kafka的几个简单操作
怎么安装解压kafka这里就不多说了,从配置文件说起
我这里搭建的是三节点集群 master slave1 slave2
修改server.properties 文件
把自己本地安装的zookeeper配置上

还有这个地方broker.id 我这里 master slave1 slave2 分别对于1 2 3,下图是以slave1的为例子

slave1的server.properties参考配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker.
broker.id= ############################# Socket Server Settings ############################# # The port the socket server listens on
port= # Hostname the broker will bind to. If not set, the server will bind to all interfaces
host.name=192.168.241.141 # Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for "host.name" if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set,
# it will publish the same port that the broker binds to.
#advertised.port=<port accessible by clients> # The number of threads handling network requests
num.network.threads= # The number of threads doing disk I/O
num.io.threads= # The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes= # The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes= # The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes= ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files
log.dirs=/home/hadoop/app/kafka/kafka-logs # The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions= # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir= ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# . Durability: Unflushed data may be lost if you are not using replication.
# . Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# . Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages= # The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms= ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log. # The minimum age of a log file to be eligible for deletion
log.retention.hours= # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes= # The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes= # The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms= # By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false export HBASE_MANAGES_ZK=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true
############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=master:,slave1:,slave2: # Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=
生成启动文件start.sh

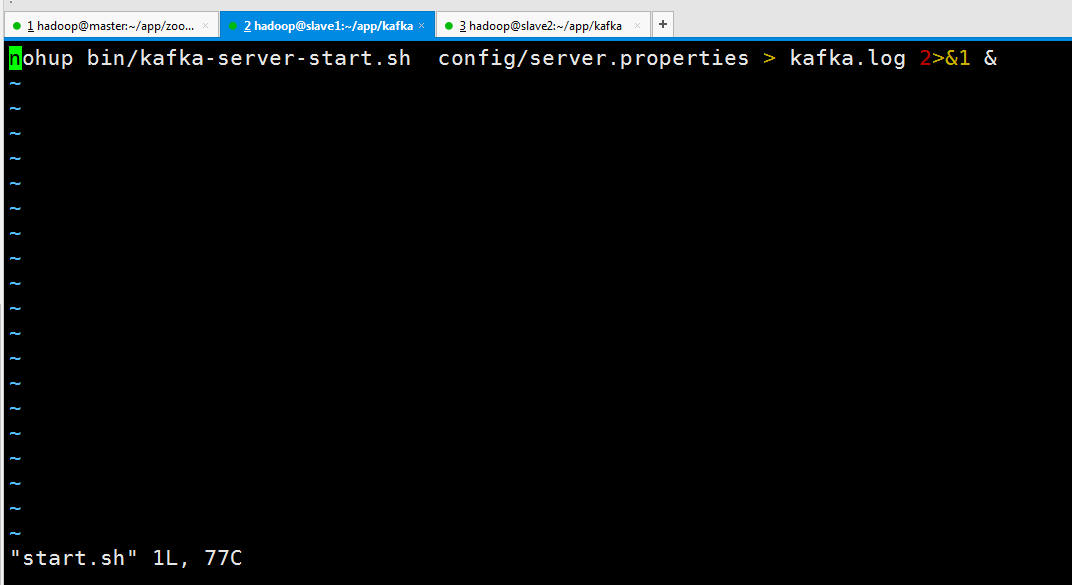
nohup bin/kafka-server-start.sh config/server.properties > kafka.log >& &
其他两节点也一样。
现在分别启动三个节点在zookeeper



再启动kafka (slave1 slave2也一样)
创建topic操作,并且查看里面的topic
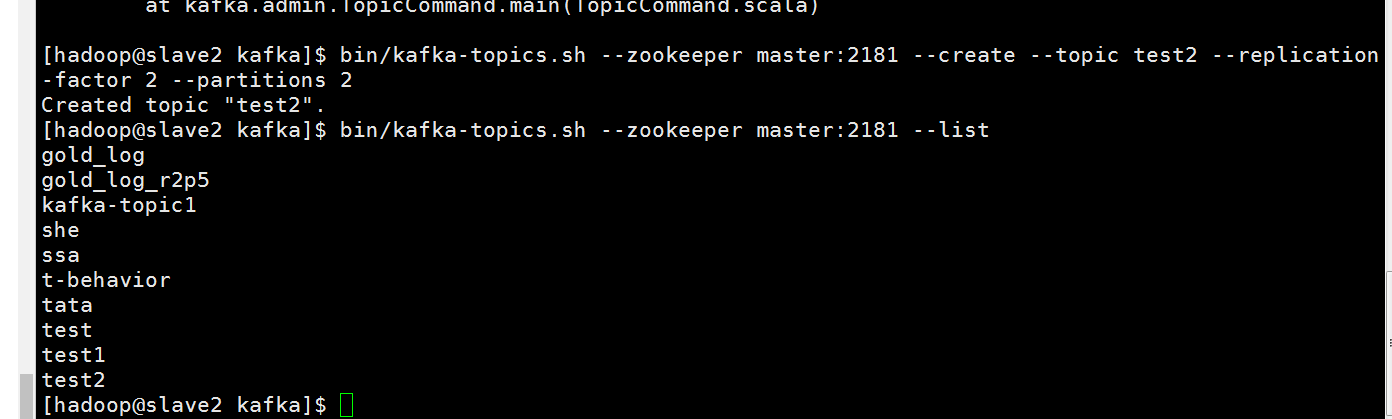
可以到zookeeper里面看看


通过describe命令查看topic是怎么存储的

bin/kafka-topics.sh --zookeeper master: --describe --topic test2
开启kafka consumer

./bin/kafka-console-consumer.sh --zookeeper master: --topic test2
开启kafka producer

./bin/kafka-console-producer.sh --broker-list slave2: --topic test2
在producer 敲人一下字母

可以在consumer这边看到

kafka的几个简单操作的更多相关文章
- Kafka学习笔记-Java简单操作
Maven依赖包: <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka ...
- Erlang 编写 Kafka 客户端之最简单入门
Erlang 编写 Kafka 客户端之最简单入门 费劲周折,终于测通了 erlang 向kafka 发送消息,使用了ekaf 库,参考: An advanced but simple to use, ...
- x01.MagicCube: 简单操作
看最强大脑,发现魔方还是比较好玩的,便买了一个,对照七步还原法,居然也能成功还原. 为什么不写一个魔方程序呢?在网上找了找,略作修改,进行简单操作,还是不错的,其操作代码如下: protected o ...
- js简单操作Cookie
贴一段js简单操作Cookie的代码: //获取指定名称的cookie的值 function getCookie(objName) { var arrStr = document.cookie.spl ...
- GitHub学习心得之 简单操作
作者:枫雪庭 出处:http://www.cnblogs.com/FengXueTing-px/ 欢迎转载 前言 本文对Github的基本操作进行了总结, 主要基于以下文章: http://gitre ...
- Linq对XML的简单操作
前两章介绍了关于Linq创建.解析SOAP格式的XML,在实际运用中,可能会对xml进行一些其它的操作,比如基础的增删该查,而操作对象首先需要获取对象,针对于DOM操作来说,Linq确实方便了不少,如 ...
- Linux 中 Vi 编辑器的简单操作
Linux 中 Vi 编辑器的简单操作 Vi 编辑器一共有3种模式:命名模式(默认),尾行模式,编辑模式.3种模式彼此需要切换. 一.进入 Vi 编辑器的的命令 vi filename //打开或新 ...
- python(pymysql)之mysql简单操作
一.mysql简单介绍 说到数据库,我们大多想到的是关系型数据库,比如mysql.oracle.sqlserver等等,这些数据库软件在windows上安装都非常的方便,在Linux上如果要安装数据库 ...
- ZooKeeper系列3:ZooKeeper命令、命令行工具及简单操作
问题导读1.ZooKeeper包含哪些常用命令?2.通过什么命令可以列出服务器 watch 的详细信息?3.ZooKeeper包含哪些操作?4.ZooKeeper如何创建zookeeper? 常用命令 ...
随机推荐
- RCC 和 RTC
RCC是STM32的时钟控制器,可开启或关闭各总线的时钟,在使用各外设功能必须先开启其对应的时钟,没有这个时钟内部的各器件就不能运行.RTC是STM32内部集成的一个简单的时钟(计时用),如果不用就关 ...
- :nth-of-type(n) 与 :nth-child(n) 区别
:nth-of-type(n):选择器匹配同类型中的第n个同级兄弟元素. :nth-child(n):选择器匹配父元素中的第n个子元素.
- spring boot 2 返回Date 格式化问题
以前 返回数据把Date 转成 long的时间毫秒数.现在是格式化成了字符串. 默认的结果:"createDate": "2018-09-06T10:04:25.000 ...
- Redis 基础命令
1. 进入redis目录,启动redis cd src ./redis-server 2. 进入redis目录,启动redis客户端 cd src ./redis-cli 3. info命令 4. ...
- Golang 端口复用测试
先给出结论: 同一个进程,使用一个端口,然后连接关闭,大约需要30s后才可再次使用这个端口. 测试 首先使用端口9001连接服务端,发送数据,然后关闭连接,接着再次使用端口9001连接服务端,如果连接 ...
- hanlp源码解析之中文分词算法详解
词图 词图指的是句子中所有词可能构成的图.如果一个词A的下一个词可能是B的话,那么A和B之间具有一条路径E(A,B).一个词可能有多个后续,同时也可能有多个前驱,它们构成的图我称作词图. 需要稀疏2维 ...
- Spring Cloud(Dalston.SR5)--Feign 声明式REST客户端
Spring Cloud 对 Feign 进行了封装,集成了 Ribbon 并结合 Eureka 可以实现客户端的负载均衡,Spring Cloud 实现的 Feign 客户端类名为 LoadBala ...
- 用monit监控mongodb,崩溃后自动重启mongdb
什么是monit Monit是一个跨平台的用来监控Unix/linux系统(比如Linux.BSD.OSX.Solaris)的工具.Monit特别易于安装,而且非常轻量级(只有500KB大小),并且不 ...
- mongodb morphia删除数组中指定条件的数据
先看mongodb操作: db.test.update({"msgid":170},{"$pull":{"msg":{"comti ...
- jQuery 筛选器 链式编程操作
$('#i1').next() 下一个标签$('#i1').nextAll() 兄弟标签中,所有下一个标签$('#i1').nextUntil('#ii1') 兄弟标签中,从下一个标签到id为ii1的 ...