The case for learned index structures
17年的旧文,最近因为SageDB论文而重读。
文章主要思路是通过学习key的顺序、结构等来预测record在位置、存在与否等。效果方面,据称部分场景下,相对b-tree可以优化70%的内存占用。
最大价值其实在于使用ML来优化(索引)系统这个新的方向。
Range Index
审视下btree查找完成的功能:输入一个key,每次选出一个可能的范围(分支节点),直到最后命中(叶子节点)。这其实跟ML中模型类似。

换句话说,若能估算出数据的累积分布(记作F),那么查询key所在位置,也可以看成是 pos = F(key) * N 这样一个过程。
基于此,文章首先尝试了朴素的方案:使用tf训练并运行一个2层全连接的神经网络,每层32个单元,使用ReLU作为激发函数。
然而这个方案运行效果很差,单次查找耗时比btree高了2个数量级。原因是多方面的:
- TF并不针对小数据集优化
- 单一的神经网络在最后的精细部分(last mile),需要花费大量的计算与存储资源
- btree的设计考量了内存优化等,而朴素方案显然还较为粗糙(全连接层)
The RM-Index
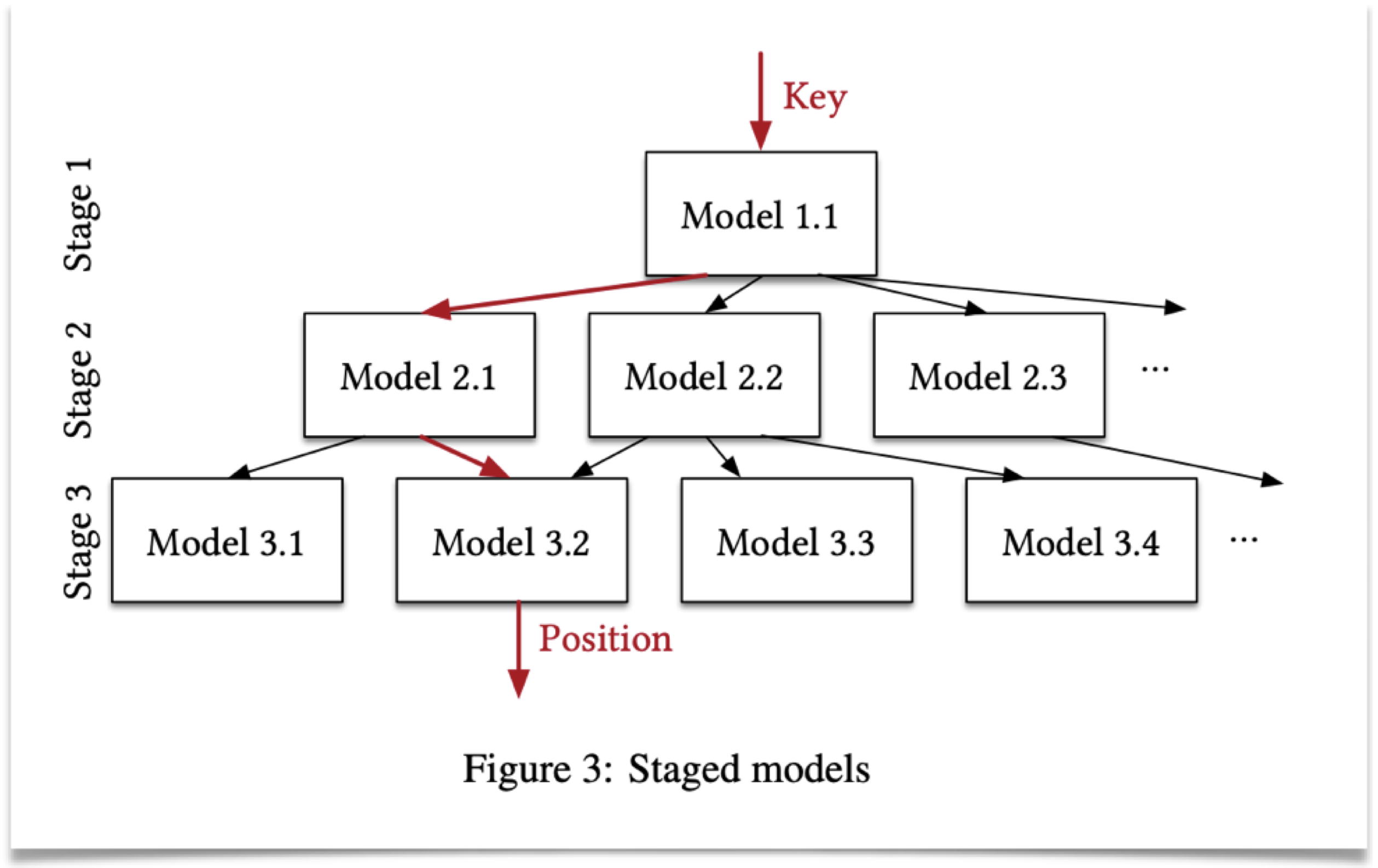
针对上文朴素方案的问题,文章进行了一系列的优化。
首先不再使用TF进行推断查找,而是开发发了一个叫LIF的框架,从TF模型中提取权重参数,直接生成专为小数据集优化的高效C++代码。
其次,使用RMI递归(而非单一)模型,在逐步缩小key的范围。由于每次问题被分解到小范围内进行,资源消耗得到改善的同时,模型的精度可以更好提升。RMI每层的输出是下一层的输入,有利于使用TPU/GPU进行优化。RMI中可以在不同的stage混合使用btree在内的不同类型模型来达到最佳效果,所以理论上不会比单纯的btree差。这个思路很ML,一个模型接一个模型:)
并且,由于模型实际上已经预测出key的位置(position),而不仅仅是范围(range),本文使用了两种新的查找算法(MBS、BQS)利用该信息来更高效地进行查找。
一连串的优化之后,模型的训练和运行有了明显的优化。其中,训练过程使用sgd只需要一次或少量的访问就可以。2亿条记录能在秒级完成。
对于整型数据集,相同内存占用时下,RMI经常能较btree有数倍性能提升。或者说性能相同时,内存占用会有数量级的优化。见下图:
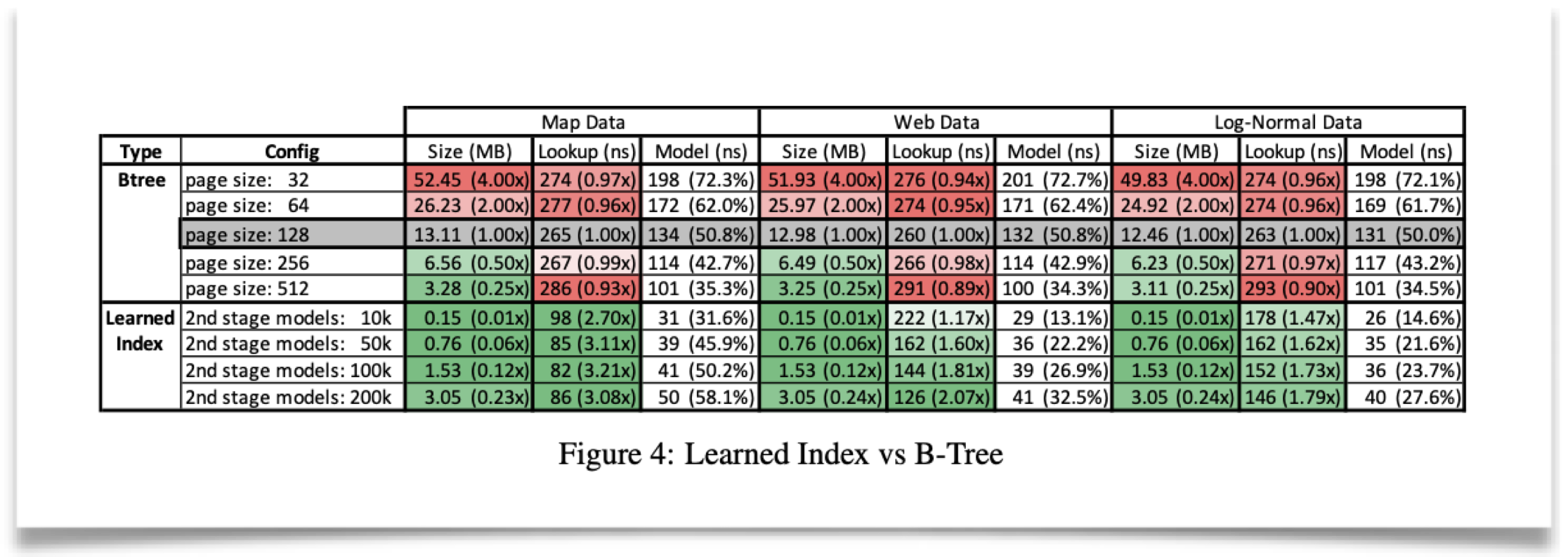
在尽量公平相似的场景下,跟其他相关方案(FAST等)比也有明显优化:

在字符串场景下,优化场景不明显,原因可能在于字符串比较太耗时,model执行时间过长等。后者用TPU/GPU可能会有优化空间。
Point Index
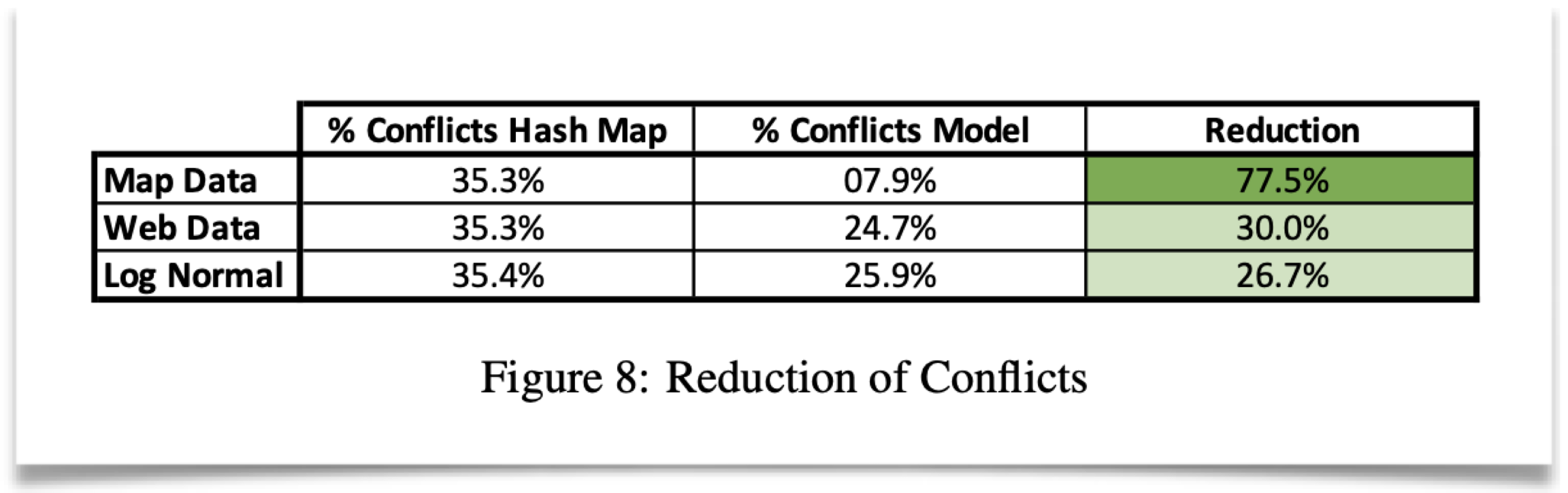
point idx(hash索引)的优化基础在于,典型的数据冲突可能会有33%(如生日)。然而实际减少冲突和运行效果取决于两个主要方面:
- 数据本身的分布情况。比如均匀分布场景下,learned idx不会比普通的随机hash函数好多少;
- 其他payload等
从文章的数据集来说,还是有效果的:
Existence Index
存在性的索引,本文优化方面主要在于内存占用:10亿记录典型bloom filter需要1.76GB,如果要FPR为0.01%,则需要2.23GB。
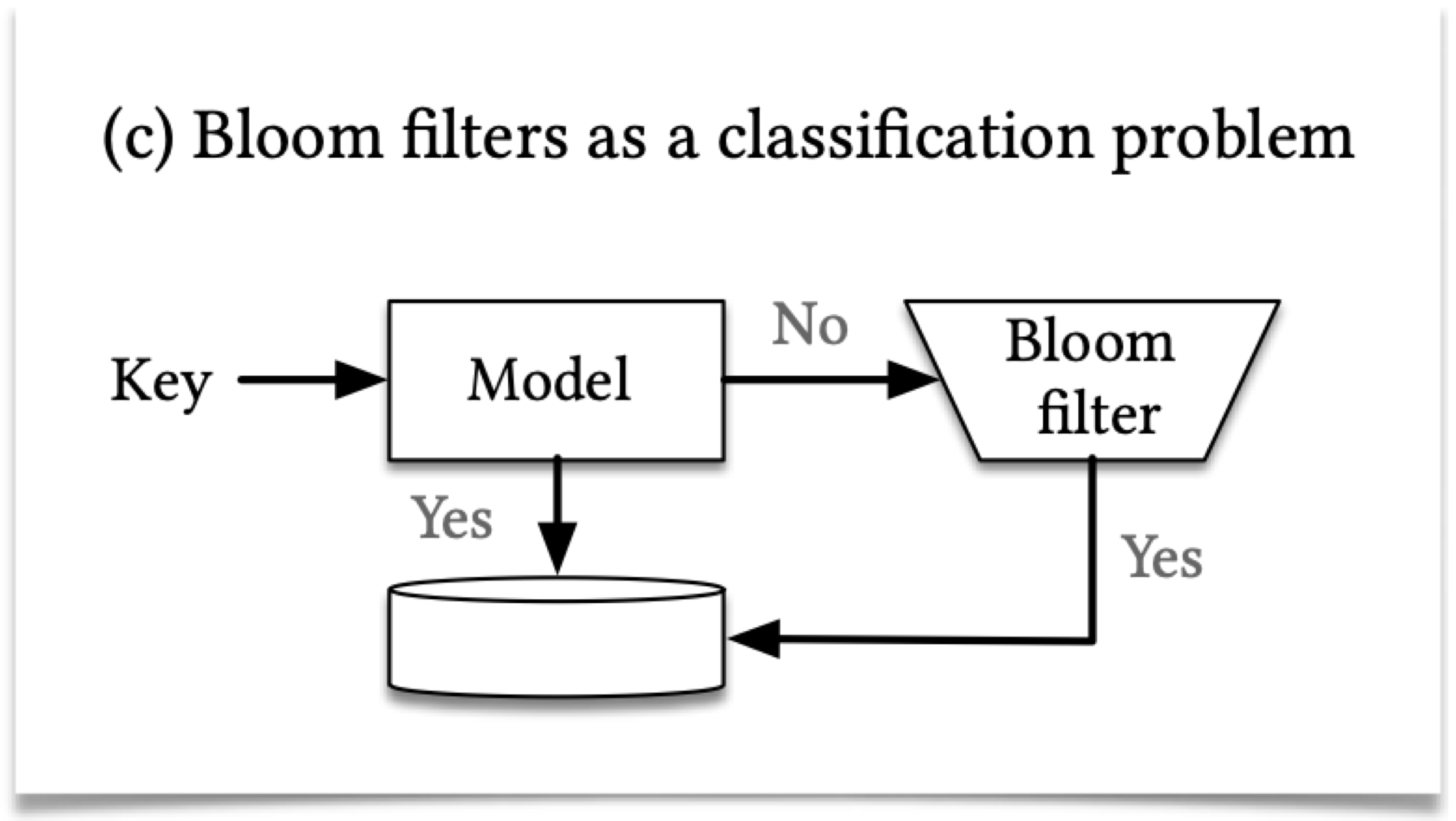
前边在索引需要学习数据分布,而存在性索引,需要让合法的key相关,非法的key相关,而合法key与非法key间不相关。这其实就很像分类问题了。
另一方面,由于ML的特别,FPR下降时,FNR通常会上升。这跟bloom filter要求的FPR尽量小,FNR为0有冲突。解决方案是,在模型判断为false时,另行使用一个overflow bloom filter进行判断。由于bloom filter的大小于数据集相关,因为后接的bloom filter大小于FNR(即false部分相关),这要远小于传统方案中的大小。
需要注意的是,该文章只研究了查询存在一定规律的场景,并在此这上建立模型。这在实际使用时要视业务场景而定。
在符合条件的情况下,1.7M条URL, 1. FPR 0.5%,FNR 55%时,2.04MB->1.31MB,减少36% 2. FPR 0.1%,FNR 76%时,3.06MB->2.59MB,减少15%。

Conclusion and Future Work
文章研究的是单一维度索引,如果能支持多维索引,对现实系统将会有更多帮助。
文章提到其价值时指出目前的索引是state-of-the-arts状态。有意思的是,ML又何尝不是呢?:)
The case for learned index structures的更多相关文章
- 【AI科技大本营】
从AutoML.机器学习新算法.底层计算.对抗性攻击.模型应用与底层理解,到开源数据集.Tensorflow和TPU,Google Brain 负责人Jeff Dean发长文来总结他们2017年所做的 ...
- SysML——AI-Sys Spring 2019
AI-Sys Syllabus Projects Grading AI-Sys Spring 2019 When: Mondays and Wednesdays from 9:30 to 11:00 ...
- skip index scan
官网对skip index scan的解释: Index skip scans improve index scans by nonprefix columns since it is often f ...
- 重建索引:ALTER INDEX..REBUILD ONLINE vs ALTER INDEX..REBUILD
什么时候需要重建索引 1. 删除的空间没有重用,导致 索引出现碎片 2. 删除大量的表数据后,空间没有重用,导致 索引"虚高" 3.索引的 clustering_facto 和表不 ...
- The Architecture of Open Source Applications: Berkeley DB
最近研究内存关系数据库的设计与实现,下面一篇为berkeley db原始两位作为的Berkeley DB设计回忆录: Conway's Law states that a design reflect ...
- Partitioning & Archiving tables in SQL Server (Part 1: The basics)
Reference: http://blogs.msdn.com/b/felixmar/archive/2011/02/14/partitioning-amp-archiving-tables-in- ...
- sql是如何执行一个查询的!
引用自:http://rusanu.com/2013/08/01/understanding-how-sql-server-executes-a-query/ Understanding how SQ ...
- Study notes for B-tree and R-tree
B-tree B-tree is a tree data structure that keeps data sorted and allows searches, sequential access ...
- Spark MLlib 机器学习
本章导读 机器学习(machine learning, ML)是一门涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多领域的交叉学科.ML专注于研究计算机模拟或实现人类的学习行为,以获取新知识.新 ...
随机推荐
- Java理论学时第六节。课后作业。
package Fuction; class Grandparent { public Grandparent() { System.out.println("GrandParent Cre ...
- java基础-day24
第01天 java基础加强 今日内容介绍 u Junit单元测试及反射概述 u 反射操作构造方法.成员方法.成员属性 u properties的基本操作 u 综合案例 第1章 Junit单元测试及 ...
- VC中C++数值范围的确定
1. Visual C++ 32 位和 64 位编译器可识别本文后面的表中的类型. 如果其名称以两个下划线 (__) 开始,则数据类型是非标准的. 下表中指定的范围均包含起始值和结束值. 类型名称 字 ...
- codeforces877c
C. Slava and tanks time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- 数据统计--union all 执行多条sql
需求--统计hive某张表type字段不同取值的数据量 我们已知某张表的type的取值是1,2,3,4,5,想要统计不同type的数据量,并清晰的展现出来.可以通过union all 的方式,sql如 ...
- Ubuntu下SVN安装和配置
一.SVN安装 1.安装包 1.$ sudo apt-get install subversion 2.创建项目目录 $ sudo mkdir /home/xiaozhe/svn $ cd /home ...
- Convolution Neural Network (CNN) 原理与实现
本文结合Deep learning的一个应用,Convolution Neural Network 进行一些基本应用,参考Lecun的Document 0.1进行部分拓展,与结果展示(in pytho ...
- Windows核心编程:第3章 内核对象
Github https://github.com/gongluck/Windows-Core-Program.git //第3章 内核对象.cpp: 定义应用程序的入口点. // #include ...
- WinForm中实现Loading加载界面
1,LoaderForm窗体中添加PictureBox,然后添加Loading图片 2,窗体内属性设置 StartPosition :CenterScreen在屏幕中心显示 TopMost:True置 ...
- C#导入Excel数据常见问题
今天在做一个excle数据导入的时候遇到了一个奇葩问题,项目使用的是MVC,在VS2010里面调试的时候没有问题,可是当发布到本地IIS或服务器上时就出现了问题: 1.excel文件正在被使用: 2. ...