Hadoop系列之(二):Hadoop集群部署
1. Hadoop集群介绍
Hadoop集群部署,就是以Cluster mode方式进行部署。
Hadoop的节点构成如下:
HDFS daemon: NameNode, SecondaryNameNode, DataNode
YARN damones: ResourceManager, NodeManager, WebAppProxy
MapReduce Job History Server
2. 集群部署
本次测试的分布式环境为:Master 1台 (test166),Slave 1台(test167)
2.1 首先在各节点上安装Hadoop
安装方法参照 Hadoop系列之(一):Hadoop单机部署
2.2 在各节点上设置主机名
# cat /etc/hosts
10.86.255.166 test166
10.86.255.167 test167
2.3 在各节点上设置SSH无密码登录
2.4 设置Hadoop的环境变量
# vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.7.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/Hadoop
让设置生效
# source /etc/profile
2.5 Hadoop设定
2.5.1 在Master节点的设定文件中指定Slave节点
# vi etc/hadoop/slaves
test167
2.5.2 Master,Slave所有节点共同设定
# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://test166:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.0/tmp</value>
</property>
</configuration>
# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.5.3 在各节点指定HDFS文件存储的位置(默认是/tmp)
Master节点: namenode
创建目录并赋予权限
# mkdir -p /usr/local/hadoop-2.7.0/tmp/dfs/name
# chmod -R 777 /usr/local/hadoop-2.7.0/tmp
# vi etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop-2.7.0/tmp/dfs/name</value>
</property>
Slave节点:datanode
创建目录并赋予权限
# mkdir -p /usr/local/hadoop-2.7.0/tmp/dfs/data
# chmod -R 777 /usr/local/hadoop-2.7.0/tmp
# vi etc/hadoop/hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop-2.7.0/tmp/dfs/data</value>
</property>
2.5.4 YARN设定
Master节点: resourcemanager
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>test166</value>
</property>
</configuration>
Slave节点: nodemanager
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>test166</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.5.5 Master上启动job history server,Slave节点上指定
Slave节点:
# vi etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>test166:10020</value>
</property>
2.5.6 格式化HDFS(Master,Slave)
# hadoop namenode -format
2.5.7 在Master上启动daemon,Slave上的服务会一起启动
启动HDFS
# sbin/start-dfs.sh

启动YARN
# sbin/start-yarn.sh

启动job history server
# sbin/mr-jobhistory-daemon.sh start historyserver
确认
Master节点:
# jps

Slave节点:
# jps
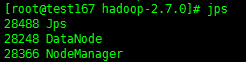
2.5.8 创建HDFS
# hdfs dfs -mkdir /user
# hdfs dfs -mkdir /user/test22
2.5.9 拷贝input文件到HDFS目录下
# hdfs dfs -put etc/hadoop /user/test22/input
查看
# hdfs dfs -ls /user/test22/input
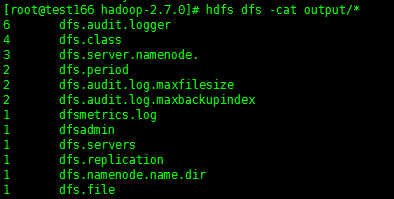
2.5.10 执行hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test22/input output 'dfs[a-z.]+'
确认执行结果
# hdfs dfs -cat output/*
3. 后记
本次集群部署主要是为了测试验证,生产环境中的HA,安全等设定,接下来会进行介绍。
Hadoop系列之(二):Hadoop集群部署的更多相关文章
- Hadoop 系列(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部 ...
- Dubbo+zookeeper构建高可用分布式集群(二)-集群部署
在Dubbo+zookeeper构建高可用分布式集群(一)-单机部署中我们讲了如何单机部署.但没有将如何配置微服务.下面分别介绍单机与集群微服务如何配置注册中心. Zookeeper单机配置:方式一. ...
- zookeeper学习与实战(二)集群部署
上一篇介绍了单机版zookeeper安装,这种情况一般用于开发测试.如果是生产环境建议用分布式集群部署,防止单点故障,增加zookeeper服务的高可用. [环境介绍] 三台机器:192. ...
- rocketmq学习(二) rocketmq集群部署与图形化控制台安装
1.rocketmq图形化控制台安装 虽然rocketmq为用户提供了使用命令行管理主题.消费组以及broker配置的功能,但对于不够熟练的非运维人员来说,命令行的管理界面还是较难使用的.为此,我们可 ...
- (六)hadoop系列之__hadoop分布式集群环境搭建
配置hadoop(master,slave1,slave2) 说明: NameNode: master DataNode: slave1,slave2 ------------------------ ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- Kubernetes 二进制部署(二)集群部署(多 Master 节点通过 Nginx 负载均衡)
0. 前言 紧接上一篇,本篇文章我们尝试学习多节点部署 kubernetes 集群 并通过 haproxy+keepalived 实现 Master 节点的负载均衡 1. 实验环境 实验环境主要为 5 ...
- Ocelot + Consul的demo(二)集群部署
把服务A和服务B接口分别部署在两个ip地址上 修改 services.json文件, { "encrypt": "7TnJPB4lKtjEcCWWjN6jSA==&quo ...
- Docker(二十一)-Docker Swarm集群部署
介绍 Swarm 在 Docker 1.12 版本之前属于一个独立的项目,在 Docker 1.12 版本发布之后,该项目合并到了 Docker 中,成为 Docker 的一个子命令.目前,Swarm ...
- Docker Swarm集群部署
一.系统环境 1)服务器环境 节点名称 IP 操作系统 内核版本 manager 172.16.60.95 CentOs7 4.16.1-1.el7.elrepo.x86_64 node-01 172 ...
随机推荐
- H5 以及 CSS3
<!DOCTYPE html> <html> <head> <style> *{ padding:0; margin:0; } header{ disp ...
- Windows一个文件夹下面最多可以放多少文件
一个文件夹下面最多可以放多少文件 这个问题其实我也不知道,不过我们可以来进行个测试,看看文件夹下面最多能放多少个文件. 那么怎么来测试这样一个问题呢,很显然我们一个个的去建立文件是不现实的,没那么多时 ...
- html5 canvas高级贝塞尔曲线运动动画(好吧这一篇被批的体无完肤!都说看不懂了!没办法加注释了!当然数学不好的我也没办法了,当然这还涉及到一门叫做计算机图形学的学科)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- C++ 修饰符类型
C++ 修饰符类型 C++ 允许在 char.int 和 double 数据类型前放置修饰符.修饰符用于改变基本类型的含义,所以它更能满足各种情境的需求. 下面列出了数据类型修饰符: signed u ...
- Saving Tang Monk II
题目链接:http://hihocoder.com/contest/acmicpc2018beijingonline/problem/1 AC代码: #include<bits/stdc++.h ...
- win10下安装MinGW-w64 - for 32 and 64 bit Windows
对于不经常使用c语言的同学来说,只需要安装MinGW-w64 - for 32 and 64 bit Windows,就可以使用GCC在命令行对c源码进行编译. 首先打开命令行检查自己是否已经安装了g ...
- imperva 更改agent的注册密码
imperva agent 在注册到网关的时候显示账号密码错误 如下图 这是一个数据库审计的设备由于当初最开始实施的时候并不是我安装的,所以账号密码我也不清楚,客户留的账号密码也不确定.因此导致账号密 ...
- Kafka入门经典教程【转】
问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程序?4.数据传输的事务定义有哪三种?5.Kafka判断一个节点是否活着有 ...
- _findfirst和_findnext
1.首先是_finddata结构体,用于存储文件信息的结构体. 2._findfirst函数:long _findfirst(const char *, struct _finddata_t *); ...
- OI 助手 | 简洁快速的 OI 工具箱 (原 竞赛目录生成)
原竞赛目录生成 (4.0 版本前) 开发者:abc2237512422 OI 助手是一个轻量简洁的 OI 工具箱.你可以使用它来快速进行 OI 竞赛中一些繁琐的操作,例如生成竞赛目录.对拍.它为你省去 ...