和整合数据。因为采用了源数据和中间数据完全分离的结构,所以允许开发人员在没有任何事务处理需求的情况下,构建任何虚拟和复杂的应用程序。通过中间预处理过程,明显减少了服务数据量,使得实时数据访问更加灵活。
HADOOP扩充性
虽然许多文章认为,对于开发人员来讲,Hadoop隐藏了底层的复杂性。但是,其实是这些文章没有充分认识到Hadoop的可扩展。
通过设计Hadoop的实现方式,可以使开发人员轻松、无缝地集成新的功能到Hadoop中执行。Hadoop明确指定一些类库来负责MapReduce执行的不同阶段。通过这种方式,满足了开发者执行特定问题的要求,从而确保每一个作业以最低成本、最高性能性能来执行。
可以自定义Hadoop执行的以下内容:
本书有一部分内容,在他人工作成果的基础上,对自定义方法,以及实现方式进行了专门的描述。
本书涵盖了Hadoop企业级应用的所有主要层,如图1-2所示。
第2章介绍了构建数据层的方法,包括HDFS和HBase(架构和API)。然后,对两者进行对比分析,以及如何将HDFS和HBase相结合。本章还介绍了Avro(Hadoop的新的序列化框架),以及它在存储或访问数据中的作用。最后,你将了解HCatalog,以及用它来做广告和访问数据的方式。
本书将对数据处理进行了大量的描述。对于应用程序的数据处理部分,笔者建议使用MapReduce和Oozie。
在本书中,为什么以MapReduce源码为核心?
你可能会问,为什么本书将重点放在MapReduce源码上,而不是可以让MapReduce编程变得更简单的高级语言上面。你可以在网上或者Hadoop社区内,找到很多关于这方面的讨论。在这些讨论中给出的解释是,MapReduce源码量(就代码行数而言)比提供相同的功能的Pig源码量通常要多很多。尽管这是一个不争的事实,不过还有一些其他因素:
在第3章中,您将了解MapReduce的架构、主要构成和编程模型。本章介绍了MapReduce的应用程序设计、设计模式和MapReduce注意事项。本章还讲介绍MapReduce的执行是如何实现的。正如所提到的,MapReduce最强的特征之一是它可以自定义执行。第4章会介绍自定义选项的详细信息,并举例说明。第5章通过演示实例,对MapReduce进一步讨论,构建可靠的MapReduce应用。
尽管MapReduce功能很强大,但是对于一个切实可行的解决方案,通常需要将多个MapReduce应用集合到在一起。这个过程非常复杂,通过使用Hadoop的Workflow/Coordinator(工作流/协调员)引擎,可以被大大简化MapReduce应用的集成。
Oozie的价值
Oozie是Hadoop中最容易被低估的组件。很少有人(甚至没有)在Hadoop书籍讨论这个极其重要的组件。本书不但彰显了Oozie什么可以做,而且还提供了一个端到端的例子,用来展示如何利用Oozie功能来解决实际问题。类似于Hadoop的其余部分,Oozie的功能也具有很好的扩展性。开发者可以通过不同的方法来扩展Oozie的功能。
在Hadoop中,最容易被低估的挑战是:将Hadoop执行与企业处理的其余部分进行整合。使用Oozie来协调MapReduce应用,并通过公开Oozie API的方式公开了Hadoop进程。通过这种方式,你会很容易就找到更好的集成方法,对Hadoop处理和企业处理部分进行集成。
第6章描述了Oozie是什么,Oozie的体系结构、主要组成、编程语言和执行模型。为了更好地解释每个Oozie组件的功能和角色,第7章通过使用Oozie应用解决端到端的实际问题。第8章中,通过展示Oozie的一些高级功能,对Oozie进一步描述。这些高级功能包括自定义Workflow活动、动态生成Workflow和支持超级JAR文件(一个包含了所有的包及其依赖关系的JAR文件)。
第9章主要讲解实时访问层。该章首先介绍了一个工业中实时Hadoop应用实例,然后针对实现方式提出了整体架构。接着,介绍了建立这种实现的三种主要方法——基于HBase的应用程序、实时查询以及基于流的处理。本章介绍了总体架构,并提供了基于HBase实时应用的两个例子。然后,描述了一个实时查询体系结构,并讨论了两个具体的实现——Apache Drill 和 Cloudera’s Impala。还介绍了实时查询和MapReduce的对比。最后,您将了解基于Hadoop的复杂事件处理,以及两个具体的实现——Strom和HFlame。
开发企业级应用需要大量的规划,以及信息安全方面的策略。第10章将重点讲解Hadoop的安全模型。
随着云计算的发展,许多企业尝试将他们的Hadoop运行在云上。第11章的重点是,通过使用EMR实现,在亚马逊的云上运行Hadoop应用;并且介绍了其它AWS服务(如S3),用来补充Hadoop的功能。本章还介绍了,通过使用不同的方法来运行云上的Hadoop,并讨论了最佳实践方案。
除了Hadoop自身的安全问题外,通常Hadoop还需要集成其他企业的组件,来实现数据的导入和导出。第12章将重点介绍,如何才能维护好那些使用了Hadoop的企业级应用,并提供了示例和最佳安全实践,来确保所有Hadoop企业级应用的安全运行。
1.6 总结 本章高度概括了大数据和Hadoop之间的关系。并介绍了大数据及其价值,还介绍了企业面临的大数据挑战,包括数据存储和处理的挑战。通过本章,你还了解了Hadoop及其历史。
通过本章,你了解了Hadoop特点,并知道了为什么Hadoop如此适合大数据处理。本章还概述了Hadoop的主要组件,并介绍了一些例子,用来展示Hadoop如何简化数据科学,简化创建企业应用程序的过程。
本章介绍了关于Hadoop发行版本的基础知识,以及为什么许多企业倾向于选择特定供应商的发行版。因为他们不希望处理Apache项目中的兼容问题,或者他们需要供应商的技术支持。
最后,本章讨论了一种分层的方法和模型,用于开发基于Hadoop的企业级应用。
第2章开始将深入讲解Hadoop的细节,以及如何存储你的数据。
作者:张子良
出处:http://www.cnblogs.com/hadoopdev 本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 |

Hadoop生态圈介绍及入门(转)的更多相关文章
- hadoop生态圈介绍
原文地址:大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分 ...
- Hadoop生态圈-Hive快速入门篇之HQL的基础语法
Hadoop生态圈-Hive快速入门篇之HQL的基础语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的重点是介绍Hive中常见的数据类型,DDL数据定义,DML数据操作 ...
- Hadoop生态圈-Hive快速入门篇之Hive环境搭建
Hadoop生态圈-Hive快速入门篇之Hive环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据仓库(理论性知识大多摘自百度百科) 1>.什么是数据仓库 数据 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 【】Hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
- Hadoop生态圈-zookeeper本地搭建以及常用命令介绍
Hadoop生态圈-zookeeper本地搭建以及常用命令介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载zookeeper软件 下载地址:https://www.ap ...
- Hadoop生态圈-phoenix完全分布式部署以及常用命令介绍
Hadoop生态圈-phoenix完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. phoenix只是一个插件,我们可以用hive给hbase套上一个JDBC壳,但是你 ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- 14年安徽省赛数论题etc.
关于最大公约数的疑惑 题目描述 小光是个十分喜欢素数的人,有一天他在学习最大公约数的时候突然想到了一个问题,他想知道从1到n这n个整数中有多少对最大公约数为素数的(x,y),即有多少(x,y),gcd ...
- 【贪心】POJ1328-Radar Installation
[思路] 以每一座岛屿为圆心,雷达范围为半径作圆,记录下与x轴的左右交点.如果与x轴没交点,则直接退出输出“-1”.以左交点为关键字进行排序,从左到右进行贪心.容易知道,离每一个雷达最远的那一座岛与雷 ...
- python安装BeautifulSoup
1.先下载pip https://pypi.python.org/pypi/pip 安装pip cd到路径 python setuo.py install 2.添加目录到环境变量中 xxx\Pytho ...
- codevs 1962 马棚问题--序列型DP
1962 马棚问题 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题目描述 Description 每天,小明和他的马外出,然后他们一边跑一边玩耍.当他们结束 ...
- Codeforces Round #127 (Div. 1) B. Guess That Car! 扫描线
B. Guess That Car! 题目连接: http://codeforces.com/contest/201/problem/B Description A widely known amon ...
- Ubantu Mark
说明:由于图形化界面方法(如Add/Remove... 和Synaptic Package Manageer)比较简单,所以这里主要总结在终端通过命令行方式进行的软件包安装.卸载和删除的方法. 一.U ...
- HMACSHA1算法的JAVA实现
import javax.crypto.Mac; import javax.crypto.SecretKey; import javax.crypto.spec.SecretKeySpec; publ ...
- 关于XUtils框架细解
感谢关注xUitls的网友最近一段时间给予的热心反馈,xUtils近期做了很多细节优化之后,功能和api已经稳定. 1.9.6主要更新内容:Bitmap加载动画有时重复出现的问题修复,加载过程优化; ...
- appium+python自动化48-长按(long_press)
前言 长按操作是经常会遇到的场景,通过driver可以直接调出long_press_keycode方法,但是这个方法是长按手机上某个按钮,比如长按电源键,长按home键. 长按某个元素或者长按屏幕上某 ...
- 浏览器下载附件Content-Disposition
Content-disposition是MIME(Multipurpose Internet Mail Extensions,多用途互联网邮件扩展类型)协议的扩展,MIME协议指示MIME用户代理如何 ...