【学习笔记】分布式Tensorflow
Tensorflow的一个特色就是分布式计算。分布式Tensorflow是由高性能的gRPC框架作为底层技术来支持的。这是一个通信框架gRPC(google remote procedure call),是一个高性能、跨平台的RPC框架。RPC协议,即远程过程调用协议,是指通过网络从远程计算机程序上请求服务。
分布式原理
Tensorflow分布式是由多个服务器进程和客户端进程组成。有几种部署方式,例如单机多卡和多机多卡(分布式)。
单机多卡
单机多卡是指单台服务器有多块GPU设备。假设一台机器上有4块GPU,单机多GPU的训练过程如下:
- 在单机单GPU的训练中,数据是一个batch一个batch的训练。 在单机多GPU中,数据一次处理4个batch(假设是4个GPU训练), 每个GPU处理一个batch的数据计算。
- 变量,或者说参数,保存在CPU上。数据由CPU分发给4个GPU,在GPU上完成计算,得到每个批次要更新的梯度
- 在CPU上收集完4个GPU上要更新的梯度,计算一下平均梯度,然后更新。
- 循环进行上面步骤
多机多卡(分布式)
而分布式是指有多台计算机,充分使用多台计算机的性能,处理数据的能力。可以根据不同计算机划分不同的工作节点。当数据量或者计算量达到超过一台计算机处理能力的上限的话,必须使用分布式。
分布式的架构
当我们知道的基本的分布式原理之后,我们来看看分布式的架构的组成。分布式架构的组成可以说是一个集群的组成方式。那么一般我们在进行Tensorflow分布式时,需要建立一个集群。通常是我们分布式的作业集合。一个作业中又包含了很多的任务(工作结点),每个任务由一个工作进程来执行。
节点之间的关系
一般来说,在分布式机器学习框架中,我们会把作业分成参数作业(parameter job)和工作结点作业(worker job)。运行参数作业的服务器我们称之为参数服务器(parameter server,PS),负责管理参数的存储和更新,工作结点作业负责主要从事计算的任务,如运行操作。
参数服务器,当模型越来越大时,模型的参数越来越多,多到一台机器的性能不够完成对模型参数的更新的时候,就需要把参数分开放到不同的机器去存储和更新。参数服务器可以是由多台机器组成的集群。工作节点是进行模型的计算的。Tensorflow的分布式实现了作业间的数据传输,也就是参数作业到工作结点作业的前向传播,以及工作节点到参数作业的反向传播。
分布式的模式
在训练一个模型的过程中,有哪些部分可以分开,放在不同的机器上运行呢?在这里就要接触到数据并行的概念。
数据并行
数据并总的原理很简单。其中CPU主要负责梯度平均和参数更新,而GPU主要负责训练模型副本。
- 模型副本定义在GPU上
- 对于每一个GPU,都是从CPU获得数据,前向传播进行计算,得到损失,并计算出梯度
- CPU接到GPU的梯度,取平均值,然后进行梯度更新
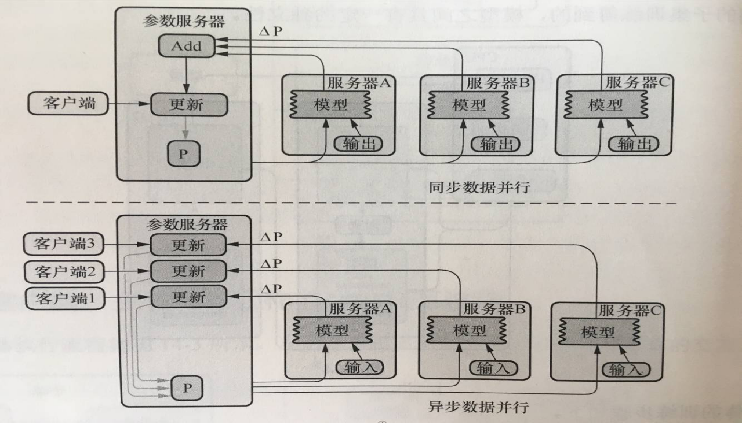
每一个设备的计算速度不一样,有的快有的满,那么CPU在更新变量的时候,是应该等待每一个设备的一个batch进行完成,然后求和取平均来更新呢?还是让一部分先计算完的就先更新,后计算完的将前面的覆盖呢?这就由同步更新和异步更新的问题。
同步更新和异步更新
更新参数分为同步和异步两种方式,即异步随机梯度下降法(Async-SGD)和同步随机梯度下降法(Sync-SGD)
- 同步随即梯度下降法的含义是在进行训练时,每个节点的工作任务需要读入共享参数,执行并行的梯度计算,同步需要等待所有工作节点把局部的梯度算好,然后将所有共享参数进行合并、累加,再一次性更新到模型的参数;下一个批次中,所有工作节点拿到模型更新后的参数再进行训练。这种方案的优势是,每个训练批次都考虑了所有工作节点的训练情况,损失下降比较稳定;劣势是,性能瓶颈在于最慢的工作结点上。
- 异步随机梯度下降法的含义是每个工作结点上的任务独立计算局部梯度,并异步更新到模型的参数中,不需要执行协调和等待操作。这种方案的优势是,性能不存在瓶颈;劣势是,每个工作节点计算的梯度值发送回参数服务器会有参数更新的冲突,一定程度上会影响算法的收敛速度,在损失下降的过程中抖动较大。
分布式API
创建集群的方法是为每一个任务启动一个服务,这些任务可以分布在不同的机器上,也可以同一台机器上启动多个任务,使用不同的GPU等来运行。每个任务都会创建完成以下工作
- 1、创建一个tf.train.ClusterSpec,用于对集群中的所有任务进行描述,该描述内容对所有任务应该是相同的
- 2、创建一个tf.train.Server,用于创建一个任务,并运行相应作业上的计算任务。
Tensorflow的分布式API使用如下:
- tf.train.ClusterSpec()
创建ClusterSpec,表示参与分布式TensorFlow计算的一组进程
cluster = tf.train.ClusterSpec({"worker": ["worker0.example.com:2222", /job:worker/task:0
"worker1.example.com:2222", /job:worker/task:1
"worker2.example.com:2222"],/job:worker/task:2
"ps": ["ps0.example.com:2222", /job:ps/task:0
"ps1.example.com:2222"]}) /job:ps/task:1
创建Tensorflow的集群描述信息,其中ps和worker为作业名称,通过指定ip地址加端口创建
- tf.train.Server(server_or_cluster_def, job_name=None, task_index=None, protocol=None, config=None, start=True)
- server_or_cluster_def: 集群描述
- job_name: 任务类型名称
- task_index: 任务数
创建一个服务(主节点或者工作节点服务),用于运行相应作业上的计算任务,运行的任务在task_index指定的机器上启动,例如在不同的ip+端口上启动两个工作任务
- 属性:target
- 返回tf.Session连接到此服务器的目标
- 方法:join()
- 参数服务器端等待接受参数任务,直到服务器关闭
tf.device(device_name_or_function):选择指定设备或者设备函数
- if device_name:
- 指定设备
- 例如:"/job:worker/task:0/cpu:0”
- if function:
- tf.train.replica_device_setter(worker_device=worker_device, cluster=cluster)
- 作用:通过此函数协调不同设备上的初始化操作
- worker_device:为指定设备, “/job:worker/task:0/cpu:0” or "/job:worker/task:0/gpu:0"
- cluster:集群描述对象
分布式案例
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("job_name", "worker", "启动服务类型,ps或者worker")
tf.app.flags.DEFINE_integer("task_index", 0, "指定是哪一台服务器索引")
def main(argv):
# 集群描述
cluster = tf.train.ClusterSpec({
"ps": ["127.0.0.1:4466"],
"worker": ["127.0.0.1:4455"]
})
# 创建不同的服务
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
else:
work_device = "/job:worker/task:0/cpu:0"
with tf.device(tf.train.replica_device_setter(
worker_device=work_device,
cluster=cluster
)):
# 全局计数器
global_step = tf.train.get_or_create_global_step()
# 准备数据
mnist = input_data.read_data_sets("./data/mnist/", one_hot=True)
# 建立数据的占位符
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32, [None, 28 * 28])
y_true = tf.placeholder(tf.float32, [None, 10])
# 建立全连接层的神经网络
with tf.variable_scope("fc_model"):
# 随机初始化权重和偏重
weight = tf.Variable(tf.random_normal([28 * 28, 10], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(tf.constant(0.0, shape=[10]))
# 预测结果
y_predict = tf.matmul(x, weight) + bias
# 所有样本损失值的平均值
with tf.variable_scope("soft_loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict))
# 梯度下降
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss, global_step=global_step)
# 计算准确率
with tf.variable_scope("acc"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# 创建分布式会话
with tf.train.MonitoredTrainingSession(
checkpoint_dir="./temp/ckpt/test",
master="grpc://127.0.0.1:4455",
is_chief=(FLAGS.task_index == 0),
config=tf.ConfigProto(log_device_placement=True),
hooks=[tf.train.StopAtStepHook(last_step=100)]
) as mon_sess:
while not mon_sess.should_stop():
mnist_x, mnist_y = mnist.train.next_batch(4000)
mon_sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y})
print("训练第%d步, 准确率为%f" % (global_step.eval(session=mon_sess), mon_sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y})))
if __name__ == '__main__':
tf.app.run()
运行参数服务器:
$ python zfx.py --job_name=ps
运行worker服务器:
$ python zfx.py --job_name=worker
【学习笔记】分布式Tensorflow的更多相关文章
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- 【学习笔记】tensorflow基础
目录 认识Tensorflow Tensorflow特点 下载以及安装 Tensorflow初体验 Tensorflow进阶 图 op 会话 Feed操作 张量 变量 可视化学习Tensorboard ...
- 学习笔记TF064:TensorFlow Kubernetes
AlphaGo,每个实验1000个节点,每个节点4个GPU,4000 GPU.Siri,每个实验2个节点,8个GPU.AI研究,依赖海量数据计算,离性能计算资源.更大集群运行模型,把周级训练时间缩短到 ...
- Google TensorFlow 学习笔记一 —— TensorFlow简介
"TensorFlow is an Open Source Software Library for Machine INtenlligence" 本笔记参考tensorflow. ...
- 学习笔记TF048:TensorFlow 系统架构、设计理念、编程模型、API、作用域、批标准化、神经元函数优化
系统架构.自底向上,设备层.网络层.数据操作层.图计算层.API层.应用层.核心层,设备层.网络层.数据操作层.图计算层.最下层是网络通信层和设备管理层.网络通信层包括gRPC(google Remo ...
- 学习笔记TF050:TensorFlow源代码解析
TensorFlow目录结构. ACKNOWLEDGMENTS #TensorFlow版本声明 ADOPTERS.md #使用TensorFlow的人员或组织列表 AUTHORS #TensorFlo ...
- 学习笔记TF024:TensorFlow实现Softmax Regression(回归)识别手写数字
TensorFlow实现Softmax Regression(回归)识别手写数字.MNIST(Mixed National Institute of Standards and Technology ...
- 学习笔记CB013: TensorFlow、TensorBoard、seq2seq
tensorflow基于图结构深度学习框架,内部通过session实现图和计算内核交互. tensorflow基本数学运算用法. import tensorflow as tf sess = tf.S ...
- 学习笔记TF067:TensorFlow Serving、Flod、计算加速,机器学习评测体系,公开数据集
TensorFlow Serving https://tensorflow.github.io/serving/ . 生产环境灵活.高性能机器学习模型服务系统.适合基于实际数据大规模运行,产生多个模型 ...
随机推荐
- 对抗明文口令泄露 —— Web 前端慢 Hash
(更新:https://www.cnblogs.com/index-html/p/frontend_kdf.html ) 0x00 前言 天下武功,唯快不破.但在密码学中则不同.算法越快,越容易破. ...
- 新手篇丨Python任意网段Web端口信息探测工具
你学习Python的目的是什么?是想写爬虫爬取数据(数据.图片等内容),还是想自写自动化的小工具,又或是作为一个新手小白单纯的欣赏这门语言呢? 今天i春秋分享的是一篇关于多线程工具的文章,工具使用效率 ...
- go语言调度器源代码情景分析之一:开篇语
专题简介 本专题以精心设计的情景为线索,结合go语言最新1.12版源代码深入细致的分析了goroutine调度器实现原理. 适宜读者 go语言开发人员 对线程调度器工作原理感兴趣的工程师 对计算机底层 ...
- XiaomiPushDemo【小米推送集成,基于V3.6.12版本】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 这个Demo只是记录小米推送的集成,不能运行. 使用步骤 一.项目组织结构图 注意事项: 1. 导入类文件后需要change包名以 ...
- 阿里云卸载自带的JDK,安装JDK完成相关配置
0.预备工作 笔者的云服务器购买的是阿里云的轻量应用服务器,相比于云服务器ECS,轻量应用服务器是固定流量但是网络带宽较高,对于服务器来说,网络带宽是非常昂贵的,而带宽也决定了你的应用访问的流畅度,带 ...
- Sql的分库分表,及优化
对Sql细节优化 在sql查询中为了提高查询效率,我们常常会采取一些措施对查询语句进行sql优化,下面总结的一些方法,有需要的可以参考参考. 首先给大家介绍一下分库分表 分库分表 分库 垂直分库 业务 ...
- 程序员如何巧用Excel提高工作效率 第二篇
之前写了一篇博客程序员如何巧用Excel提高工作效率,讲解了程序员在日常工作中如何利用Excel来提高工作效率,没想到收到很好的反馈,点赞量,评论量以及阅读量一度飙升为我的博客中Top 1,看来大家平 ...
- netty之NioEventLoopGroup源码分析二
大家好,今天我准备死磕NioEventLoopGroup的源码,首先讲下概念,NioEventLoopGroup 它是一个线程池,存放NioEventLoop,一个数组,今天打算先看下这行代码的初始化 ...
- Java并发——volatile关键字
什么是内存可见性? 这里就要提一下JMM(Java内存模型).当线程在运行的时候,并不是直接直接修改电脑主内存中的变量的值.线程间通讯也不是直接把一个线程的变量的值传给另一个线程,让其刷新变量.下面是 ...
- Bootstrap3级联多选下拉框
<!DOCTYPE html> <html> <head> <title>Bootstrap3级联多选下拉框</title> <met ...