Python爬虫之三
1)使用Scrapy,什么叫做Scrapy
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
2)安装的Scrapy
$ : sudo pip3 install scrapy
3)确定要爬去网站
如:http://bolg.jobbole.com/
步骤为:
(1)在/home/下新建文件夹
如:testspider
(2)使用命令进入文件夹
$:cd ~/testspider
$~/testspider: scrapy startproject testspider
(3)在使用pycharm打开testspider

结构说明:
testSpider 项目的外壳
testSpider 项目目录
spiders 爬虫编写目录
__init__.py 包文件
__init__.py 包文件
item.py 数据模型文件
middlewares.py 中间件文件 proxy 代理ip
pipelines.py 数据输出管道文件
settings.py 项目的配置文件
scrapy.cfg scapy 的配置文件
(4)使用scrapy的基本模板创建
$~/testspider: scrapy startproject testspider

(5)查看pycharm工程
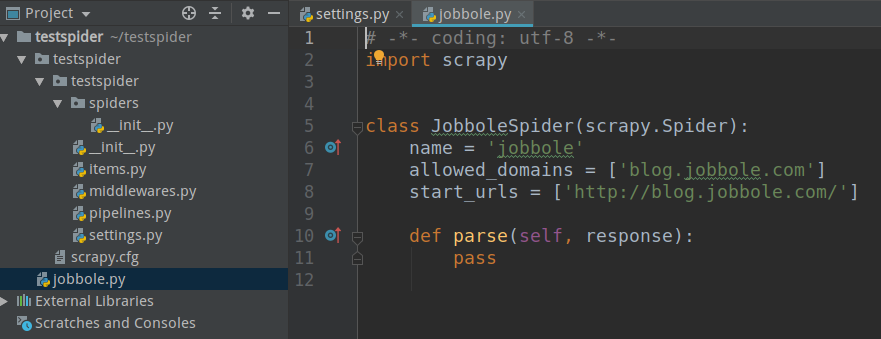
4)运行scrapy
书写程序
#启动程序
from scrapy.cmdline import execute
import sys
import os
print(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))#获取当前路径
execute(["scrapy","crawl","jobbole"])
运行结果:
2019-03-23 20:09:58 [scrapy.utils.log] INFO: Versions: lxml 4.3.2.0, libxml2 2.9.9, cssselect 1.0.3, parsel 1.5.1, w3lib 1.20.0, Twisted 18.9.0, Python 3.6.7 (default, Oct 22 2018, 11:32:17) - [GCC 8.2.0], pyOpenSSL 19.0.0 (OpenSSL 1.1.0g 2 Nov 2017), cryptography 2.1.4, Platform Linux-4.18.0-16-generic-x86_64-with-Ubuntu-18.04-bionic
2019-03-23 20:09:58 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'testspider', 'NEWSPIDER_MODULE': 'testspider.spiders', 'SPIDER_MODULES': ['testspider.spiders']}
2019-03-23 20:09:58 [scrapy.extensions.telnet] INFO: Telnet Password: d217d79f472f437e
2019-03-23 20:09:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
...
5)xpath
使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
(1)xpath的简介

(2)xpath语法



(3)xpath的使用
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114496/']
def parse(self, response):
re_selector_ = response.xpath("/html/body/div[3]/a/img")
pass
Python爬虫之三的更多相关文章
- Python爬虫之三种网页抓取方法性能比较
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块. 1. 正则表达式 如果你对正则表达式还不熟悉,或是需要一些提 ...
- Python爬虫之三种数据解析方式
一.引入 二.回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之三:Selenium 调用IEDriverServer 抓取数据
接着上一遍,在用Selenium+phantomjs 抓取数据过程中发现,有时候抓取不到,所以又测试了用Selenium+浏览器驱动的方式:具体代码如下: #coding=utf-8import os ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
随机推荐
- vue px 转rem
来自:https://www.cnblogs.com/wangqiao170/p/8652505.html 侵 删 每一个认真生活的人,都值得被认真对待 vue px转换为rem 前端开发中还原设 ...
- 海量数据,大数据处理技术--【Hbase】
- python xlrd 读取excel.md
文章链接:https://mp.weixin.qq.com/s/fojkVO-AB2cCu7FtDtPBjw 之前的文章介绍过关于写入excel表格的方法,近期自己在做一个网站,涉及到读取excel, ...
- 通过 Azure Pipelines 实现持续集成之docker容器化及自动化部署
通过 Azure Pipelines 实现持续集成之docker容器化及自动化部署 Intro Azure DevOps Pipeline 现在对于公开的项目完全免费,这对于开源项目来讲无疑是个巨大的 ...
- Python使用Plotly绘图工具,绘制饼图
今天我们来学习一下如何使用Python的Plotly绘图工具,绘制饼图 使用Plotly绘制饼图的方法,我们需要使用graph_objs中的Pie函数 函数中最常用的两个属性values,用于赋值给需 ...
- PMP(第六版)十大知识领域、五大项目管理过程组、49个过程矩阵
今天整理了PMP(第六版)十大知识领域.五大项目管理过程组.49个过程矩阵,分享出来,希望对要考PMP的童鞋有帮助. PS.红字是与第五版的差异 转走请标明出处 https://www.cnblog ...
- linux杀毒软件ClamAV的安装使用
1.安装依赖环境 yum install -y zlib openssl-devel yum groupinstall -y "Development Tools" apt ins ...
- samba介绍和安装
samba基本介绍 为什么需要samba 早期网络文件数据在不同主机之间传输大都可以使用Ftp完成,不过ftp使用有个小小的问题,它不能让你之间修改主机上的文件.要想修改必须要通过下载——修改——上传 ...
- 我的第一个python web开发框架(41)——总结
我的第一个python web开发框架系列博文从17年6.7月份开始写(存了近十章稿留到9月份才开始发布),到今天结束,一年多时间,想想真不容易啊. 整个过程断断续续,中间有段时间由于工作繁忙停了好长 ...
- 我的第一个python web开发框架(39)——后台接口权限访问控制处理
前面的菜单.部门.职位与管理员管理功能完成后,接下来要处理的是将它们关联起来,根据职位管理中选定的权限控制菜单显示以及页面数据的访问和操作. 那么要怎么改造呢?我们可以通过用户的操作步骤来一步步进行处 ...