Scrapy框架--代理和cookie
如何发起post请求?
代理和cookie:
cookie:豆瓣网个人登录,获取该用户个人主页这个二级页面的页面数据。
如何发起post请求?
一定要对start_requests方法进行重写。
1. Request()方法中给method属性赋值成post
2. FormRequest()进行post请求的发送
简单测试:
在爬虫文件中
import scrapy class PostdemoSpider(scrapy.Spider):
name = 'postDemo'
#allowed_domains = ['www.baidu.com']
start_urls = ['https://fanyi.baidu.com/sug']
def start_requests(self):
print('start_request')
data ={'kw':'dog'} for url in self.start_urls:
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
def parse(self, response):
print(response.text)
在settings配置
然后执行:

cookie:豆瓣网个人登录,获取该用户个人主页这个二级页面的页面数据。
先创建一个工程doubanPro

cd 到创建的目录下

----------
创建爬虫文件
1. 在命令行下 cd 进入工程所在文件夹
2.scrapy genspider 爬虫文件的名称 起始url

爬虫文件 douban.py
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
# allowed_domains = ['www.douban.com']
start_urls = ['https://accounts.douban.com/login']
# 重写start_requests方法
def start_requests(self):
for url in self.start_urls:
# 排除验证码的情况 将请求参数封装到字典
data = {
'source': 'movie',
'redir': 'https://movie.douban.com /',
'form_email': '836342406@qq.com',
'form_password': 'douban836342406,.',
'login': '登录' }
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
# 针对个人主页数据进行解析操作
def parseBySecondPage(self,response):
fp = open('second.html','w',encoding='utf-8')
fp.write(response.text) def parse(self, response):
# 登录成功后的页面进行存储
fp = open('main.html','w',encoding='utf-8')
fp.write(response.text)
# 获取当前用户的个人主页
url = 'https://www.douban.com/people/188197188/'
yield scrapy.Request(url=url,callback=self.parseBySecondPage)
执行

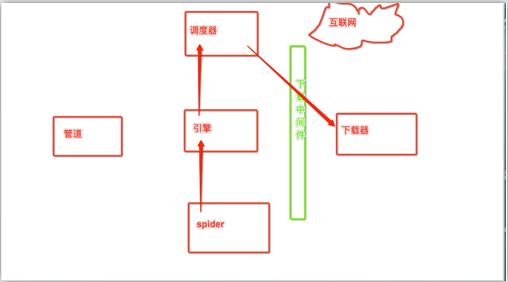
代理操作-代理ip的更换
下载中间件作用:拦截请求,可以将请求的ip进行更换。
流程:
1. 下载中间件类的自制定
a) object
b) 重写process_request(self,request,spider)的方法
2. 配置文件中进行下载中间价的开启
新建一个proxyPro的工程
建立proxyDemo.py爬虫文件
1、下载中间件类的自定义
proxyDemo.py
import scrapy
class ProxydemoSpider(scrapy.Spider):
name = 'proxyDemo'
#allowed_domains = ['www.baidu.com']
start_urls = ['https://www.baidu.com/s?wd=ip'] def parse(self, response):
fp = open('proxy.html','w',encoding='utf-8')
fp.write(response.text)
middlewares.py
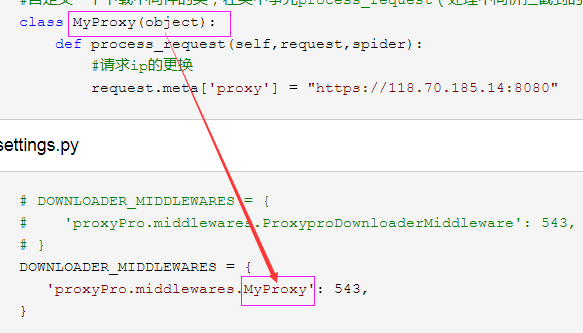
from scrapy import signals #自定义一个下载中间件的类,在类中事先process_request(处理中间价拦截到的请求)方法
class MyProxy(object):
def process_request(self,request,spider):
#请求ip的更换
request.meta['proxy'] = "https://118.70.185.14:8080" 代理ip------------>"https://118.70.185.14:8080"

settings.py
# DOWNLOADER_MIDDLEWARES = {
# 'proxyPro.middlewares.ProxyproDownloaderMiddleware': 543,
# }
DOWNLOADER_MIDDLEWARES = {
'proxyPro.middlewares.MyProxy': 543,
}
Scrapy框架--代理和cookie的更多相关文章
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- Scrapy框架之代理和cookie
Cookie 是在 HTTP 协议下,服务器或脚本可以维护客户工作站上信息的一种方式.Cookie 是由 Web 服务器保存在用户浏览器(客户端)上的小文本文件,它可以包含有关用户的信息.无论何时用户 ...
- scrapy 伪装代理和fake_userAgent的使用
伪装浏览器代理 在爬取网页是有些服务器对请求过滤的不是很高可以不用ip来伪装请求直接将自己的浏览器信息给伪装也是可以的. 第一中方法: 1.在setting.py文件中加入以下内容,这是一些浏览器的头 ...
- 爬虫之代理和cookie的处理
代理操作 代理的目的 为解决ip被封的情况 什么是代理 代理服务器:fiddler 为什么使用代理可以改变请求的ip 本机的请求会先发送给代理服务器,代理服务器会接受本机发送过来的请求(当前请求对应的 ...
- Jmeter的代理和cookie/session/Token令牌认证
Jmeter的代理服务器 1.启动Jmeter: 2.“测试计划”中添加“线程组”: 3.“工作台”中添加“HTTP代理服务器”: 4.配置代理服务器:Global Settings下面的端口配置:9 ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里 ...
- scrapy框架使用笔记
目前网上有很多关于scrapy的文章,这里我主要介绍一下我在开发中遇到问题及一些技巧: 1,以登录状态去爬取(带cookie) -安装内容: brew install phantomjs (MAC上) ...
随机推荐
- 原型设计工具——axure认识与使用
原型设计工具——axure认识与使用 10款原型设计工具推荐 pasting
- for循环计算li的个数
今天有一段代码 在ie6下面显示 我检查了一下代码,发现每for循环一次,就会重新计算li的个数,会拖慢运行速度,所以改成以下代码,ie6就正常了
- 面向对象的轮播js
1.自执行函数的前后要加分号 案例: ;(function(){})(); 2.面向对象的最大优势节省了许多内存 正式开写面向对象的轮播: <!DOCTYPE html> <html ...
- 1124 Raffle for Weibo Followers (20 分)
1124 Raffle for Weibo Followers (20 分) John got a full mark on PAT. He was so happy that he decided ...
- 1122 Hamiltonian Cycle (25 分)
1122 Hamiltonian Cycle (25 分) The "Hamilton cycle problem" is to find a simple cycle that ...
- Linux配置IP,安装yum源
ip addr 查看IP地址 通过 ip 命令加参数 addr 则是查看当前网卡的配置信息, 从下图中可以看出, 当前系统的 ens33 网卡并没有 ipv4 及 ipv6, 没有 ip地址 则只能说 ...
- NPF or NPCAP service is not installed
"NPF or NPCAP service is not installed" "could not start local server process:GNS3&qu ...
- IP网络设计
一.总体规划 网络设计的分层思想 按照网络设计的分层思想,通常将网络分为:核心层.汇聚层和接入层三个部分.这三部分在功能上有明显差别 ,因此在IP设计上,有必要对这三个部分区别对待. 二.核心层 核心 ...
- CS229 3.用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- Android数据传递,使用广播BroadcastReceiver;
Android数据传递有很多种,Intent意图传递或使用Bundle去传递,接口监听回调传递数据,也可以把数据保存起来,使用的时候去读取等等等...,"当你知道足够多的数据传递的方式之后, ...