Django Rest Framework源码剖析(七)-----分页
| 一、简介 |
分页对于大多数网站来说是必不可少的,那你使用restful架构时候,你可以从后台获取数据,在前端利用利用框架或自定义分页,这是一种解决方案。当然django rest framework提供了分页组件,让我们可以更灵活的进行分页。
django rest framework提供了三种分页组件:
- PageNumberPagination:普通分页,查看第n页,每个页面显示n条数据
- LimitOffsetPagination: 基于位置的分页,在第n个位置,向后查看n条数据,和数据库的sql语句中的limit offset类似,参数offet代表位置,limit代表取多少条数据。
- CursorPagination:游标分页,意思就是每次返回当前页、上一页、下一页,并且每次的上一页和下一页的url是不规则的
| 二、每个分页组件使用 |
这里我们使用之前的模型,如果没有在setting中注册django rest framework 请注册它,为了方便我们查看分页,配置项在INSTALLED_APPS:
1.PageNumberPagination类分页
settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'rest_framework', #注册DRF
]
models.py
from django.db import models class UserInfo(models.Model):
user_type_choice = (
(1,"普通用户"),
(2,"会员"),
)
user_type = models.IntegerField(choices=user_type_choice)
username = models.CharField(max_length=32,unique=True)
password = models.CharField(max_length=64)
group = models.ForeignKey(to='UserGroup',null=True,blank=True)
roles = models.ManyToManyField(to='Role') class UserToken(models.Model):
user = models.OneToOneField(to=UserInfo)
token = models.CharField(max_length=64) class UserGroup(models.Model):
"""用户组"""
name = models.CharField(max_length=32,unique=True) class Role(models.Model):
"""角色"""
name = models.CharField(max_length=32,unique=True)
urls.py
urlpatterns = [
# url(r'^api/v1/auth', views.AuthView.as_view()),
# url(r'^api/v1/order', views.OrderView.as_view()),
url(r'^api/v1/roles', views.RoleView.as_view()), #分页示例1
url(r'^api/v1/userinfo', views.UserinfoView.as_view()),
url(r'^api/v1/group/(?P<xxx>\d+)', views.GroupView.as_view(),name='gp'),
# url(r'^api/(?P<version>[v1|v2]+)/user', views.UserView.as_view(),name="user_view"),
]
本次我们使用roles来作为示例,并且为了更好的显示,此次会用到django rest framework 的响应(Response),后续会介绍,下面是对角色视图的序列化,这个已经在前面的序列化篇章中说明如下:
from rest_framework import serializers
from rest_framework.response import Response #使用DRF自带的响应页面更美观
class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all()
res=RolesSerializer(instance=roles,many=True) #instance接受queryset对象或者单个model对象,当有多条数据时候,使用many=True,单个对象many=False
return Response(res.data)
访问:http://127.0.0.1:8000/api/v1/roles,显示出所有的角色,如下:
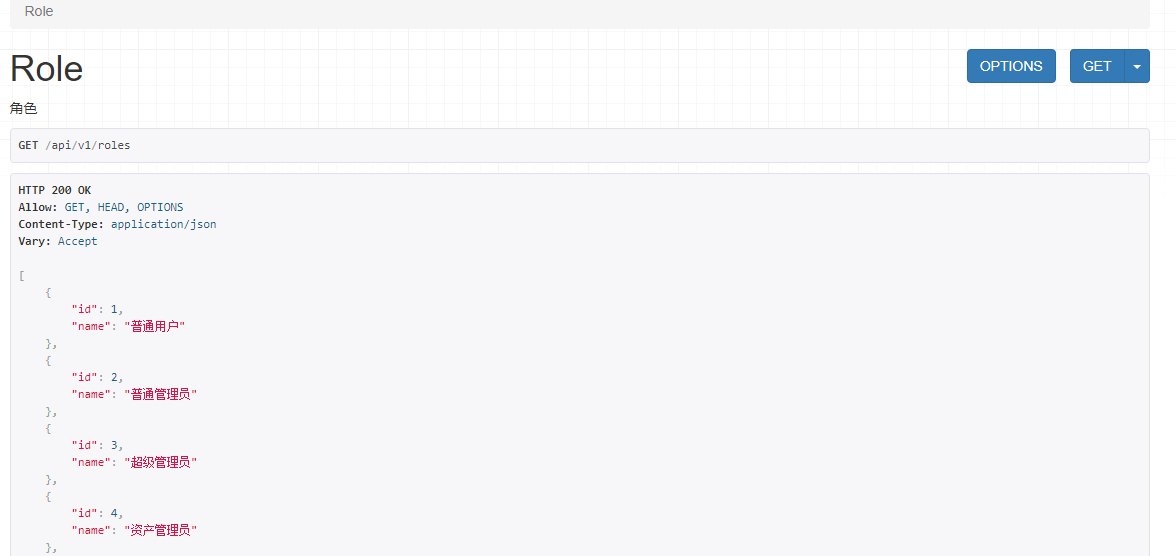
加入分页后的角色视图:
from rest_framework import serializers
from rest_framework.response import Response #使用DRF自带的响应页面更美观
from rest_framework.pagination import PageNumberPagination
class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all() # 获取所有数据 pg_obj=PageNumberPagination() # 实例化分页类
pg_res=pg_obj.paginate_queryset(queryset=roles,request=request,view=self)
# 获取分页数据,参数一 分页的数据,QuerySet类型,请求request,分页的视图,self代表自己
res=RolesSerializer(instance=pg_res,many=True) # 对分完页码的数据进行序列化
return Response(res.data)
同时,我们还需要配置每页显示的数据条数,在settings.py中:
REST_FRAMEWORK = {
"DEFAULT_PARSER_CLASSES": ["rest_framework.parsers.JSONParser", "rest_framework.parsers.JSONParser"],# 全局解析器配置
"PAGE_SIZE":2,#配置每页显示多少条数据
}
此时我们访问:http://127.0.0.1:8000/api/v1/roles?page=1,则显示第一页,访问http://127.0.0.1:8000/api/v1/roles?page=2则显示第二页,如下图:
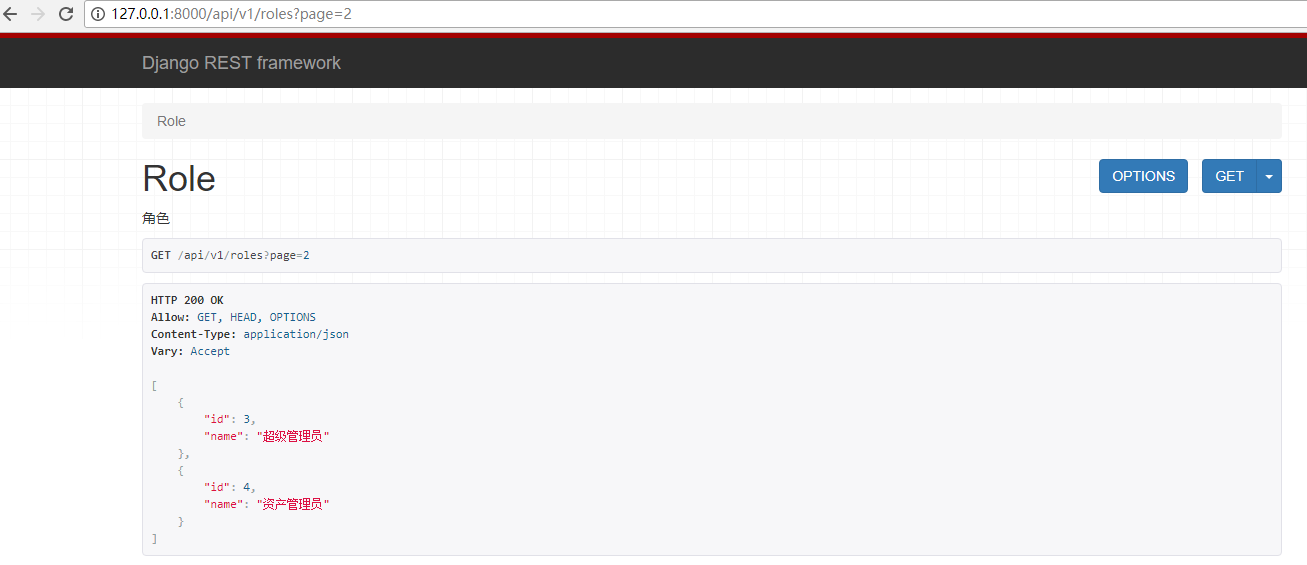
但是一般情况我们需要自己定义分页类,来定制更多的功能,示例:
自定义分页,更多的定制功能:
from rest_framework import serializers
from rest_framework.response import Response #使用DRF自带的响应页面更美观
from rest_framework.pagination import PageNumberPagination class Mypagination(PageNumberPagination):
"""自定义分页"""
page_size=2 #默认每页显示个数配置
page_query_param = 'p' # 页面传参的key,默认是page
page_size_query_param='size' # 指定每页显示个数参数
max_page_size=4 # 每页最多显示个数配置,使用以上配置,可以支持每页可显示2~4条数据 class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all() # 获取所有数据 pg_obj=Mypagination() # 实例化分页类
pg_res=pg_obj.paginate_queryset(queryset=roles,request=request,view=self)
# 获取分页数据,参数一 分页的数据,QuerySet类型,请求request,分页的视图,self代表自己
res=RolesSerializer(instance=pg_res,many=True) # 对分完页码的数据进行序列化
return Response(res.data)
访问:http://127.0.0.1:8000/api/v1/roles?p=1&size=3,需要注意的是此时的分页参数已经重写,查看结果:
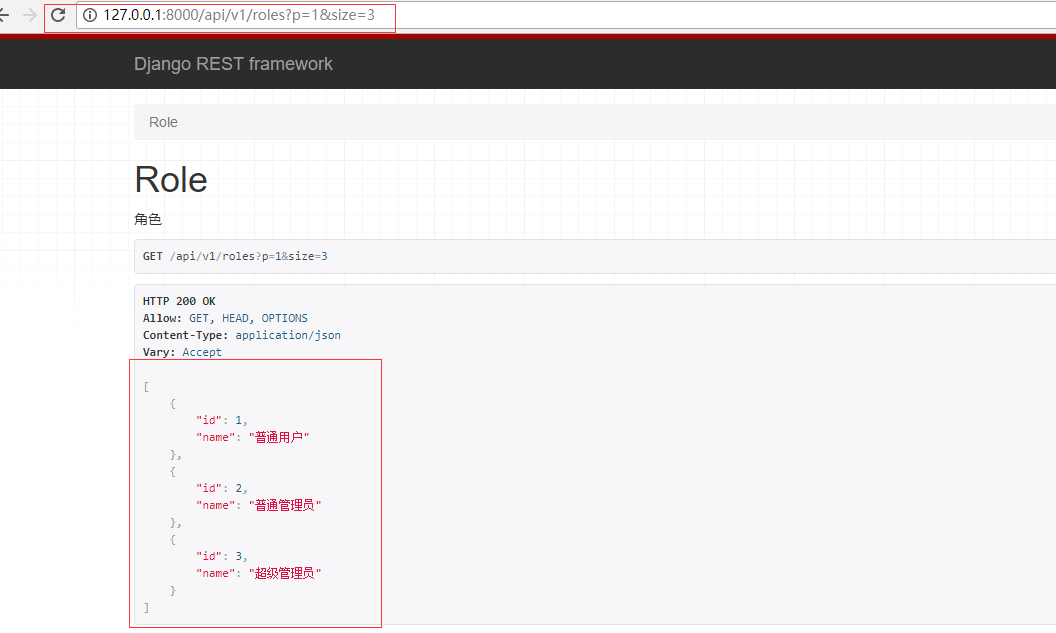
自带返回上一页下一页功能:
from rest_framework import serializers
from rest_framework.response import Response #使用DRF自带的响应页面更美观
from rest_framework.pagination import PageNumberPagination class Mypagination(PageNumberPagination):
"""自定义分页"""
page_size=2 #默认每页显示个数配置
page_query_param = 'p' # 页面传参的key,默认是page
page_size_query_param='size' # 指定每页显示个数参数
max_page_size=4 # 每页最多显示个数配置,使用以上配置,可以支持每页可显示2~4条数据 class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all() # 获取所有数据 pg_obj=Mypagination() # 实例化分页类
pg_res=pg_obj.paginate_queryset(queryset=roles,request=request,view=self)
# 获取分页数据,参数一 分页的数据,QuerySet类型,请求request,分页的视图,self代表自己
res=RolesSerializer(instance=pg_res,many=True) # 对分完页码的数据进行序列化
return pg_obj.get_paginated_response(res.data) # 使用分页自带的respose返回,具有上一页下一页功能
2.LimitOffsetPagination类分页
同样我们以角色视图做示例,通过自定义实现分页,示例:
from rest_framework import serializers
from rest_framework.response import Response #使用DRF自带的响应页面更美观
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination class MyLimitOffsetPagination(LimitOffsetPagination): default_limit = 2 #默认显示的个数
offset_query_param = "offset" #指定url中位置key值,其位置从0开始
limit_query_param = "limit" # 指定url中的偏移个数(显示个数)的key值
max_limit = 10 #最多显示(偏移)的个数 class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all() # 获取所有数据 pg_obj=MyLimitOffsetPagination() # 实例化分页类
pg_res=pg_obj.paginate_queryset(queryset=roles,request=request,view=self)
# 获取分页数据,参数一 分页的数据,QuerySet类型,请求request,分页的视图,self代表自己
res=RolesSerializer(instance=pg_res,many=True) # 对分完页码的数据进行序列化
return Response(res.data)
访问:http://127.0.0.1:8000/api/v1/roles?offset=1&limit=4(从第2个位置开始,查看4条数据),结果如下:
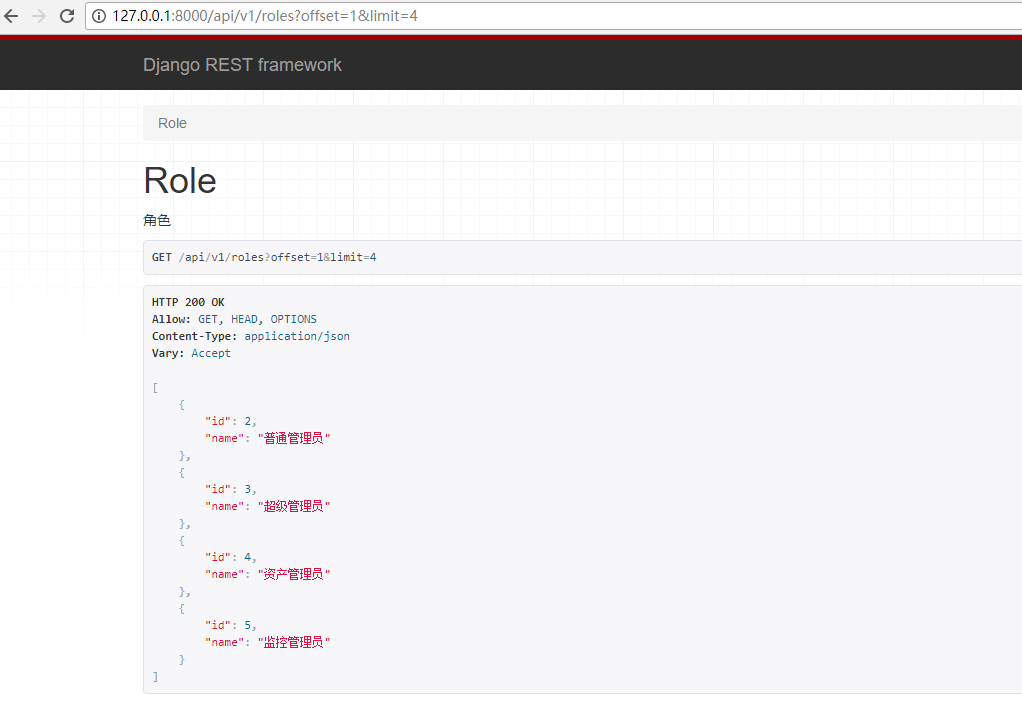
3.CursorPagination类实现分页(很少用)
示例:
from rest_framework import serializers
from rest_framework.response import Response #使用DRF自带的响应页面更美观
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination class MyCursorPagination(CursorPagination):
cursor_query_param = "cursor" #url获取分页的key
page_size = 2 #每页显示2个数据
ordering = 'id' #排序规则
page_size_query_param = 'size' #每页显示多少条参数配置
max_page_size = 5 #每页最多显示多少条数据
class RolesSerializer(serializers.Serializer): #定义序列化类
id=serializers.IntegerField() #定义需要提取的序列化字段,名称和model中定义的字段相同
name=serializers.CharField()
class RoleView(APIView):
"""角色"""
def get(self,request,*args,**kwargs):
roles=models.Role.objects.all() # 获取所有数据 pg_obj=MyCursorPagination() # 实例化分页类
pg_res=pg_obj.paginate_queryset(queryset=roles,request=request,view=self)
# 获取分页数据,参数一 分页的数据,QuerySet类型,请求request,分页的视图,self代表自己
res=RolesSerializer(instance=pg_res,many=True) # 对分完页码的数据进行序列化
return pg_obj.get_paginated_response(res.data)
访问http://127.0.0.1:8000/api/v1/roles,结果如下,从结果中可以看到下一页的url并不规则:
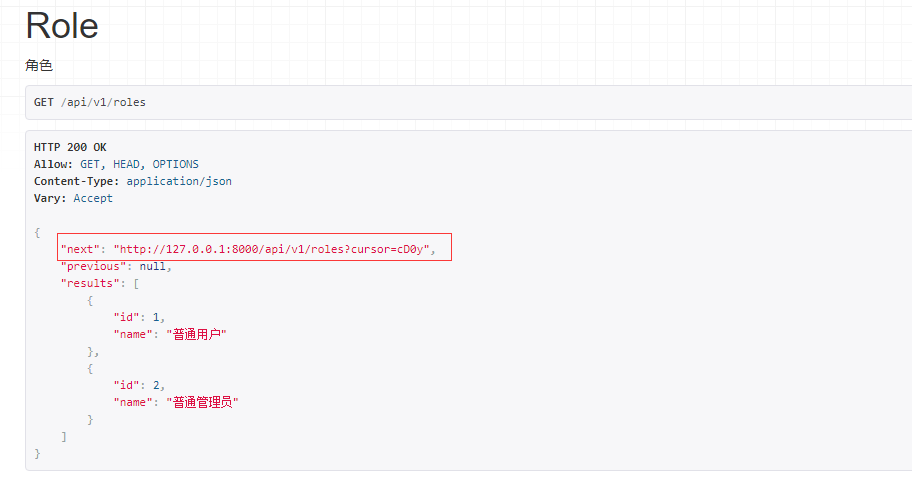
| 三、源码剖析 |
对于以上示例,你可以会有疑问,问什么配置上了一些类的属性就能有不同的效果呢?当然源码是有这些定制配置的,这里以PageNumberPagination分页进行说明,下面是PageNumberPagination的源码,可能稍微长,我们进行配置部分解读就好,其他部分和分页相关的逻辑这里就不过多介绍,解读部分请看注释:
class PageNumberPagination(BasePagination):
"""
A simple page number based style that supports page numbers as
query parameters. For example: http://api.example.org/accounts/?page=4
http://api.example.org/accounts/?page=4&page_size=100
"""
# The default page size.
# Defaults to `None`, meaning pagination is disabled.
page_size = api_settings.PAGE_SIZE #每页显示个数配置,可以在setting中配置,也可以在类里,当前类>全局(settings) django_paginator_class = DjangoPaginator # 本质使用django自带的分页组件 # Client can control the page using this query parameter.
page_query_param = 'page' # url中的页码key配置
page_query_description = _('A page number within the paginated result set.') # 描述 # Client can control the page size using this query parameter.
# Default is 'None'. Set to eg 'page_size' to enable usage.
page_size_query_param = None # url中每页显示个数的key配置
page_size_query_description = _('Number of results to return per page.') # Set to an integer to limit the maximum page size the client may request.
# Only relevant if 'page_size_query_param' has also been set.
max_page_size = None # 最多显示个数配置 last_page_strings = ('last',) template = 'rest_framework/pagination/numbers.html' # 渲染的模板 invalid_page_message = _('Invalid page.') # 页面不合法返回的信息,当然我们也可以自己定制 def paginate_queryset(self, queryset, request, view=None): # 获取分页数据
"""
Paginate a queryset if required, either returning a
page object, or `None` if pagination is not configured for this view.
"""
page_size = self.get_page_size(request) # 调用get_page_size 获取当前请求的每页显示数量
if not page_size:
return None paginator = self.django_paginator_class(queryset, page_size)
page_number = request.query_params.get(self.page_query_param, 1)
if page_number in self.last_page_strings:
page_number = paginator.num_pages try:
self.page = paginator.page(page_number)
except InvalidPage as exc:
msg = self.invalid_page_message.format(
page_number=page_number, message=six.text_type(exc)
)
raise NotFound(msg) if paginator.num_pages > 1 and self.template is not None:
# The browsable API should display pagination controls.
self.display_page_controls = True self.request = request
return list(self.page) def get_paginated_response(self, data):
return Response(OrderedDict([
('count', self.page.paginator.count),
('next', self.get_next_link()),
('previous', self.get_previous_link()),
('results', data)
])) def get_page_size(self, request):
if self.page_size_query_param:
try:
return _positive_int(
request.query_params[self.page_size_query_param],
strict=True,
cutoff=self.max_page_size
)
except (KeyError, ValueError):
pass return self.page_size def get_next_link(self):
if not self.page.has_next():
return None
url = self.request.build_absolute_uri()
page_number = self.page.next_page_number()
return replace_query_param(url, self.page_query_param, page_number) def get_previous_link(self):
if not self.page.has_previous():
return None
url = self.request.build_absolute_uri()
page_number = self.page.previous_page_number()
if page_number == 1:
return remove_query_param(url, self.page_query_param)
return replace_query_param(url, self.page_query_param, page_number) def get_html_context(self):
base_url = self.request.build_absolute_uri() def page_number_to_url(page_number):
if page_number == 1:
return remove_query_param(base_url, self.page_query_param)
else:
return replace_query_param(base_url, self.page_query_param, page_number) current = self.page.number
final = self.page.paginator.num_pages
page_numbers = _get_displayed_page_numbers(current, final)
page_links = _get_page_links(page_numbers, current, page_number_to_url) return {
'previous_url': self.get_previous_link(),
'next_url': self.get_next_link(),
'page_links': page_links
} def to_html(self):
template = loader.get_template(self.template)
context = self.get_html_context()
return template.render(context) def get_schema_fields(self, view):
assert coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`'
assert coreschema is not None, 'coreschema must be installed to use `get_schema_fields()`'
fields = [
coreapi.Field(
name=self.page_query_param,
required=False,
location='query',
schema=coreschema.Integer(
title='Page',
description=force_text(self.page_query_description)
)
)
]
if self.page_size_query_param is not None:
fields.append(
coreapi.Field(
name=self.page_size_query_param,
required=False,
location='query',
schema=coreschema.Integer(
title='Page size',
description=force_text(self.page_size_query_description)
)
)
)
return fields
| 四、使用总结 |
虽然对于分页来说,django rest framework 给我们提供了多种分页,但是最为常用的还是第一种PageNumberPagination,推荐使用。
而第二种LimitOffsetPagination,使用场景是当数据量比较大时候,只关心其中某一部分数据,推荐使用。
CursorPagination类型分页相对于PageNumberPagination有点在于,它避免了人为在url中自己传入参数进行页面的刷新(因为url不规则),缺点也显而易见只能进行上下页的翻阅。
Django Rest Framework源码剖析(七)-----分页的更多相关文章
- Django Rest Framework源码剖析(八)-----视图与路由
一.简介 django rest framework 给我们带来了很多组件,除了认证.权限.序列化...其中一个重要组件就是视图,一般视图是和路由配合使用,这种方式给我们提供了更灵活的使用方法,对于使 ...
- Django Rest Framework源码剖析(三)-----频率控制
一.简介 承接上篇文章Django Rest Framework源码剖析(二)-----权限,当服务的接口被频繁调用,导致资源紧张怎么办呢?当然或许有很多解决办法,比如:负载均衡.提高服务器配置.通过 ...
- Django Rest Framework源码剖析(六)-----序列化(serializers)
一.简介 django rest framework 中的序列化组件,可以说是其核心组件,也是我们平时使用最多的组件,它不仅仅有序列化功能,更提供了数据验证的功能(与django中的form类似). ...
- Django Rest Framework源码剖析(五)-----解析器
一.简介 解析器顾名思义就是对请求体进行解析.为什么要有解析器?原因很简单,当后台和前端进行交互的时候数据类型不一定都是表单数据或者json,当然也有其他类型的数据格式,比如xml,所以需要解析这类数 ...
- Django Rest Framework源码剖析(四)-----API版本
一.简介 在我们给外部提供的API中,可会存在多个版本,不同的版本可能对应的功能不同,所以这时候版本使用就显得尤为重要,django rest framework也为我们提供了多种版本使用方法. 二. ...
- Django Rest Framework源码剖析(二)-----权限
一.简介 在上一篇博客中已经介绍了django rest framework 对于认证的源码流程,以及实现过程,当用户经过认证之后下一步就是涉及到权限的问题.比如订单的业务只能VIP才能查看,所以这时 ...
- Django Rest Framework源码剖析(一)-----认证
一.简介 Django REST Framework(简称DRF),是一个用于构建Web API的强大且灵活的工具包. 先说说REST:REST是一种Web API设计标准,是目前比较成熟的一套互联网 ...
- Django REST framework 源码剖析
前言 Django REST framework is a powerful and flexible toolkit for building Web APIs. 本文由浅入深的引入Django R ...
- 跨站请求伪造(csrf),django的settings源码剖析,django的auth模块
目录 一.跨站请求伪造(csrf) 1. 什么是csrf 2. 钓鱼网站原理 3. 如何解决csrf (1)思路: (2)实现方法 (3)实现的具体代码 3. csrf相关的装饰器 (1)csrf_p ...
随机推荐
- Difference between nn.softmax & softmax_cross_entropy_with_logits & softmax_cross_entropy_with_logits_v2
nn.softmax 和 softmax_cross_entropy_with_logits 和 softmax_cross_entropy_with_logits_v2 的区别 You have ...
- python的函数(一)
摘要: python的函数(一)主要写函数的基础部分. 1,函数的好处 2,函数的定义与调用 1,函数的好处 函数应该有2个好处: 1,是降低代码的复杂度, 2,是减少代码量,避免重复的写相同的代码. ...
- python基础一数据类型之字典
摘要: python基础一数据类型之一字典,这篇主要讲字典. 1,定义字典 2,字典的基础知识 3,字典的方法 1,定义字典 1,定义1个空字典 dict1 = {} 2,定义字典 dict1 = d ...
- SqlServer为字段创建索引
语法:CREATE [索引类型] INDEX 索引名称ON 表名(列名) 创建索引实例: 聚簇索引 create clustered index index_name on table_name (c ...
- Nlog.Config:日志方法步骤
首先添加negut包Nlog.Config: 安装完毕以后,可以替换Nlog.config <?xml version="1.0" encoding="utf-8& ...
- python urllib库
python2和python3中的urllib urllib提供了一个高级的 Web 通信库,支持基本的 Web 协议,如 HTTP.FTP 和 Gopher 协议,同时也支持对本地文件的访问. 具体 ...
- Linux学习---linux下的彩蛋和各种有趣的命令
[原文]https://www.toutiao.com/i6596596897392099844/ screenfetch 一个显示系统信息和主题信息的命令 使用方法 输入screenfetch 效果 ...
- linux操作系统基础讲解
计算机的组成及功能: 现在市场上的计算机组成结构遵循冯 诺依曼体系,由CPU.内存.I/O设备,存储四大部分组成. CPU是整个计算机的核心部件,主要由运算器和控制器组成,它负责整个计算机的程序运行以 ...
- CreateEvent
事件对象就像一个开关:它只有两种状态---开和关.当一个事件处于”开”状态,我们称其为”有信号”否则称为”无信号”.可以在一个线程的执行函数中创建一个事件对象,然后观察它的状态,如果是”无信号”就让该 ...
- SDN2017 第二次实验作业
安装floodlight 参考链接:http://www.sdnlab.com/19189.html 从github下载源码,并编译安装 $ sudo apt-get install build-es ...