[BigData]关于Hadoop学习笔记第一天(PPT总结)(一)
适合大数据的分布式存储与计算平台
官方版本(1.0.4)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Yahoo内部使用的版本,发布过两次,已有的版本都放到了Apache上,后续不在继续发布,而是集中在Apache的版本上。
== HDFS ==


诉求:
Data processed by Google every month: 400 PB … in 2007
问题:
MapReduce+HDFS思想:
MapReduce 思想:
HDFS思想:




官方版本(2.4.1)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Hortonworks公司发行版本。
hadoop核心
资源管理调度系统
问题:怎样解决海量数据的存储?

HDFS的架构
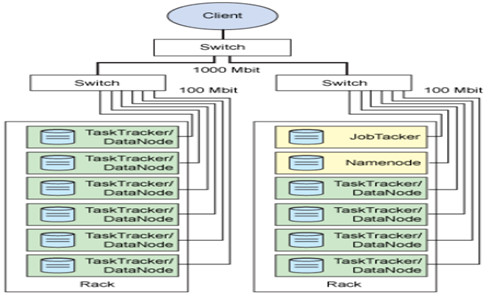
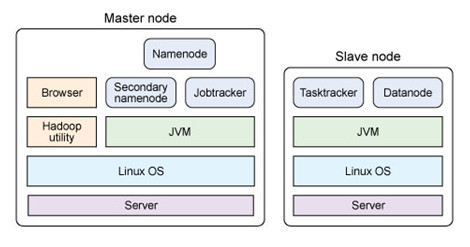
主从结构 主节点, namenode 从节点,有很多个: datanode namenode负责: 接收用户操作请求 维护文件系统的目录结构 管理文件与block之间关系,block与datanode之间关系 datanode负责: 存储文件 文件被分成block存储在磁盘上 为保证数据安全,文件会有多个副本

问题:怎样解决海量数据的计算?

hadoop1.0和hadoop2.0的对比

Hadoop部署方式
伪分布模式安装步骤
修改hadoop配置文件
1.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/
2.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
&
3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:9001</value>
</property>
</configuration>
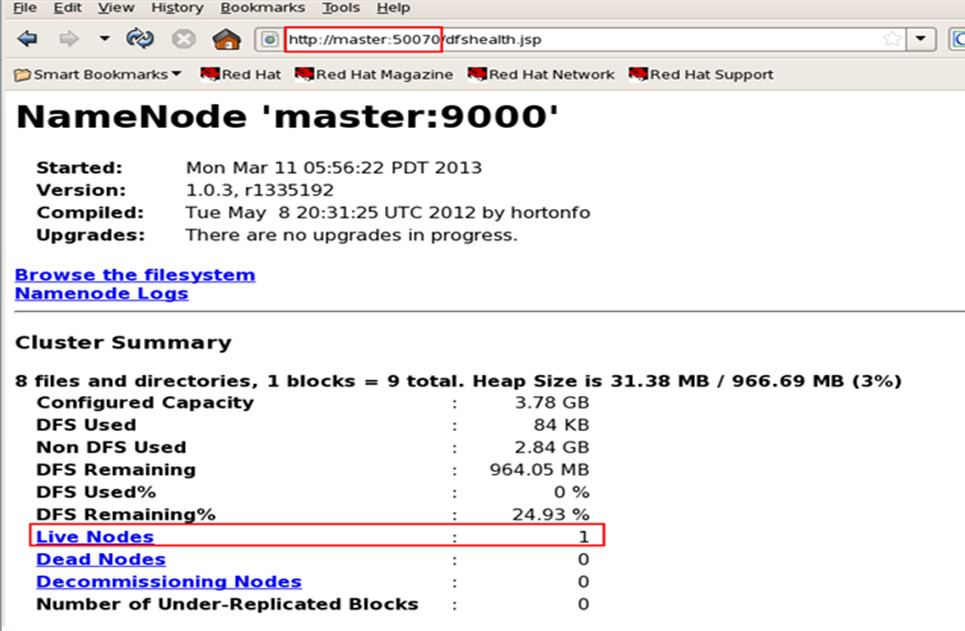
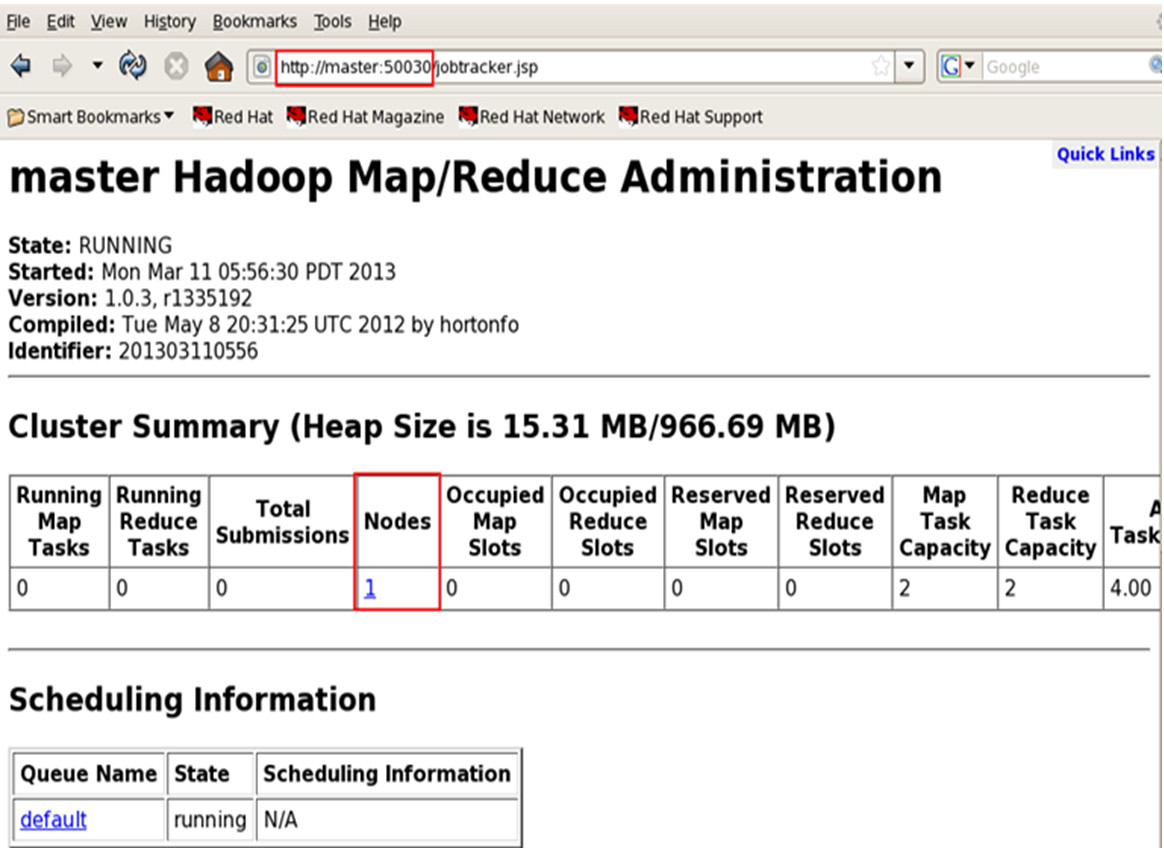
浏览hadoop
&
练习:搭建伪分布环境
思考题
常用linux命令

[BigData]关于Hadoop学习笔记第一天(PPT总结)(一)的更多相关文章
- [BigData]关于Hadoop学习笔记第二天(PPT总结)(一)
Plan: 分布式文件系统与HDFS HDFS体系结构与基本概念 HDFS的shell操作 java接口及常用api HADOOP的RPC机制 HDFS源码分析 远程debug 自己设计一分布式文件系 ...
- [BigData]关于Hadoop学习笔记第四天(PPT总结)(一)
课程安排 Partitioner编程** 自定义排序编程** Combiner编程** 常见的MapReduce算法** ---------------------------加深拓展-------- ...
- [BigData]关于Hadoop学习笔记第三天(PPT总结)(一)
课程安排 MapReduce原理*** MapReduce执行过程** 数据类型与格式*** Writable接口与序列化机制*** ---------------------------加深拓展- ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
- Hadoop学习笔记之HBase Shell语法练习
Hadoop学习笔记之HBase Shell语法练习 作者:hugengyong 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- Spring JdbcTemplate batchUpdate() example
In some cases, you may required to insert a batch of records into database in one shot. If you call ...
- memcached全面剖析–4. memcached的分布式算法
memcached的分布式 正如第1次中介绍的那样, memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能. 服务器端仅包括 第2次. 第3次 前坂介绍的内存存储功能,其实现 ...
- 在C#调用C++的DLL简析(一)——生成非托管dll
经过一晚上的折腾,还是下点决心将些许的心得写下来,以免以后重复劳动. C#与C/C++相 比,前者的优势在于UI,后者的优势在于算法,C++下的指针虽然恶心,若使用得当还是相当方便的,最重要的问题是, ...
- Display:Block
根据CSS规范的规定,每一个网页元素都有一个display属性,用于确定该元素的类型,每一个元素都有默认的display属性值,比如div元素,它的默认display属性值为“block”,成为“块级 ...
- 单个SWF文件loading加载详解(转)
通过带宽查看器,可以看到SWF中每帧所占带宽状况.另外,我们还可以在Flash发布设置中,选择生成体积报告. 勾选这一项之后,发布flash时,会自动在fla目录中生成一个名为”文件名 Report. ...
- Spring aop实现方式记录
原文地址:http://blog.csdn.net/moreevan/article/details/11977115 Spring提供了两种方式来生成代理对象: JDKProxy和Cglib,具体使 ...
- Mesos 配置项解析
Mesos 的 配置项 能够通过启动时候传递參数或者配置文件夹下文件的方式给出(推荐方式,一目了然). 分为三种类型:通用项(master 和 slave 都支持).仅仅有 master 支持的,以及 ...
- [Redux] Accessing Dispatch and State with Redux -- connect
If you have props and actions, you want one component to access those props and actions, one solutio ...
- Key Task
Problem Description The Czech Technical University is rather old - you already know that it celebrat ...
- xtrabackup原理2
XTRABACKUP备份原理实现细节——对淘宝数据库内核月报补充 前言 淘宝3月的数据库内核月报对xtrabackup的备份原理做了深入的分析,写的还是很不错.不过Inside君在看完之后,感觉没有对 ...