hadoop学习之hdfs文件系统
一、hdfs的概念
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
什么是文件系统呢,其实我们最熟悉的windows用的是NTFS文件系统,linux用的是EXT3等等的,那归根结底不管什么存储方式,不同的文件系统里面存储文件是什么形式,它都是用来存储文件的,那么HDFS也是一样的,那我们就可以把它理解为类似于Win的HDFS的一种存储文件的方式。
二、hdfs实现思想和概念
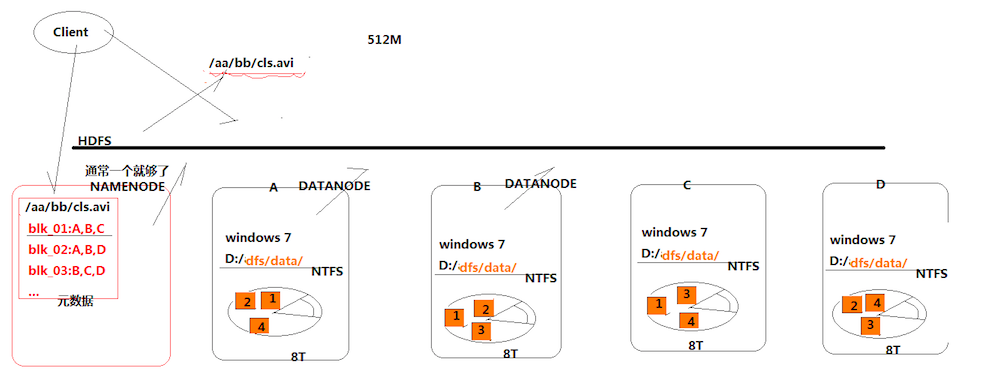
首先有一个概念叫分布式存储,它与普通的存储方式最大的区别在于,它将文件数据切分存放在多台服务器上面,从而减轻了一台服务器的存储压力。那么hdfs也是一种分布式存储的系统,具体怎么存储的如上图所示。
首先,我们又ABCD四个存储的服务器,有一个待存储的文件叫cls.avi,那么既然是分布式存储的,那么我们可以先将带存储文件切分为4块,在图中以1234个小方块表示,那么,我们可以将1234分别先存储到ABCD四个服务器里面,然后ABCD分别用NTFS将其保存起来。
那么这样初步实现了将数据分块存储,然后需要取数据的时候,从四台服务器将数据取出来然后拼接起来,这样就初步实现了数据分布化。但是这样存储面临一种问题,也就是说,如果我其中的一台服务器,比如说A坏掉了,那么最终我取出来的文件便会不全,那么为了解决这种问题,hdfs将文件的块存储在多台服务器里面,如上图中,块1存储在ABC,块2存储在ABD等等,那么如果说,我想取出块1,那么即便A坏了,我也可以从BC里面取,那么最终我取出来的数据还是完整的。
接着,还有一个问题,我是如何知道哪些块存储在哪些服务器上面的呢?那么hdfs提供了一个类似于路由服务器的功能,也就是所谓的namenode,前面所说的存储的服务器叫做datanode。那么namenode主要的功能便是,在数据块被存储的时候,将数据存储信息记录下来,比如说块1:ABC,块2:ABD等等,那么到客户端需要取出数据的时候,可以根据这些存储信息去对应的服务器上面获取数据即可,而且我们不太需要关心namenode的并发压力问题,因为这些存储信息的大小都会很小,不像datanode那样需要存储数据块。
三、总结
1.hdfs是通过分布式集群来存储文件的,文件被存储的时候分块多个block块
2.某一个block块存储在多台数据服务器datanode里面的
3.block块于datanode的存储关系是映射的,信息存储在namenode里面
4.这样存储的好处是其中一台机器发生故障,不会影响到数据的存储与读取
hdfs主要是负责存储,那么如何快速的将这些存储的大量数据读取并且返回给客户端,那么便是MapReduce需要去做的了。博主也是刚刚接触hadoop不久,上面的只是博主个人所学的见解,如果有不对的地方,还请大家多多指教。
hadoop学习之hdfs文件系统的更多相关文章
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- Hadoop学习笔记—HDFS
目录 搭建安装 三个核心组件 安装 配置环境变量 配置各上述三组件守护进程的相关属性 启停 监控和性能 Hadoop Rack Awareness yarn的NodeManagers监控 命令 hdf ...
- Hadoop学习笔记-HDFS命令
进入 $HADOOP/bin 一.文件操作 文件操作 类似于正常的linux操作前面加上“hdfs dfs -” 前缀也可以写成hadoop而不用hdfs,但终端中显示 Use of this scr ...
- hadoop学习(二)----HDFS简介及原理
前面简单介绍了hadoop生态圈,大致了解hadoop是什么.能做什么.带着这些目的我们深入的去学习他.今天一起看一下hadoop的基石--文件存储.因为hadoop是运行与集群之上,处于分布式环境之 ...
- 【Hadoop学习】HDFS 短路本地读
Hadoop版本:2.6.0 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4146296.html 背景 ...
- Hadoop学习笔记---HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.HDFS能提供高吞吐 ...
- Hadoop 学习之——HDFS
HDFS是HADOOP中的核心技术之一——分布式文件存储系统.Hadoop的作者Doug Cutting 和Mike 是根据Google发布关于GFS 的研究报告所设计出的分布式文件存储系统. 一.H ...
- hadoop学习记录--hdfs文件上传过程源码解析
本节并不大算为大家讲接什么是hadoop,或者hadoop的基础知识因为这些知识在网上有很多详细的介绍,在这里想说的是关于hdfs的相关内容.或许大家都知道hdfs是hadoop底层存储模块,专门用于 ...
- hadoop学习之HDFS
1.什么是大数据?什么是云计算?什么是hadoop? 大数据现在很火,到底什么是大数据,多大的数据才算大,一般而言对于TB级以上的数据我们成为大数据,对于这些数据它的价值在哪?大数据的价值就是我们大量 ...
随机推荐
- 小猴打架(luogu4430)(数论+生成树计数)
一开始森林里面有\(N\)只互不相识的小猴子,它们经常打架,但打架的双方都必须不是好朋友.每次打完架后,打架的双方以及它们的好朋友就会互相认识,成为好朋友.经过\(N-1\)次打架之后,整个森林的小猴 ...
- UOJ#419. 【集训队作业2018】圆形(格林公式)
题面 传送门 题解 首先您得会用格林公式计算圆的面积并 这里只需要动态维护一下圆弧就可以了 时间复杂度\(O(n^2\log n)\) //minamoto #include<bits/stdc ...
- [NOI2017]蔬菜(贪心)
神仙题啊! 早上开了两个多小时,终于肝出来了,真香 我们考虑从第 \(10^5\) 天开始递推,先生成 \(p=10^5\) 的解,然后逐步推出 \(p-1,...,2,1\) 的解. 那怎么推出 \ ...
- Testing - 软件测试知识梳理 - 软件可靠性测试
软件可靠性的基本概念 错误,缺陷,故障和失效 错误:指的是软件在生命周期中各个阶段的状态和行为与人们的期待不一致的偏差,不单单是软件系统本身,中间产品的偏差也算是软件错误 缺陷:指的是软件中一切不好的 ...
- redis常用命令(二)
一.集合(set) 单值多value,vaue不能重复 sadd/smembers/sismember 添加数据/获取set所有数据/判断是否存在某个值 scard 获取集合里面的元素个数 srem ...
- python中内建函数isinstance的用法
语法:isinstance(object,type) 作用:来判断一个对象是否是一个已知的类型. 其第一个参数(object)为对象,第二个参数(type)为类型名(int...)或类型名的一个列表( ...
- office2013安装与卸载
一.office2013卸载不干净,重新安装的时候就会报错.下面是博主卸载的步骤: 第一步:下载office官方卸载工具 ,链接:http://pan.baidu.com/s/1nvuoEYd 密码: ...
- (转)Db2 数据库性能优化中,十个共性问题及难点的处理经验
(转)https://mp.weixin.qq.com/s?__biz=MjM5NTk0MTM1Mw==&mid=2650629396&idx=1&sn=3ec17927b3d ...
- (转载)es进行聚合操作时提示Fielddata is disabled on text fields by default
原文地址:http://blog.csdn.net/u011403655/article/details/71107415 根据es官网的文档执行 GET /megacorp/employee/_se ...
- Spring Boot 基础概述与相关约定配置
今天打算整理一下 Spring Boot 的基础篇,这系列的文章是我业余时间来写的,起源于之前对微服务比较感兴趣,微服务的范畴比较广包括服务治理.负载均衡.断路器.配置中心.API网关等,还需要结合 ...