hadoop数据流转过程分析
hadoop:数据流转图(基于hadoop 0.18.3):通过一个最简单的例子来说明hadoop中的数据流转。
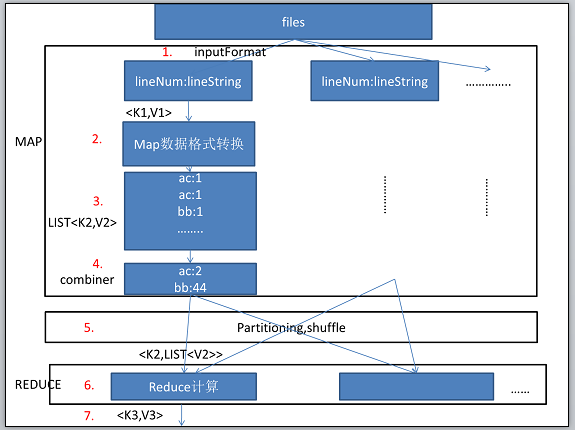
public void map(LongWritable key,Text Value,OutputCollector<Text,Inwritable> output,Reporter reporter){//output为map函数的输出。
String line = value.toString();//每行的值
StringTokenizer itr = new StringTokenizer(line);//根据空格分词
while(itr.hasMoreTokens()){
output.collect( new Text().set(itr.nextToken()),new IntWritable(1));//输出 ,key为单词,value为1.
}
}
public void reduce(Text key,Interator<InWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{
int sum = 0;
while(values.hasNext()){//求和
sum += values.next().get();
}
output.collect(key,new IntWritable(sum));//输出
}
hadoop数据流转过程分析的更多相关文章
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Struts2(三)——数据在框架中的数据流转问题
一款软件,无在乎对数据的处理.而B/S软件,一般都是用户通过浏览器客户端输入数据,传递到服务器,服务器进行相关处理,然后返回到指定的页面,进行相关显示,完成相关功能.这篇博客重点简述一下Struts2 ...
- 面向UI编程:ui.js 1.1 使用观察者模式完成组件之间数据流转,彻底分离组件之间的耦合,完成组件的高内聚
开头想明确一些概念,因为有些概念不明确会导致很多问题,比如你写这个框架为什么不去解决啥啥啥的问题,哎,心累. 什么是框架? 百度的解释:框架(Framework)是整个或部分系统的可重用设计,表现为一 ...
- 关系数据库数据与hadoop数据进行转换的工具 - Sqoop
Sqoop 本文所使用的Sqoop版本为1.4.6 1.官网 http://sqoop.apache.org 2.作用 A:可以把hadoop数据导入到关系数据库里面(e.g. Hive -> ...
- Hadoop数据读写原理
数据流 MapReduce作业(job)是客户端执行的单位:它包括输入数据.MapReduce程序和配置信息.Hadoop把输入数据划分成等长的小数据发送到MapReduce,称之为输入分片.Hado ...
- hadoop数据容易出现错误的地方
最近在搞关于数据分析的项目,做了一点总结. 下图是系统的数据流向.容易出现错误的地方.1.数据进入hadoop仓库有四种来源,这四种是最基本的数据,简称ods,original data source ...
- hadoop 数据采样
http://www.cnblogs.com/xuxm2007/archive/2012/03/04/2379143.html 原文地址如上: 关于Hadoop中的采样器 .为什么要使用采样器 在这个 ...
- Hadoop数据操作系统YARN全解析
“ Hadoop 2.0引入YARN,大大提高了集群的资源利用率并降低了集群管理成本.其在异构集群中是怎样应用的?Hulu又有哪些成功实践可以分享? 为了能够对集群中的资源进行统一管理和调度,Hado ...
- Hadoop 数据排序(一)
1.概述 1TB排序通常用于衡量分布式数据处理框架的数据处理能力.Terasort是Hadoop中的的一个排序作业.那么Terasort在Hadoop中是怎样实现的呢?本文主要从算法设计角度分析Ter ...
随机推荐
- js中的命名规范
在实际开发中规范的命名,不仅方便自己查看,理解变量的实际意义,而且在团队开发中也能提高开发效率. 下面将介绍javascript中的变量的命名规范: 1)首先,变量名要有实际意义,不建议使用单个的字母 ...
- 【AsyncTask整理 1】 AsyncTask几点要注意的地方
问题1:AsyncTask是多线程吗? 答:是. 问题2:AsyncTask与Handler相比,谁更轻量级? 答:通过看源码,发现AsyncTask实际上就是一个线程池,而网上的说法是AsyncTa ...
- iOS中的网络请求 和 网络监测
1.网络监测 //根据主机名判断网络是否连接 Reachability *reach = [Reachability reachabilityWithHostName:@"www.baidu ...
- 重构13-Extract Method Object(提取方法对象)
重构来自于Martin Fowler的重构目录.你可以在这里找到包含简介的原始文章. 在我看来,这是一个比较罕见的重构,但有时却终能派上用场.当你尝试进行提取方法的重构时,需要引入大量的方法.在一个 ...
- jQuery阻止事件冒泡的例子
下面给给各位朋友稍加整理了一jquery中阻止事件冒泡的一些例子,我们知道JQuery 提供了两种方式来阻止事件冒泡,但我们简单的利用它来做一些应用可能不深入或不理解,下面整理了更详细的方法,有兴趣的 ...
- mysql-完整性约束条件
PRIMARY : 主键 AUTO_INCREMENT : 自增长 FOREIGN KEY : 外键 NOT NULL : 非空 UNIQUE KEY : 唯一 DEFAULT : 默认值 主 ...
- jQuery过滤选择器:not()方法使用介绍
在jQuery的早期版本中,:not()筛选器只支持简单的选择器,说明我们传入到:not这个filter中的selector可以任意复杂,比如:not(div a) and :not(div,a) & ...
- codeforces Good Bye 2013 379D New Year Letter
题目链接:http://codeforces.com/problemset/problem/379/D [题目大意] 告诉你初始字符串S1.S2的长度和递推次数k, 使用类似斐波纳契数列的字符串合并的 ...
- 【转】华为Java编程军规,每季度代码验收标准
引言: 这个标准是衡量代码本身的缺陷,也是衡量一个研发人员本身的价值. 军规一:[避免在程序中使用魔鬼数字,必须用有意义的常量来标识.] 军规二:[明确方法的功能,一个方法仅完成一个功能.] 军规三: ...
- OpenShare:前所未有的开放性
客户总是面临一个选择:开放的企业门户产品 vs 封闭的企业门户产品 市场上大多数企业门户产品是自成一体的其实也就是封闭的,他们不能和企业目录集成,不能和Exchange集成,不能和SAP集成,不能和L ...