43.scrapy爬取链家网站二手房信息-1
首先分析:
目的:采集链家网站二手房数据
1.先分析一下二手房主界面信息,显示情况如下: url = https://gz.lianjia.com/ershoufang/pg1/
显示总数据量为27589套,但是页面只给返回100页的数据,每页30条数据,也就是只给返回3000条数据。
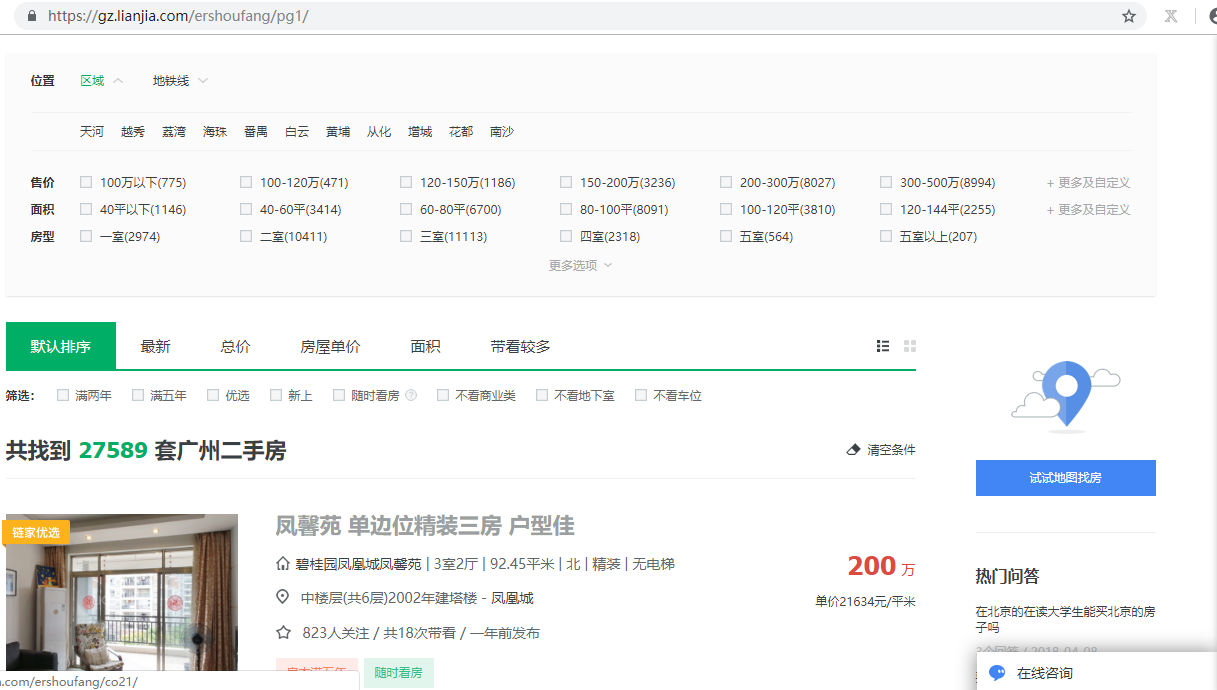
2.再看一下筛选条件的情况: 100万以下(775):https://gz.lianjia.com/ershoufang/pg1p1/(p1是筛选条件参数,pg1是页面参数) 页面返回26页信息
100万-120万(471):https://gz.lianjia.com/ershoufang/pg1p2/ 页面返回16页信息 以此类推也就是网站只给你返回查看最多100页,3000条的数据,登陆的话情况也是一样的情况。
3.采集代码如下:
这个是 linjia.py 文件,这里需要注意的问题就是 setting里要设置
ROBOTSTXT_OBEY = False,不然页面不给返回数据。
# -*- coding: utf-8 -*-
import scrapy class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
allowed_domains = ['gz.lianjia.com']
start_urls = ['https://gz.lianjia.com/ershoufang/pg1/'] def parse(self, response): #获取当前页面url
link_urls = response.xpath("//div[@class='info clear']/div[@class='title']/a/@href").extract()
for link_url in link_urls:
# print(link_url)
yield scrapy.Request(url=link_url,callback=self.parse_detail)
print('*'*100) #翻页
for i in range(1,101):
url = 'https://gz.lianjia.com/ershoufang/pg{}/'.format(i)
# print(url)
yield scrapy.Request(url=url,callback=self.parse) def parse_detail(self,response): title = response.xpath("//div[@class='title']/h1[@class='main']/text()").extract_first()
print('标题: '+ title)
dist = response.xpath("//div[@class='areaName']/span[@class='info']/a/text()").extract_first()
print('所在区域: '+ dist)
contents = response.xpath("//div[@class='introContent']/div[@class='base']")
# print(contents)
house_type = contents.xpath("./div[@class='content']/ul/li[1]/text()").extract_first()
print('房屋户型: '+ house_type)
floor = contents.xpath("./div[@class='content']/ul/li[2]/text()").extract_first()
print('所在楼层: '+ floor)
built_area = contents.xpath("./div[@class='content']/ul/li[3]/text()").extract_first()
print('建筑面积: '+ built_area)
family_structure = contents.xpath("./div[@class='content']/ul/li[4]/text()").extract_first()
print('户型结构: '+ family_structure)
inner_area = contents.xpath("./div[@class='content']/ul/li[5]/text()").extract_first()
print('套内面积: '+ inner_area)
architectural_type = contents.xpath("./div[@class='content']/ul/li[6]/text()").extract_first()
print('建筑类型: '+ architectural_type)
house_orientation = contents.xpath("./div[@class='content']/ul/li[7]/text()").extract_first()
print('房屋朝向: '+ house_orientation)
building_structure = contents.xpath("./div[@class='content']/ul/li[8]/text()").extract_first()
print('建筑结构: '+ building_structure)
decoration_condition = contents.xpath("./div[@class='content']/ul/li[9]/text()").extract_first()
print('装修状况: '+ decoration_condition)
proportion = contents.xpath("./div[@class='content']/ul/li[10]/text()").extract_first()
print('梯户比例: '+ proportion)
elevator = contents.xpath("./div[@class='content']/ul/li[11]/text()").extract_first()
print('配备电梯: '+ elevator)
age_limit =contents.xpath("./div[@class='content']/ul/li[12]/text()").extract_first()
print('产权年限: '+ age_limit)
try:
house_label = response.xpath("//div[@class='content']/a/text()").extract_first()
except:
house_label = ''
print('房源标签: ' + house_label)
# decoration_description = response.xpath("//div[@class='baseattribute clear'][1]/div[@class='content']/text()").extract_first()
# print('装修描述 '+ decoration_description)
# community_introduction = response.xpath("//div[@class='baseattribute clear'][2]/div[@class='content']/text()").extract_first()
# print('小区介绍: '+ community_introduction)
# huxing_introduce = response.xpath("//div[@class='baseattribute clear']3]/div[@class='content']/text()").extract_first()
# print('户型介绍: '+ huxing_introduce)
# selling_point = response.xpath("//div[@class='baseattribute clear'][4]/div[@class='content']/text()").extract_first()
# print('核心卖点: '+ selling_point)
# 以追加的方式及打开一个文件,文件指针放在文件结尾,追加读写!
with open('text', 'a', encoding='utf-8')as f:
f.write('\n'.join(
[title,dist,house_type,floor,built_area,family_structure,inner_area,architectural_type,house_orientation,building_structure,decoration_condition,proportion,elevator,age_limit,house_label]))
f.write('\n' + '=' * 50 + '\n')
print('-'*100)
4.这里采集的是全部,没设置筛选条件,只返回100也数据。
采集数据情况如下:
这里只采集了15个字段信息,其他的数据没采集。
采集100页,算一下拿到了2704条数据。


43.scrapy爬取链家网站二手房信息-1的更多相关文章
- 44.scrapy爬取链家网站二手房信息-2
全面采集二手房数据: 网站二手房总数据量为27650条,但有的参数字段会出现一些问题,因为只给返回100页数据,具体查看就需要去细分请求url参数去请求网站数据.我这里大概的获取了一下筛选条件参数,一 ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Python爬取链家二手房源信息
爬取链家网站二手房房源信息,第一次做,仅供参考,要用scrapy. import scrapy,pypinyin,requests import bs4 from ..items import L ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
随机推荐
- MySQL5.7 GTID 浅析
https://yq.aliyun.com/articles/68441 摘要: # GTID 简介 GTID (global transaction identifier)在MySQL5.6时引入, ...
- delphi absolute 应用实例
procedure TForm1.Button1Click(Sender: TObject); var i1,i2:Integer; b:..] of Byte absolute i1; // b 在 ...
- TensorFlow Saver的使用方法
我们经常在训练完一个模型之后希望保存训练的结果,这些结果指的是模型的参数,以便下次迭代的训练或者用作测试.Tensorflow针对这一需求提供了Saver类. Saver类提供了向checkpoint ...
- C#实现根据日期计算星期
/// <summary> /// 根据日期返回 星期(返回结果为英文) /// </summary> /// <param name="date"& ...
- gitlab 10.8.1 迁移
参考官网: https://docs.gitlab.com/ee/raketasks/backup_restore.html Backing up and restoring GitLab 及 ...
- 我的ehcache笔记
我的EhcacheUtils类: package com.shinho.bi.utils; import org.ehcache.CacheManager; import org.ehcache.co ...
- Spring4.0之四:Meta Annotation(元注解)
Spring框架自2.0开始添加注解的支持,之后的每个版本都增加了更多的注解支持.注解为依赖注入,AOP(如事务)提供了更强大和简便的方式.这也导致你要是用一个相同的注解到许多不同的类中去.这篇文章介 ...
- Java-Runoob-高级教程-实例-方法:11. Java 实例 – enum 和 switch 语句使用
ylbtech-Java-Runoob-高级教程-实例-方法:11. Java 实例 – enum 和 switch 语句使用 1.返回顶部 1. Java 实例 - enum 和 switch 语句 ...
- 廖雪峰Java3异常处理-2断言和日志-4使用Log4j
1.Log4j Log4j是目前最流行的日志框架.有两个版本 1.x:Log4j 2.x:Log4j2 Log4j下载地址https://www.apache.org/dyn/closer.lua/l ...
- 廖雪峰Java2-2数据封装-2构造方法
在2-2-1中,创建1个实例需要3步 Person ming = new Person(); ming.setName(" 小明 "); ming.setAge(16); 问题:能 ...