词向量:part 1 WordNet、SoW、BoW、TF-IDF、Hash Trick、共现矩阵、SVD
1.基于知识的表征
如WordNet(图1-1),包含同义词集(synonym sets)和上位词(hypernyms,is a关系)。

存在的问题:
- 作为资源来说是好的,但是它失去了词间的细微差别,比如说"good"和"full"同义是需要在一定的上下文中才能成立的;
- 易错过词的新义,基本不可能时时保持up-to-date;
- 是人为分的,所以是主观的结果;
- 需要花费很多的人力去创建和调整;
- 很难计算出准确的词间相似度。
2.基于数据库的表征
2.1 词本身
2.1.1 词集模型(SoW,Set of Words)
0-1表征,参见图2.1.1-1,向量维度为数据库中总词汇数,每个词向量在其对应词处取值为1,其余处为0。

存在的问题:
因为不同词间相互正交,所以很难计算词间相似度。
2.1.2 词袋模型(BoW,Bag of Words)
除了考虑词是否出现外,词袋模型还考虑其出现次数,即每个词向量在其对应词处取值为该词在文本中出现次数,其余处为0。
但是,用词频来衡量该词的重要性是存在问题的,比如"the",其词频很高,但其实没有那么重要,所以可以使用TF-IDF特征来统计修正词频。
修正后的向量依旧存在数据稀疏的问题,大部分值为0,常使用Hash Trick进行降维。
TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF(term frequency):词在当前文本中的词频;
IDF(inverse document frequency):包含该词的文本在语料库中出现频率的倒数的对数。
\(IDF(x)=log{N \over N(x)}\),其中,N是语料库中文本的总数,N(x)是语料库中包含词x的文本的总数。
常见的IDF平滑公式之一:\(IDF(x)=log{N+1 \over N(x)+1}+1\)。
最终,词x的TF-IDF值:\(TF\)-\(IDF(x)=TF(x)*IDF(x)\)。
Hash Trick
哈希函数h将第i个特征哈希到位置j,即h(i)=j,则第i个原始特征的词频数值c(i)将会累积到哈希后的第j个特征的词频数值c'(j)上,即:\(c'(j)=\sum_{i\in J;h(i)=j}c(i)\),其中J是原始特征的维度。
但这样做存在一个问题,有可能两个原始特征哈希后位置相同,导致词频累加后特征值突然变大。
为了解决这个问题,出现了hash trick的变种signed hash trick,多了一个哈希函数\({\xi}:N{\rightarrow}{\pm}1\),此时,我们有\(c'(j)=\sum_{i\in J;h(i)=j}{\xi}(i)c(i)\)。
这样做的好处是,哈希后的特征值仍然是一个无偏的估计,不会导致某些哈希位置的值过大。从实际应用中来说,由于文本特征的高稀疏性,这么做是可行的。
注意hash trick降维后的特征已经不知道其代表的特征和意义,所以其解释性不强。
2.2 结合上下文
基本思想:近义词之间常有相似的上下文邻居。
2.2.1 共现矩阵
- 基于整个文档:常给出文档的主题信息;
- 基于上下文窗口:常捕获语法、语义信息。
图2.2.1-1为基于窗口大小为1、不区分左右形成的高维稀疏词向量。
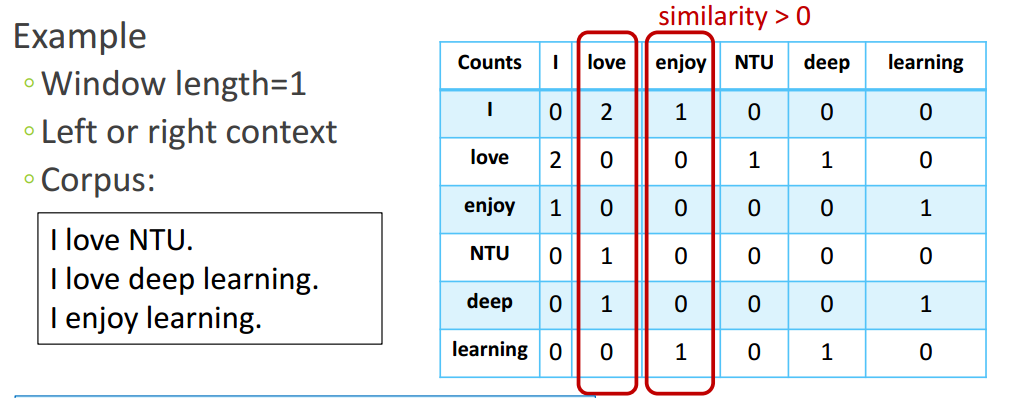
存在的问题:
- 共现矩阵的大小随着词汇量的增多而变大;
- 维度高;
- 数据稀疏带来的鲁棒性差。
2.2.2 低维稠密词向量
降维
通过对共现矩阵进行SVD,如图2.2.2-1所示。
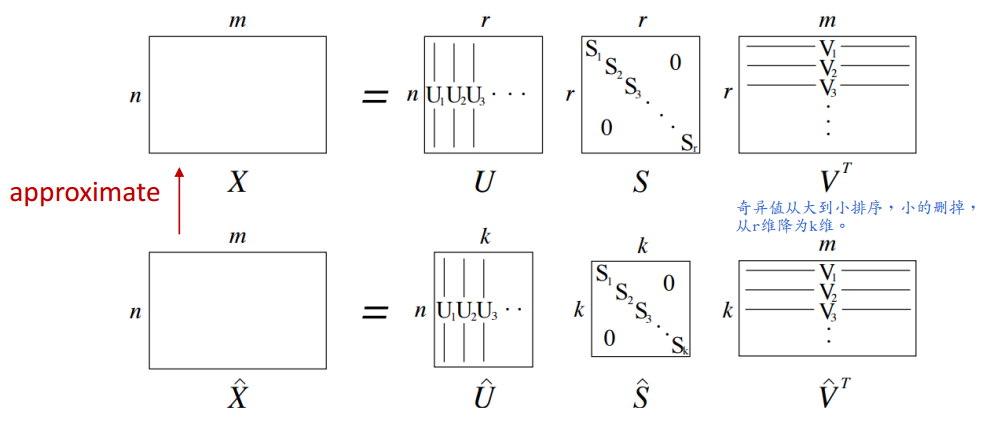
选择U的前k列得到k维词向量。
优势:
- 有效地利用了统计信息。
存在的问题:
- 难以加入新词,每次来个新词,都得更新共现矩阵,然后重新SVD;
- 由于大多数词不共现,导致矩阵十分稀疏;
- 矩阵维度通常很高(\(\approx 10^6*10^6\));
- 计算代价高,对于\(n*m\)的矩阵为\(O(nm^2)\);
- 需要对共现矩阵进行处理来面对词频上的极端不平衡现象。
常用的解决办法:
- 忽视"the"、"he"、"has"等功能词或者限制其次数不超过某个值(常100);
- 基于文档中词间距离对共现矩阵中的count进行加权处理,常窗口中离中心词越近的词分配给其的权重越大;
- 使用Pearson相关系数(\(C(X,Y)=\frac{cov(X,Y)}{\sigma(X)*\sigma(Y)}\))来代替原本的count,负数置0。
直接学
基于迭代:相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词间共现值。
- word2vec
- GloVe
词向量:part 1 WordNet、SoW、BoW、TF-IDF、Hash Trick、共现矩阵、SVD的更多相关文章
- 词表征 1:WordNet、0-1表征、共现矩阵、SVD
原文地址:https://www.jianshu.com/p/c1e4f42b78d7 一.基于知识的表征 参见图1.1,WordNet中包含同义词集(synonym sets)和上位词(hypern ...
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...
- 词向量(one-hot/SVD/NNLM/Word2Vec/GloVe)
目录 词向量简介 1. 基于one-hot编码的词向量方法 2. 统计语言模型 3. 从分布式表征到SVD分解 3.1 分布式表征(Distribution) 3.2 奇异值分解(SVD) 3.3 基 ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)
自然语言处理的第一步就是获取词向量,获取词向量的方法总体可以分为两种两种,一个是基于统计方法的,一种是基于语言模型的. 1 Glove - 基于统计方法 Glove是一个典型的基于统计的获取词向量的方 ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- JS常见操作,日期操作,字符串操作,表单验证等
复制代码 //第一篇博文,希望大家多多支持 /***** BasePage.js 公共的 脚本文件 部分方法需引用jquery库 *****/ //#region 日期操作 //字符串转化为时间. f ...
- 网络1712--c语言嵌套循环作业总结
1.助教有话说 首先,每周一篇的博客作业是很有必要的:编程的过程不仅仅是会敲几行代码.能够通过PTA就大吉大利了,你更应该做到的是梳理代码思路,通过与他人代码思路的比对,取其精华,进而不断进阶,才能逐 ...
- 从PRISM开始学WPF(六)MVVM(三)事件聚合器EventAggregator?
从PRISM开始学WPF(一)WPF? 从PRISM开始学WPF(二)Prism? 从PRISM开始学WPF(三)Prism-Region? 从PRISM开始学WPF(四)Prism-Module? ...
- 用phpcms切换中英文网页的方法(不用解析二级域名)、phpcms完成pc和手机端切换(同一域名)
AA.phpcms进行双语切换方法(不用解析二级域名)作者:悦悦 博客地址:http://www.cnblogs.com/nuanai/ phpcms进行两种语言的切换,有一把部分的人都是进行的二级域 ...
- EasyUI 中datagrid 分页。
注释:datagrid分页搞了好几天才完全搞好,网上没完全的资料.明天晚上贴代码. 睡觉.
- Python之旅.第四章.模块与包 4.02
一.模块的使用之import 1 什么是模块?模块就一系统功能的集合体,在python中,一个py文件就是一个模块,比如module.py,其中模块名module2 使用模块2.1 import 导入 ...
- app测试中遇到问题总结
工作总结: 1 这两天由于工作,需要进行抓包,使用了Charles,fidder,发现一个坑点: charles没有抓到返回值的时候,默认是不在列表显示请求信息的,能不能设置,我就不知道了,但是可以在 ...
- 增加Linux虚拟机的硬盘空间
原配置为40G,现需要增加到60G,操作方法如下: 一.虚拟机关机,在编辑设置里调整硬盘空间到60G 二.虚拟机开机,扩展硬盘空间 1.安装gparted,命令如下 sudo apt-get inst ...
- java实现两个int数交换
普通方法,进阶方法,大神方法 @Test public void test3(){ int m = 5; int n = 12; //要求m和n交换位置 System.out.println(&quo ...
- Apache设置用户权限(2个域名。一个能访问全部文件,一个只能访问指定文件)
可以利用apache的虚拟主机的配置设置: 2个域名一个是xxxxx.com ,一个是aaaaa.com xxxxx.com配置只访问jpg文件,aaaaa.com可以访问所有文件 <Virtu ...