Java队列——Disruptor 的使用
、什么是 Disruptor
从功能上来看,Disruptor 是实现了“队列”的功能,而且是一个有界队列。那么它的应用场景自然就是“生产者-消费者”模型的应用场合了。
可以拿 JDK 的 BlockingQueue 做一个简单对比,以便更好地认识 Disruptor 是什么。
我们知道 BlockingQueue 是一个 FIFO 队列,生产者(Producer)往队列里发布(publish)一项事件(或称之为“消息”也可以)时,消费者(Consumer)能获得通知;如果没有事件时,消费者被堵塞,直到生产者发布了新的事件。
这些都是 Disruptor 能做到的,与之不同的是,Disruptor 能做更多:
- 同一个“事件”可以有多个消费者,消费者之间既可以并行处理,也可以相互依赖形成处理的先后次序(形成一个依赖图);
- 预分配用于存储事件内容的内存空间;
- 针对极高的性能目标而实现的极度优化和无锁的设计;
以上的描述虽然简单地指出了 Disruptor 是什么,但对于它“能做什么”还不是那么直截了当。一般性地来说,当你需要在两个独立的处理过程(两个线程)之间交换数据时,就可以使用 Disruptor 。当然使用队列(如上面提到的 BlockingQueue)也可以,只不过 Disruptor 做得更好。
拿队列来作比较的做法弱化了对 Disruptor 有多强大的认识,如果想要对此有更多的了解,可以仔细看看 Disruptor 在其东家 LMAX 交易平台(也是实现者) 是如何作为核心架构来使用的,这方面就不做详述了,问度娘或谷哥都能找到。
二、Disruptor 的核心概念
当消费者等待在SequenceBarrier上时,有许多可选的等待策略,不同的等待策略在延迟和CPU资源的占用上有所不同,可以视应用场景选择:
BusySpinWaitStrategy : 自旋等待,类似Linux Kernel使用的自旋锁。低延迟但同时对CPU资源的占用也多。
BlockingWaitStrategy : 使用锁和条件变量。CPU资源的占用少,延迟大。
SleepingWaitStrategy : 在多次循环尝试不成功后,选择让出CPU,等待下次调度,多次调度后仍不成功,尝试前睡眠一个纳秒级别的时间再尝试。这种策略平衡了延迟和CPU资源占用,但延迟不均匀。
YieldingWaitStrategy : 在多次循环尝试不成功后,选择让出CPU,等待下次调。平衡了延迟和CPU资源占用,但延迟也比较均匀。
PhasedBackoffWaitStrategy : 上面多种策略的综合,CPU资源的占用少,延迟大。
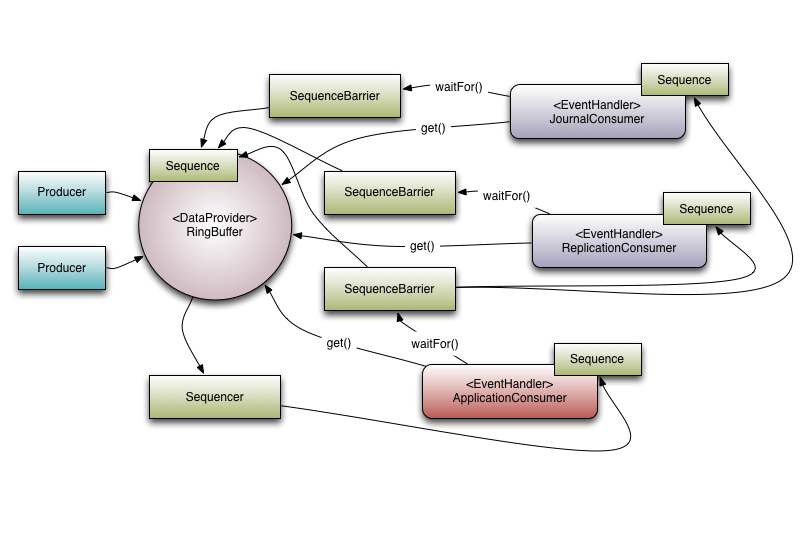
先从了解 Disruptor 的核心概念开始,来了解它是如何运作的。下面介绍的概念模型,既是领域对象,也是映射到代码实现上的核心对象。
- Ring Buffer
如其名,环形的缓冲区。曾经 RingBuffer 是 Disruptor 中的最主要的对象,但从3.0版本开始,其职责被简化为仅仅负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。在一些更高级的应用场景中,Ring Buffer 可以由用户的自定义实现来完全替代。 - Sequence Disruptor
通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。一个 Sequence 用于跟踪标识某个特定的事件处理者( RingBuffer/Consumer )的处理进度。虽然一个 AtomicLong 也可以用于标识进度,但定义 Sequence 来负责该问题还有另一个目的,那就是防止不同的 Sequence 之间的CPU缓存伪共享(Flase Sharing)问题。
(注:这是 Disruptor 实现高性能的关键点之一,网上关于伪共享问题的介绍已经汗牛充栋,在此不再赘述)。 - Sequencer
Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。 - Sequence Barrier
用于保持对RingBuffer的 main published Sequence 和Consumer依赖的其它Consumer的 Sequence 的引用。 Sequence Barrier 还定义了决定 Consumer 是否还有可处理的事件的逻辑。 - Wait Strategy
定义 Consumer 如何进行等待下一个事件的策略。 (注:Disruptor 定义了多种不同的策略,针对不同的场景,提供了不一样的性能表现) - Event
在 Disruptor 的语义中,生产者和消费者之间进行交换的数据被称为事件(Event)。它不是一个被 Disruptor 定义的特定类型,而是由 Disruptor 的使用者定义并指定。 - EventProcessor
EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。 - EventHandler
Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是 Consumer 的真正实现。 - Producer
即生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型。
三、如何使用 Disruptor
Disruptor 的 API 十分简单,主要有以下几个步骤:
- 定义事件
事件(Event)就是通过 Disruptor 进行交换的数据类型。
public class LongEvent
{
private long value; public void set(long value)
{
this.value = value;
}
} - 定义事件工厂
事件工厂(Event Factory)定义了如何实例化前面第1步中定义的事件(Event),需要实现接口 com.lmax.disruptor.EventFactory<T>。
Disruptor 通过 EventFactory 在 RingBuffer 中预创建 Event 的实例。
一个 Event 实例实际上被用作一个“数据槽”,发布者发布前,先从 RingBuffer 获得一个 Event 的实例,然后往 Event 实例中填充数据,之后再发布到 RingBuffer 中,之后由 Consumer 获得该 Event 实例并从中读取数据。import com.lmax.disruptor.EventFactory; public class LongEventFactory implements EventFactory<LongEvent>
{
public LongEvent newInstance()
{
return new LongEvent();
}
} - 定义事件处理的具体实现
通过实现接口 com.lmax.disruptor.EventHandler<T> 定义事件处理的具体实现。import com.lmax.disruptor.EventHandler; public class LongEventHandler implements EventHandler<LongEvent>
{
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("Event: " + event);
}
} - 定义用于事件处理的线程池
Disruptor 通过 java.util.concurrent.ExecutorService 提供的线程来触发 Consumer 的事件处理。例如:ExecutorService executor = Executors.newCachedThreadPool();
- 指定等待策略
Disruptor 定义了 com.lmax.disruptor.WaitStrategy 接口用于抽象 Consumer 如何等待新事件,这是策略模式的应用。
Disruptor 提供了多个 WaitStrategy 的实现,每种策略都具有不同性能和优缺点,根据实际运行环境的 CPU 的硬件特点选择恰当的策略,并配合特定的 JVM 的配置参数,能够实现不同的性能提升。
例如,BlockingWaitStrategy、SleepingWaitStrategy、YieldingWaitStrategy 等,其中,
BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现;
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景;
YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy();
WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy();
WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy(); - 启动 Disruptor
EventFactory<LongEvent> eventFactory = new LongEventFactory();
ExecutorService executor = Executors.newSingleThreadExecutor();
int ringBufferSize = 1024 * 1024; // RingBuffer 大小,必须是 2 的 N 次方; Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(eventFactory,
ringBufferSize, executor, ProducerType.SINGLE,
new YieldingWaitStrategy()); EventHandler<LongEvent> eventHandler = new LongEventHandler();
disruptor.handleEventsWith(eventHandler); disruptor.start(); - 发布事件
Disruptor 的事件发布过程是一个两阶段提交的过程:
第一步:先从 RingBuffer 获取下一个可以写入的事件的序号;
第二步:获取对应的事件对象,将数据写入事件对象;
第三部:将事件提交到 RingBuffer;
事件只有在提交之后才会通知 EventProcessor 进行处理;// 发布事件;
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
long sequence = ringBuffer.next();//请求下一个事件序号; try {
LongEvent event = ringBuffer.get(sequence);//获取该序号对应的事件对象;
long data = getEventData();//获取要通过事件传递的业务数据;
event.set(data);
} finally{
ringBuffer.publish(sequence);//发布事件;
}注意,最后的 ringBuffer.publish 方法必须包含在 finally 中以确保必须得到调用;如果某个请求的 sequence 未被提交,将会堵塞后续的发布操作或者其它的 producer。
Disruptor 还提供另外一种形式的调用来简化以上操作,并确保 publish 总是得到调用。
static class Translator implements EventTranslatorOneArg<LongEvent, Long>{
@Override
public void translateTo(LongEvent event, long sequence, Long data) {
event.set(data);
}
} public static Translator TRANSLATOR = new Translator(); public static void publishEvent2(Disruptor<LongEvent> disruptor) {
// 发布事件;
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
long data = getEventData();//获取要通过事件传递的业务数据;
ringBuffer.publishEvent(TRANSLATOR, data);
}此外,Disruptor 要求 RingBuffer.publish 必须得到调用的潜台词就是,如果发生异常也一样要调用 publish ,那么,很显然这个时候需要调用者在事件处理的实现上来判断事件携带的数据是否是正确的或者完整的,这是实现者应该要注意的事情。
- 关闭 Disruptor
disruptor.shutdown();//关闭 disruptor,方法会堵塞,直至所有的事件都得到处理;
executor.shutdown();//关闭 disruptor 使用的线程池;如果需要的话,必须手动关闭, disruptor 在 shutdown 时不会自动关闭;
Java队列——Disruptor 的使用的更多相关文章
- 高性能队列Disruptor系列1--传统队列的不足
在前一篇文章Java中的阻塞队列(BlockingQueue)中介绍了Java中的阻塞队列.从性能上我们能得出一个结论:数组优于链表,CAS优于锁.那么有没有一种队列,通过数组的方式实现,而且采用无锁 ...
- java队列Queue及阻塞队列
java队列 接口Queue类在java.util包,定义了以下6个方法 详细查看官方文档https://docs.oracle.com/javase/7/docs/api/java/util/Que ...
- JAVA队列的使用
JAVA队列的使用 今天跟大家来看看如何在项目中使用队列.首先我们要知道使用队列的目的是什么?一般情况下,如果是一些及时消息的处理,并且处理时间很短的情况下是不需要使用队列的,直接阻塞式的方法调用就可 ...
- 高性能无锁队列 Disruptor 初体验
原文地址: haifeiWu和他朋友们的博客 博客地址:www.hchstudio.cn 欢迎转载,转载请注明作者及出处,谢谢! 最近一直在研究队列的一些问题,今天楼主要分享一个高性能的队列 Disr ...
- Java:Java 队列的遍历
Java队列到底有没有可以遍历的功能呢?暂且试一下吧 参考链接:stl容器遍历测试 1.LinkedList实现简单遍历 for(Iter =LocTimesSerials.size()-1; iSe ...
- 高性能队列Disruptor系列2--浅析Disruptor
1. Disruptor简单介绍 Disruptor是一个由LMAX开源的Java并发框架.LMAX是一种新型零售金融交易平台,这个系统是建立在 JVM 平台上,核心是一个业务逻辑处理器,它能够在一个 ...
- 高性能队列Disruptor系列3--Disruptor的简单使用(译)
简单用法 下面以一个简单的例子来看看Disruptor的用法:生产者发送一个long型的消息,消费者接收消息并打印出来. 首先,我们定义一个Event: public class LongEvent ...
- 高性能队列——Disruptor
背景 Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级).基于Disruptor开发的系统单线程能 ...
- 高性能队列Disruptor的使用
一.什么是 Disruptor 从功能上来看,Disruptor 是实现了"队列"的功能,而且是一个有界队列.那么它的应用场景自然就是"生产者-消费者"模型的应 ...
随机推荐
- linux 环境安装及学习
一.Httpd Linux(Apache)Httpd服务器安装,启动及httpd.conf配置详解 https://blog.51cto.com/itwish/2160492 httpd-2.4. ...
- html5+javascript的管廊监控页面
这周二做的,支持苹果手机,安卓手机,电脑,平板访问
- POJ3692 Kindergarten
Kindergarten Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 6882 Accepted: 3402 Desc ...
- Maven提高篇系列之五——处理依赖冲突
个人分类: Maven 不知道你在使用Maven时是否遇到过诸如"NoSuchMethodError"或"ClassNotFoundException"之类的问 ...
- tarjan算法的补充POJ2533tarjan求度
做题时又遇到了疑惑,说明一开始就没有完全理解 基于dfs的tarjan,搜索时会有四种边 树枝边:DFS 时经过的边,即 DFS 搜索树上的边 前向边:与 DFS 方向一致,从某个结点指向其某个子孙的 ...
- HTML 基础 块级元素与行内元素
块元素:单独占一行,宽度占整行,可以包含内联元素和其他块元素,通过样式display:inline,变为行内元素,不换行 内联元素:不单独占一行,宽度根据内容来决定,只能容纳文本或者其他内联元素 ,可 ...
- hdu 1.3.3 今年暑假不AC
//简单.... 1 #include<iostream> #include<cstdio> #include<cstdlib> using namespace s ...
- ICCV2013、CVPR2013、ECCV2013目标检测相关论文
CVPapers 网址: http://www.cvpapers.com/ ICCV2013 Papers about Object Detection: 1. Regionlets for Ge ...
- Win7下无法启动sql server fulltext search (mssqlserver)的问题
在Win7下安装了SQL Server 2005, 但启动“SQL Server FullText Search (MSSQLSERVER)”服务时启动不成功,系统日志显示“SQL Server Fu ...
- ASP.NET MVC 使用Unity实现Ioc
为什么有这篇文章 最近在学ASP.NET MVC项目中使用Ioc,选用了Unity作为依赖注入的容器组件,在网上找了相关的文章简单实现了依赖注入,但想用文件配置的方式进行容器注入的注册,发现相关的文章 ...