使用Python3爬虫抓取网页来下载小说
很多时候想看小说但是在网页上找不到资源,即使找到了资源也没有提供下载,小说当然是下载下来用手机看才爽快啦!
于是程序员的思维出来了,不能下载我就直接用爬虫把各个章节爬下来,存入一个txt文件中,这样,一部小说就爬下来啦。
这一次我爬的书为《黑客》,一本网络小说,相信很多人都看过吧,看看他的代码吧。
代码见如下:
import re
import urllib.request
import time #
root = 'http://www.biquge.com.tw/3_3542/'
# 伪造浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/62.0.3202.62 Safari/537.36'} req = urllib.request.Request(url=root, headers=headers) with urllib.request.urlopen(req, timeout=1) as response:
# 大部分的涉及小说的网页都有charset='gbk',所以使用gbk编码
htmls = response.read().decode('gbk') # 匹配所有目录<a href="/3_3542/2020025.html">HK002 上天给了一个做好人的机会</a>
dir_req = re.compile(r'<a href="/3_3542/(\d+?.html)">')
dirs = dir_req.findall(htmls) # 创建文件流,将各个章节读入内存
with open('黑客.txt', 'w') as f:
for dir in dirs:
# 组合链接地址,即各个章节的地址
url = root + dir
# 有的时候访问某个网页会一直得不到响应,程序就会卡到那里,我让他0.6秒后自动超时而抛出异常
while True:
try:
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request, timeout=0.6) as response:
html = response.read().decode('gbk')
break
except:
# 对于抓取到的异常,我让程序停止1.1秒,再循环重新访问这个链接,一旦访问成功,退出循环
time.sleep(1.1) # 匹配文章标题
title_req = re.compile(r'<h1>(.+?)</h1>')
# 匹配文章内容,内容中有换行,所以使flags=re.S
content_req = re.compile(r'<div id="content">(.+?)</div>',re.S,)
# 拿到标题
title = title_req.findall(html)[0]
# 拿到内容
content_test = content_req.findall(html)[0]
# 对内容中的html元素杂质进行替换
strc = content_test.replace(' ', ' ')
content = strc.replace('<br />', '\n')
print('抓取章节>' + title)
f.write(title + '\n')
f.write(content + '\n\n')
就这样,一本小说就下载下来啦!!!
运行情况见图:
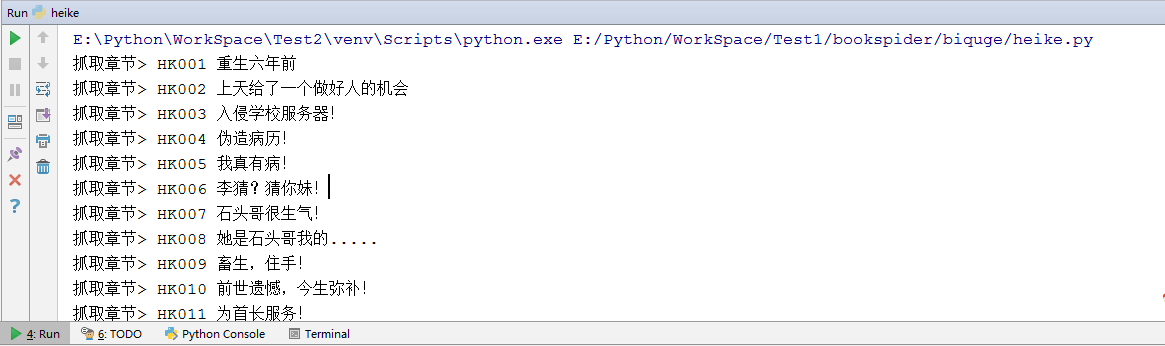
有的时候服务器会因为大量访问而认为你是个机器人就封了你的IP,可以加个随机数,让程序随机停止不同的时间。
如果下载太慢,可以使用多线程,一起下载多个章节
使用Python3爬虫抓取网页来下载小说的更多相关文章
- 关于Python3爬虫抓取网页Unicode
import urllib.requestresponse = urllib.request.urlopen('http://www.baidu.com')html = response.read() ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
- PHP利用Curl实现多线程抓取网页和下载文件
PHP 利用 Curl 可以完成各种传送文件操作,比如模拟浏览器发送GET,POST请求等等,然而因为php语言本身不支持多线程,所以开发爬虫程序效率并不高,一般采集 数据可以利用 PHPquery ...
- 笔趣看小说Python3爬虫抓取
笔趣看小说Python3爬虫抓取 获取HTML信息 解析HTML信息 整合代码 获取HTML信息 # -*- coding:UTF-8 -*- import requests if __name__ ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- linux中使用wget模拟爬虫抓取网页
如何在linux上或者是mac上简单使用爬虫或者是网页下载工具呢,常规的我们肯定是要去下载一个软件下来使用啦,可怜的这两个系统总是找不到相应的工具,这时wget出来帮助你啦!!!wget本身是拿来下载 ...
- C# 使用 Abot 实现 爬虫 抓取网页信息 源码下载
下载地址 ** dome **
- win7下用python3.3抓取网上图片并下载到本地
这篇文章是看了网上有人写了之后,才去试试看的,但是因为我用的是python3.3,与python2.x有些不同,所以就写了下来,以供参考. get_webJpg.py #coding=utf-8 im ...
随机推荐
- 如何在原生微信小程序中实现数据双向绑定
官网:https://qiu8310.github.io/minapp/ 作者:Mora 在原生小程序开发中,数据流是单向的,无法双向绑定,但是要实现双向绑定的功能还是蛮简单的! 下文要讲的是小程序框 ...
- 快速开发基于 HTML5 网络拓扑图应用之 DataBinding 数据绑定篇
前言 发现大家对于我从 json 文件中直接操作节点属性来控制界面的动态变化感到比较好奇,所以这篇就针对数据绑定以及如何使用这些绑定的数据做一篇说明,我写了一个简单的例子,基于机房工控的服务器上设备的 ...
- python 全栈开发,Day5
python之函数初识 一.什么是函数? 现在有这么个情况:python中的len方法不让用了,你怎么办? 来测试一下'hello word' 的长度: 用for循环实现 s1 = "hel ...
- AIX分页(交换)空间的监控
1.分页和交换 这两个概念,很多人混为一回事儿,两者虽然有共性,但也有些差别.分页是进程的部分内容在RAM和磁盘的分页空间间移动,而交换是整个进程在RAM和磁盘的分页空间间移动,在将进程移到磁盘分页空 ...
- ubuntu14.04行更新软件包
ubuntu14.04行更新软件包 headsen chen 2017-10-12 16:01:34 apt-get update对应的就是第一步. apt-get upgrade 与apt-g ...
- ES6之promise的使用
let checkLogin = function () { return new Promise(function (resolve,reject) { let flag = document.co ...
- Angular开发实践(四):组件之间的交互
在Angular应用开发中,组件可以说是随处可见的.本篇文章将介绍几种常见的组件通讯场景,也就是让两个或多个组件之间交互的方法. 根据数据的传递方向,分为父组件向子组件传递.子组件向父组件传递及通过服 ...
- Linux远程连接工具
Linux远程连接可以使用SecureCRT工具完成 SecureCRT下载地址 修改虚拟机中的网络适配器---改为桥接模式 一,配置:在Linux终端上获取IP地址----ifconfig 二,同时 ...
- 部署腾讯云(CentOS6.6版本,jdk1.7+tomcat8+mysql)
这是从一个大神哪里学到的,用来留下来用以记录 http://blog.csdn.net/qingluoII/article/details/76053736 只是其中有一个地方,我在学习的时候觉得可以 ...
- Spark核心技术原理透视一(Spark运行原理)
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位. Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势.无论是性能,还是方案的统一 ...