使用pymysql
安装
pip3 install pymysql
连接、执行sql、关闭(游标)
import pymysql
mysql_connect_dict={
'host':'127.0.0.1',
'port':3306,
'user':'yycenter',
'password':'qwe123',
'db':'testmysql',
'charset':'utf8'
}
# 连接数据库
# conn = pymysql.connect(**mysql_connect_dict)
# 指定以dict形式返回,默认以元祖形式
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn)
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
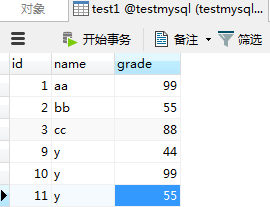
effect_row = cursor.execute("select * from test1")
print(effect_row) # 6条记录
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
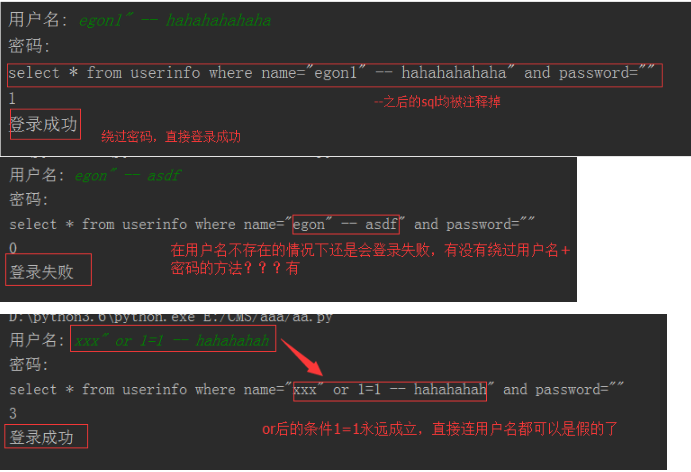
execute之sql注入
注意:符号--会注释掉它之后的sql,正确的语法:--后至少有一个任意字符
根本原理:就根据程序的字符串拼接name='%s',我们输入一个xxx' -- haha,用我们输入的xxx加'在程序中拼接成一个判断条件name='xxx' -- haha'
sql='select * from userinfo where name="%s" and password="%s"' %(user,pwd) #注意%s需要加引号 #1、sql注入之:用户存在,绕过密码
egon' -- 任意字符 #2、sql注入之:用户不存在,绕过用户与密码
xxx' or 1=1 -- 任意字符
解决方法:
# 原来是我们对sql进行字符串拼接
# sql="select * from userinfo where name='%s' and password='%s'" %(user,pwd)
# print(sql)
# res=cursor.execute(sql) #改写为(execute帮我们做字符串拼接,我们无需且一定不能再为%s加引号了)
sql="select * from userinfo where name=%s and password=%s" #!!!注意%s需要去掉引号,因为pymysql会自动为我们加上
res=cursor.execute(sql,[user,pwd]) #pymysql模块自动帮我们解决sql注入的问题,只要我们按照pymysql的规矩来。
增、删、改
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn) # 创建游标
cursor = conn.cursor() # 执行SQL,并返回收影响行数
effect_row = cursor.execute("select * from test1")
print(effect_row) # 6条记录 # #执行sql语句
# #part1
sql="insert into test1(name,grade) values('egon',99)"
res=cursor.execute(sql) # 执行sql语句,返回sql影响成功的行数
print(res) # 1
#
# #part2
sql='insert into test1(name,grade) values(%s,%s);'
res=cursor.execute(sql, ("alex",100)) # 执行sql语句,返回sql影响成功的行数
print(res)# 1
#
# # part3
sql = 'insert into test1(name,grade) values(%s,%s);'
res = cursor.executemany(sql,[('egon1',99),('egon2',88),('egon3',77)]) # 执行sql语句,返回sql影响成功的行数
print(res) # 3 执行sql语句,返回sql影响成功的行数
#
conn.commit() # 提交后才发现表中插入记录成功 # part4
sql = 'update test1 set grade = %s where name= %s;'
res = cursor.execute(sql,(66,'egon')) # 执行sql语句,返回sql影响成功的行数
print(res) # 1 执行sql语句,返回sql影响成功的行数
conn.commit() # 提交后才发现表中插入记录成功 # part5
sql = 'delete from test1 where name= %s;'
res = cursor.execute(sql,('egon2')) # 执行sql语句,返回sql影响成功的行数
print(res) # 1 执行sql语句,返回sql影响成功的行数 conn.commit() # 提交后才发现表中插入记录成功 # 关闭游标
cursor.close()
# 关闭连接
conn.close()
查询
# 指定以dict形式返回,默认以元祖形式
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn) # 创建游标
cursor = conn.cursor() # 执行SQL,并返回收影响行数
effect_row = cursor.execute("select * from test1")
print(effect_row) # res1=cursor.fetchone() # 获取剩余结果的第一行数据 res2=cursor.fetchmany(2) # 获取剩余结果前n行数据 res3=cursor.fetchall() # 获取剩余结果所有数据
print(res1)
#{'id': 1, 'name': 'aa', 'grade': 99}
print(res2)
#[{'id': 2, 'name': 'bb', 'grade': 55}, {'id': 3, 'name': 'cc', 'grade': 88}]
print(res3)
# [{'id': 9, 'name': 'y', 'grade': 44}, {'id': 10, 'name': 'y', 'grade': 99}, {'id': 11, 'name': 'y', 'grade': 55}] res4=cursor.fetchall() # 获取剩余结果所有数据
print(res4) # 空,数据已经取完 # 在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置
cursor.scroll(0, mode='absolute') # 相对绝对位置移动
res5=cursor.fetchmany(2) # 获取剩余结果前2行数据
print(res5)
# [{'id': 1, 'name': 'aa', 'grade': 99}, {'id': 2, 'name': 'bb', 'grade': 55}] cursor.scroll(2, mode='relative') # 相对当前位置移动2条记录,总记录数还剩下2条
res6=cursor.fetchall() # 获取剩余结果所有数据
print(res6)
# [{'id': 10, 'name': 'y', 'grade': 99}, {'id': 11, 'name': 'y', 'grade': 55}]
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
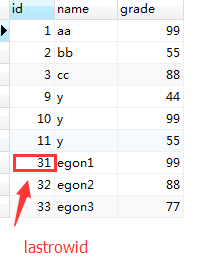
获取新创建数据自增ID
可以获取到最新自增的ID,也就是最后插入的一条数据ID
# conn = pymysql.connect(**mysql_connect_dict)
# 指定以dict形式返回,默认以元祖形式
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn) # 创建游标
cursor = conn.cursor() # 执行SQL,并返回收影响行数
effect_row = cursor.execute("select * from test1") sql = 'insert into test1(name,grade) values(%s,%s);'
res = cursor.executemany(sql,[('egon1',99),('egon2',88),('egon3',77)]) # 执行sql语句,返回sql影响成功的行数
print(res) # 3 执行sql语句,返回sql影响成功的行数 conn.commit() #获取自增id
new_id = cursor.lastrowid
print(new_id) #31
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
调用存储过程
调用无参存储过程
# 指定以dict形式返回,默认以元祖形式
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn) # 创建游标
cursor = conn.cursor() # 执行SQL,并返回收影响行数
effect_row = cursor.execute("select * from test1") # 无参数存储过程
cursor.callproc('p1') # 等价于cursor.execute("call p1()")
# create procedure p1()
# BEGIN
# INSERT into test1(name,grade) values('egon4',100);
# commit;
# END
row_1 = cursor.fetchone()
print(row_1)
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
b、调用有参存储过程
# 指定以dict形式返回,默认以元祖形式
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn) # 创建游标
cursor = conn.cursor() # 执行SQL,并返回收影响行数
effect_row = cursor.execute("select * from test1") # 有参数存储过程
cursor.callproc('p2',args=('egon6',99)) # 等价于cursor.execute("call p1()")
# delimiter //
# CREATE PROCEDURE p2(IN p_in1 VARCHAR(20),IN p_in2 int)
# BEGIN
# INSERT into test1(name,grade) values(p_in1,p_in2);
# commit;
# END //
# delimiter ;
# 获取执行完存储的参数,参数@开头
cursor.execute("select @_p2_0,@_p2_1;") #@p2_0代表第一个参数,@p2_1代表第二个参数,即返回值
row_1 = cursor.fetchone()
print(row_1) # '@_p2_0': 'egon6', '@_p2_1': 99}
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
使用with简化连接过程
每次都连接关闭很麻烦,使用上下文管理,简化连接过程
import pymysql
import contextlib
# 定义上下文管理器,连接后自动关闭连接
@contextlib.contextmanager
def mysql():
mysql_connect_dict={
'host':'127.0.0.1',
'port':3306,
'user':'yycenter',
'password':'qwe123',
'db':'testmysql',
'charset':'utf8'
}
# 连接数据库
# conn = pymysql.connect(**mysql_connect_dict)
# 指定以dict形式返回,默认以元祖形式
conn = pymysql.connect(**mysql_connect_dict,cursorclass=pymysql.cursors.DictCursor)
print(conn) cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
try:
yield cursor
finally:
conn.commit()
cursor.close()
conn.close() # 执行sql
with mysql() as cursor:
print(cursor)
row_count = cursor.execute("select * from test1")
row_1 = cursor.fetchone()
print (row_count, row_1) # 8 {'id': 1, 'name': 'aa', 'grade': 99}
使用POOLDB连接mysql
import pymysql
from DBUtils.PooledDB import PooledDB
from utils.mylog_set import mylog
from utils.time_tool import run_time
from conf import settings def escape_quotes(val):
'转换单引号和双引号'
if isinstance(val, str):
return val.replace("'", "\\\'")
return val def stitch_sequence(seq=None, is_field=True, suf=None):
'''
序列拼接方法, 用于将序列拼接成字符串
- :seq: 拼接序列
- :suf: 拼接后缀(默认使用 ",")
- :is_field: 是否为数据库字段序列
'''
if seq is None:
raise Exception("Parameter seq is None")
suf = suf or ","
res = str()
for item in seq:
res += '`%s`%s' % (item, suf) if is_field else '%s%s' % (item, suf)
return res[:-len(suf)] class MysqlUtil(object):
"""
简便的数据库操作
初始化参数如下:
- :creator: 创建连接对象(默认: pymysql)
- :host: 连接数据库主机地址(默认: localhost)
- :port: 连接数据库端口(默认: 3306)
- :user: 连接数据库用户名(默认: None), 如果为空,则会抛异常
- :password: 连接数据库密码(默认: None), 如果为空,则会抛异常
- :database: 连接数据库(默认: None), 如果为空,则会抛异常
- :chatset: 编码(默认: utf8)
初始化该数据库下所有表的信息
""" def __init__(self, creator=pymysql, host=settings.mysqldb.get("host"), port=3306, user=settings.mysqldb.get("user"), password=settings.mysqldb.get("password"),
database=settings.mysqldb.get("database"), charset="utf8"):
if host is None:
raise ValueError("Parameter [host] is None.")
if port is None:
raise ValueError("Parameter [port] is None.")
if user is None:
raise ValueError("Parameter [user] is None.")
if password is None:
raise ValueError("Parameter [password] is None.")
if database is None:
raise ValueError("Parameter [database] is None.")
self.logger = mylog
# 执行初始化
self._config = dict({
"creator": creator, "charset": charset, "host": host, "port": port,
"user": user, "password": password, "database": database
})
self._database = database
self._table = None
self._pool = None
self._init_connect()
self._init_params() def __del__(self):
'重写类被清除时调用的方法'
if self._cursor:
self._cursor.close()
if self._conn:
self._conn.close() def commit(self):
# 提交
self._conn.commit() def rollback(self):
# 回滚
self._conn.rollback() def _init_connect(self):
'初始化连接'
try:
if self._pool is None:
self._pool = PooledDB(
**self._config,
mincached=5, # 启动时开启的闲置连接数量(缺省值 0 以为着开始时不创建连接)
maxcached=20, # 连接池中允许的闲置的最多连接数量(缺省值 0 代表不闲置连接池大小)
maxshared=20, # 共享连接数允许的最大数量(缺省值 0 代表所有连接都是专用的)如果达到了最大数量,被请求为共享的连接将会被共享使用
maxusage=100) # 单个连接的最大允许复用次数(缺省值 0 或 False 代表不限制的复用).当达到最大数时,连接会自动重新连接(关闭和重新打开)
# 获得连接池
self._conn = self._pool.connection()
# 建立连接
self._cursor = self._conn.cursor(
cursor=pymysql.cursors.DictCursor) # 使用字典方式
self.logger.info("[{0}] 数据库初始化成功。".format(self._database))
except Exception as e:
self.logger.info.error(e) @run_time
def execute_query(self, sql=None, args=(), single=False):
'''执行查询 SQL 语句
- :sql: sql 语句
- :single: 是否查询单个结果集,默认False
'''
try:
if sql is None:
raise Exception("Parameter sql is None.")
self.logger.debug(
"[{}] SQL >>> [{}] args =[{}]" .format(
self._database, sql, args))
self._cursor.execute(sql, args)
return self._cursor.fetchone() if single else self._cursor.fetchall() except Exception as e:
self.logger.error(e) @run_time
def execute_update(self, sql=None, args=()):
'''执行更新 SQL 语句
- :sql: sql 语句
'''
try:
if sql is None:
raise Exception("Parameter sql is None.")
self.logger.debug("[%s] SQL >>> [%s]" % (self._database, sql))
result = self._cursor.execute(sql, args)
return result
except Exception as e:
self.logger.error(e)
self._conn.rollback() def _init_params(self):
'初始化参数'
self._table_dict = {}
self._information_schema_columns = []
self._table_column_dict_list = {}
self._init_table_dict_list()
self._init_table_column_dict_list() def _init_information_schema_columns(self):
"查询 information_schema.`COLUMNS` 中的列"
sql = """ SELECT COLUMN_NAME
FROM information_schema.`COLUMNS`
WHERE TABLE_SCHEMA='information_schema' AND TABLE_NAME='COLUMNS'
"""
result_list = self.execute_query(sql)
# self.logger.debug(result_list)
column_list = [r['COLUMN_NAME'] for r in result_list]
self.logger.debug('column_list:>>> {}.'.format(column_list))
self._information_schema_columns = column_list def _init_table_dict(self, table_name):
'初始化表'
if not self._information_schema_columns:
self._init_information_schema_columns()
stitch_str = stitch_sequence(self._information_schema_columns)
sql = """ SELECT %s FROM information_schema.`COLUMNS`
WHERE TABLE_SCHEMA='%s' AND TABLE_NAME='%s'
""" % (stitch_str, self._database, table_name)
column_list = self.execute_query(sql)
column_dict = {}
for column in column_list:
column_dict[column["COLUMN_NAME"]] = column self._table_dict[table_name] = column_dict def _init_table_dict_list(self):
"初始化表字典对象" sql = "SELECT TABLE_NAME FROM information_schema.`TABLES` WHERE TABLE_SCHEMA='%s'" % (
self._database)
table_list = self.execute_query(sql)
self._table_dict = {t['TABLE_NAME']: {} for t in table_list}
self.logger.debug('_table_dicts {}'.format(self._table_dict))
for table in [t['TABLE_NAME'] for t in table_list]:
self._init_table_dict(table) def _init_table_column_dict_list(self):
'''初始化表字段字典列表'''
"""
example:{'test1': ['id', 'name', 'grade']
"""
for table, column_dict in self._table_dict.items():
column_list = [column for column in column_dict.keys()]
self._table_column_dict_list[table] = column_list
self.logger.debug(
"table_dict info: {}".format(
self._table_column_dict_list)) # 根据表自动创建参数字典
def create_params(self, table, args={}):
col_list = self._table_column_dict_list[table]
params = {}
for k in col_list:
if args.__contains__(k):
params[k] = args[k]
return params def _parse_result(self, result):
'用于解析单个查询结果,返回字典对象'
if result is None:
return None
obj = {key: value for key, value in zip(self._column_list, result)}
return obj def _parse_results(self, results):
'用于解析多个查询结果,返回字典列表对象'
if results is None:
return None
objs = [self._parse_result(result) for result in results]
return objs def _get_primary_key(self, table_name):
'获取表对应的主键字段'
if self._table_dict.get(table_name) is None:
raise Exception(table_name, "is not exist.")
for column, column_dict in self._table_dict[table_name].items():
if column_dict["COLUMN_KEY"] == "PRI":
return column def _get_table_column_list(self, table_name=None):
'查询表的字段列表, 将查询出来的字段列表存入 __fields 中'
return self._table_column_dict_list[table_name] def _check_table_name(self, table_name):
'''验证 table_name 参数'''
if table_name is None:
raise Exception("Parameter [table_name] is None.")
else:
self._table = table_name
self._column_list = self._table_column_dict_list[self._table] def count(self, table_name=None):
'''统计记录数'''
self._check_table_name(table_name)
sql = "SELECT count(*) FROM %s" % (self._table)
result = self.execute_query(sql, True)
return result[0] @run_time
def executemany(self, sql, args):
# 批量执行
try:
self.logger.debug('executemany sql:{}'.format(sql))
return self.cursor.executemany(sql, args)
except Exception as e:
self.close()
raise e # 执行sql,参数一:table,参数二:查询列'col1,col2' 参数三:参数字典{'字段1':'值1','字段2':'值2'}
def queryByTable(self, table, col='*', cond_dict={}):
# self.execute(sql, args)
self._check_table_name(table)
cond_dict = self.create_params(table, cond_dict)
cond_stmt = ' and '.join(['%s=%%s' % k for k in cond_dict.keys()])
# del_sql = 'DELETE FROM %(table)s where %(cond_stmt)s'
if not cond_dict:
query_sql = 'select %(col)s FROM %(table)s'
else:
query_sql = 'select %(col)s FROM %(table)s where %(cond_stmt)s' # 执行sql,参数一:sql
def queryBySql(self, query_sql):
# self.execute(sql, args)
'''验证 table_name 参数'''
if query_sql is None:
raise Exception("Parameter [query_sql] is None.")
return self.execute_query(query_sql) def insertByTable(self, table_name=None, obj={}):
'''保存方法
- @param table_name 表名
- @param obj 对象
- @return 影响行数
("test1", {'name': 'x', 'grade': 99}
'''
self._check_table_name(table_name)
if obj is None:
obj = {}
primary_key = self._get_primary_key(self._table)
if primary_key not in obj.keys():
obj[primary_key] = None
stitch_str = stitch_sequence(obj.keys())
# print(stitch_str)
value_list = []
for key, value in obj.items():
if self._table_dict[self._table][key]["COLUMN_KEY"] != "PKI":
value = "null" if value is None else '"%s"' % value
value_list.append(escape_quotes(value))
stitch_value_str = stitch_sequence(value_list, False) sql = 'INSERT INTO `%s` (%s) VALUES(%s)' % (
self._table, stitch_str, stitch_value_str)
return self.execute_update(sql) def deleteByTable(self, table_name=None, cond_dict={}):
'''删除
- @param table_name 表名
- @param cond_dict = {}: #参数二:用于where条件,如 where 字段3=值3 and 字段4=值4,格式{'字段3':'值3','字段4':'值4'}
- @return 影响行数
'''
self._check_table_name(table_name) cond_dict = self.create_params(table_name, cond_dict)
cond_stmt = ' and '.join(["%s=%%s" % (k) for k in cond_dict.keys()])
# del_sql = 'DELETE FROM %(table)s where %(cond_stmt)s'
if not cond_dict:
del_sql = 'DELETE FROM %(table_name)s'
else:
del_sql = 'DELETE FROM %(table_name)s where %(cond_stmt)s' return self.execute_update(
del_sql % locals(), tuple(cond_dict.values())) def updateByTable(self, table, column_dict={}, cond_dict={}):
# 更新,参数一:表名,参数二用于set 字段1=值1,字段2=值2...格式:{'字段1':'值1','字段2':'值2'},
# 参数三:用于where条件,如 where 字段3=值3 and 字段4=值4,格式{'字段3':'值3','字段4':'值4'}
self._check_table_name(table) column_dict = self.create_params(table, column_dict)
cond_dict = self.create_params(table, cond_dict)
set_stmt = ','.join(['%s=%%s' % k for k in column_dict.keys()])
cond_stmt = ' and '.join(['%s=%%s' % k for k in cond_dict.keys()])
if not cond_dict:
upd_sql = 'UPDATE %(table)s set %(set_stmt)s'
else:
upd_sql = 'UPDATE %(table)s set %(set_stmt)s where %(cond_stmt)s'
args = tuple(column_dict.values()) + tuple(cond_dict.values()) # 合并成1个
return self.execute_update(upd_sql % locals(), args) class Page(object):
'分页对象' def __init__(self, page_num=1, page_size=10, count=False):
'''
Page 初始化方法
- @param page_num 页码,默认为1
- @param page_size 页面大小, 默认为10
- @param count 是否包含 count 查询
'''
# 当前页数
self.page_num = page_num if page_num > 0 else 1
# 分页大小
self.page_size = page_size if page_size > 0 else 10
# 总记录数
self.total = 0
# 总页数
self.pages = 1
# 起始行(用于 mysql 分页查询)
self.start_row = (self.page_num - 1) * self.page_size
# 结束行(用于 mysql 分页查询)
self.end_row = self.start_row + self.page_size if __name__ == '__main__':
sql1 = MysqlUtil()
使用pymysql的更多相关文章
- pyMysql
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb ...
- Python 3.x 连接数据库(pymysql 方式)
==================pymysql=================== 由于 MySQLdb 模块还不支持 Python3.x,所以 Python3.x 如果想连接MySQL需要安装 ...
- Python中操作mysql的pymysql模块详解
Python中操作mysql的pymysql模块详解 前言 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持 ...
- 杂项之pymysql连接池
杂项之pymysql连接池 本节内容 本文的诞生 连接池及单例模式 多线程提升 协程提升 后记 1.本文的诞生 由于前几天接触了pymysql,在测试数据过程中,使用普通的pymysql插入100W条 ...
- Python3中使用PyMySQL连接Mysql
Python3中使用PyMySQL连接Mysql 在Python2中连接Mysql数据库用的是MySQLdb,在Python3中连接Mysql数据库用的是PyMySQL,因为MySQLdb不支持Pyt ...
- Python之路-python(mysql介绍和安装、pymysql、ORM sqlachemy)
本节内容 1.数据库介绍 2.mysql管理 3.mysql数据类型 4.常用mysql命令 创建数据库 外键 增删改查表 5.事务 6.索引 7.python 操作mysql 8.ORM sqlac ...
- python pymysql和orm
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同. 1. 安装 管理员打开cmd,切换到python的安装路径,进入到Scripts目录下(如:C:\Users\A ...
- python成长之路【第十三篇】:Python操作MySQL之pymysql
对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎 ...
- (转)pymysql 连接mysql数据库---不支持中文解决
往数据库里插入中文时出现异常:UnicodeEncodeError: 'latin-1' codec can't encode characters 就是编码的问题,pymysql默认的编码是lati ...
- 循序渐进Python3(十)-- 1 -- pymysql
使用pymsql 模块操作数据库 #!/usr/bin/env python , ),()]), user='root', passwd='123456', db='test')# 创建游标curso ...
随机推荐
- 2018.12.31 NOIP训练 偶数个5(简单数论)
传送门 对于出题人zxyoizxyoizxyoi先%\%%为敬题目需要龟速乘差评. 题意简述:5e55e55e5组数据,给出n,请你求出所有n位数中有偶数个5的有多少,n≤1e18n\le1e18n≤ ...
- 使用express框架和mongoose在MongoDB删除数据
使用remove()删除数据 remove({},function(err,doc){}) // 删除所有数据 remove({age:18},function(err,doc){}); //删除指 ...
- Le Chapitre IV
J'avais ainsi appris une seconde chose très importante: C'est que sa planète d'origine était à peine ...
- Mybatis-Plus 实战完整学习笔记(六)------select测试一
查询方法(3.0.3) 1.查询一个员工的数据 @Test public void selectMethod() throws SQLException { // 根据ID获取一个对象的数据 Empl ...
- 第25章:MongoDB-文档存储[理解]
① 将文档插入到MongoDB的时候,文档是按照插入的顺序,依次在磁盘上相邻保存 因此,一个文档变大了,原来的位置要是放不下这个文档了,就需要把这个文档移动到集合的另外一个位置,通常是最后,能放下这个 ...
- Android: Custom View和include标签的区别
Custom View, 使用的时候是这样的: <com.example.home.alltest.view.MyCustomView android:id="@+id/customV ...
- (最短路)Silver Cow Party --POJ--3268
题目链接: http://poj.org/problem?id=3268 题意: 先求出所有牛到x的最短路,再求出x到所有牛的最短路,两者相加取最大值(单向图)(可以用迪杰斯特拉,SPFA) 迪杰斯特 ...
- Curl工具的使用
Curl命令可以通过命令行的方式,执行Http请求.在Elasticsearch中有使用的场景,因此这里研究下如何在windows下执行curl命令. 工具下载 在官网处下载工具包:http:// ...
- codeblock快捷键使用
•在编辑区按住右键可拖动代码,省去拉滚动条之麻烦:相关设置:Mouse Drag Scrolling. •Ctrl+D可复制当前行或选中块. •可拖动选中块使其移动到新位置,按住Ctrl则为复制到新位 ...
- 数据统计--union all 执行多条sql
需求--统计hive某张表type字段不同取值的数据量 我们已知某张表的type的取值是1,2,3,4,5,想要统计不同type的数据量,并清晰的展现出来.可以通过union all 的方式,sql如 ...