Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页。
这里以简书里的优选连载网页为例分享一下我的爬取过程。
网址为:
https://www.jianshu.com/mobile/books?category_id=284
一、分析网页
进入之后,鼠标下拉发现内容会不断更新,网址信息也没有发生变化,于是就可以判断这个网页使用了异步加载技术。
 f
f
首先明确爬取的内容,本次我爬取的是作品名称、照片、作者、阅读量。然后将照片下载存储在文件夹中,然后将全部内容生成csv文件夹保存。
查看网页源代码发现代码里只有已加载的作品的内容,编写爬虫代码发现爬取不到收录的信息。
进入Network选项,勾选XHR选项,通过下滑网页发现Network选项卡会加载文件,如下图:
注:这里我用的是火狐浏览器

点击其中一个加载文件,可以在消息头看到请求网址:
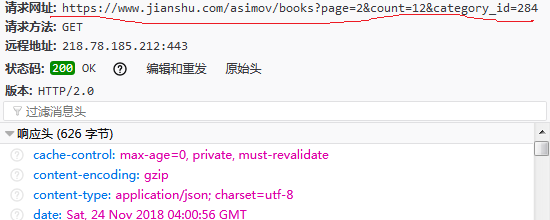
继续下滑,发现Headers部分请求的URL只是page后面的数字在改变,通过改变数字,我们就能在后面调用回调函数爬取多个网页了。
二、Scrapy爬取
1.在命令提示符输入:
cd Desktop #进入桌面
scrapy startproject jian #生成名为jian的Scrapy文件夹 cd jian
scrapy genspider lianzai jianshu.com #爬虫名为lianzai
这里我用的是pycharm,打开文件夹。

2.在items.py定义爬虫字段
class JianItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
book_name=scrapy.Field()
img=scrapy.Field()
author=scrapy.Field()
readers=scrapy.Field()
pass
3.在lianzai.py编写爬虫代码,爬取数据
# -*- coding: utf-8 -*-
import scrapy
from jian.items import JianItem
import json
import requests class LianzaiSpider(scrapy.Spider):
name = 'lianzai'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/asimov/books?page=1&count=12&category_id=284'] #第一页的url
def parse(self, response):
data=json.loads(response.body) #str转为json对象
try:
for i in range(0, 12):
item = JianItem()
img=data['books'][i]['image_url']
book_name=data['books'][i]['name']
author=data['books'][i]['user']['nickname']
readers=data['books'][i]['views_count'] item['img']=img
item['book_name']=book_name
item['author']=author
item['readers']=readers
yield item #返回数据
except IndexError:
pass
urls=['https://www.jianshu.com/asimov/books?page={}&count=12&category_id=284'.format(str(i))for i in range(2, 11)] #
for url in urls:
yield scrapy.Request(url,callback=self.parse) #回调函数
这里特别要注意的是要爬取内容的所在位置。
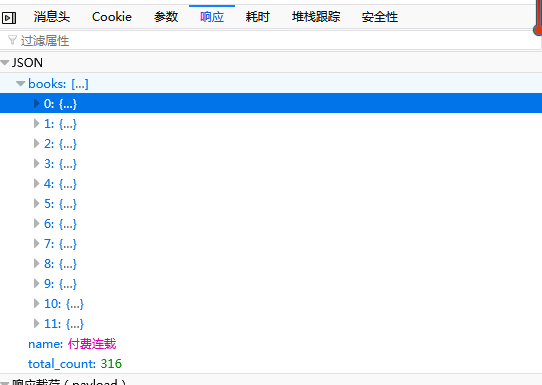
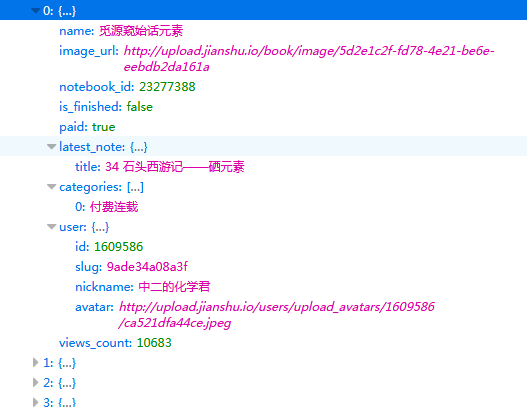
上图中左图可以看出爬取的内容的位置在response里的['books']里面,且一个网页有12个作品,因此上面循环出为(0,12)。
打开后如上右图,可以看到我们要爬取的作品名、图片地址、作者、阅读量都在里面,爬取就相对容易了。
4.在setting.py设置爬虫配置
USER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' #请求头
DOWNLOAD_DELAY=0.5 #延时0.5
FEED_URI='file:C:/Users/lenovo/Desktop/jianshulianzai.csv' #在桌面生成CSV文件
FEED_FORMAT='csv' #存入
ITEM_PIPELINES={'jian.pipelines.JianPipeline':300}
5.在pipelines.py处理照片数据
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import urllib.request class JianPipeline(object):
def process_item(self, item, spider):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
}
try:
if item['img'] != None:
req=urllib.request.Request(url=item['img'],headers=headers)
res=urllib.request.urlopen(req)
file_name = os.path.join(r'C:\Users\lenovo\Desktop\my_pic', item['book_name'] + '.jpg')
with open(file_name,'wb')as f:
f.write(res.read())
except urllib.request.URLError:
pass
return item
6.全部保存后,在命令行终端输入:
scrapy crawl lianzai
就将结果爬取下来并保存啦。
三、结果
.csv文件的内容:
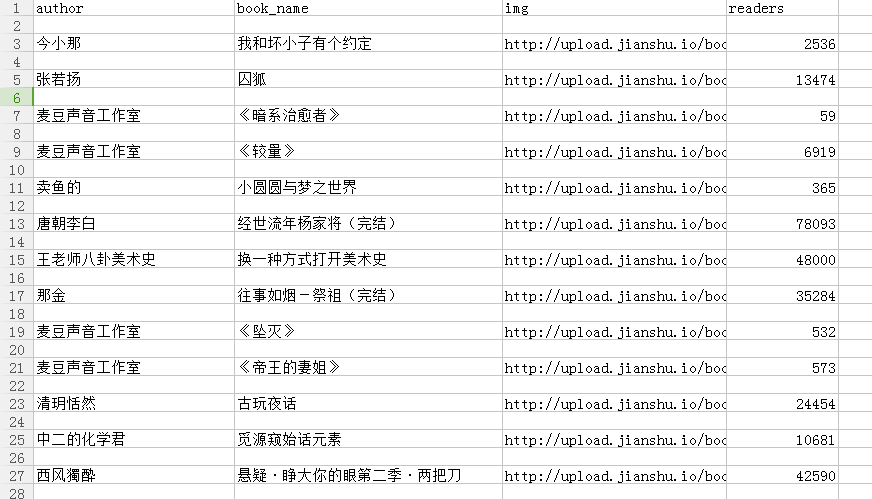
下载的照片:

初入爬虫,还有很多不足需要改正,还有很多知识需要学习,希望有疑问或建议的朋友多多指正或留言。谢谢。
Scrapy爬取Ajax(异步加载)网页实例——简书付费连载的更多相关文章
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 爬虫——爬取Ajax动态加载网页
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- scrapy项目5:爬取ajax形式加载的数据,并用ImagePipeline保存图片
1.目标分析: 我们想要获取的数据为如下图: 1).每本书的名称 2).每本书的价格 3).每本书的简介 2.网页分析: 网站url:http://e.dangdang.com/list-WY1-dd ...
- htmlunit爬取js异步加载后的页面
直接上代码: 一. index.html 调用后台请求获取content中的内容. <html> <head> <script type="text/javas ...
- 淘宝购物车页面 智能搜索框Ajax异步加载数据
如果有朋友对本篇文章的一些知识点不了解的话,可以先阅读此篇文章.在这篇文章中,我大概介绍了一下构建淘宝购物车页面需要的基础知识. 这篇文章主要探讨的是智能搜索框Ajax异步加载数据.jQuery的社区 ...
- jQuery的AJax异步加载
主要用到load()方法以及getScript()方法,具体以一个例子说明: 在现有html文件中加载一个拟好的片段,以及在片段加载完成之前阻止用户进一步操作的弹出框. 首先是现有html代码,无任何 ...
- ajax异步加载问题
使用ajax异步加载数据,在之后需要用到这个数据时,应该将之后的js一并写入ajax函数中,否则后面的js不能找到动态拼接的dom节点. 或者将其封装成方法,在ajax动态加载数据的最后调用该方法.
- Ajax 异步加载
AJAX (Asynchronous JavaScript and XML,异步的 JavaScript 和 XML).它不是新的编程语言,而是一种使用现有标准的新方法,是在不重新加载整个页面的情况下 ...
随机推荐
- jasperReport Studio java报表设计(详细)
一.环境搭建 在spring-mvc.xml加入 <!-- jasperReports--><import resource="classpath*:spring-mvc- ...
- Prime 算法的简述
前面在介绍并查集时顺便提了Kruskal算法,既然已经说到了最小生成树问题,就没有道理不把Prime算法说了. 这里面先补充下Kruskal算法的大概意思,Kruskal算法通过把所有的边从小到大排列 ...
- var与let、const的区别
var与let.const 一.var声明的变量会挂载在window上,而let和const声明的变量不会: var a = 100;console.log(a,window.a); // 100 1 ...
- 小程序从后台输出的代码为HTML实体字符如何解决?
最近在做一个小程序的考试系统,从后台调出的数据是这个样子的 那么我遇到这个问题的时候想到的微信小程序的富文本即(wxParse),使用过wxParse的都知道,富文本必须得具体到单个的数据上才能使用, ...
- vh、vw、vmin、vmax 知多少
介绍一些 CSS3 新增的单位,平时可能用的比较少,但是由于单位的特性,在一些特殊场合会有妙用. vw and vh 1vw 等于1/100的视口宽度 (Viewport Width) 1vh 等于1 ...
- GPU渲染流水线的简单概括
GPU流水线 主要分为两个阶段:几何阶段和光栅化阶段 几何阶段 顶点着色器 --> 曲面细分着色器(可选)----->几何着色器(可选)----->裁剪-->屏幕 ...
- PAT1070:Mooncake
1070. Mooncake (25) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Mooncake is ...
- Selenium自动化测试-unittest单元测试框架
一.Pyhon工作原理-- 核心概念:test case, testsuite, TestLoder,TextTestRunner,TextTestResult, test fixture TestC ...
- SpringMVC中参数绑定
SpringMVC中请求参数的接收主要有两种方式, 一种是基于HttpServletRequest对象获取, 另外一种是通过Controller中的形参获取 一 通过HttpServletReque ...
- Anaconda下载及安装教程
Anaconda官网 https://www.anaconda.com/download/#windows 选择Python 3.6版本 下一步,选择安装路径 下一步,两个方框打上对号,点击Insta ...