ElasticSearch AggregationBuilders java api常用聚会查询
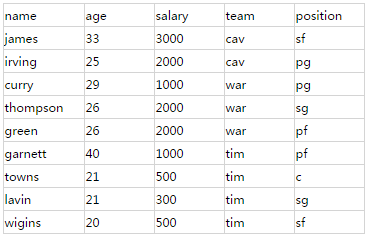
以球员信息为例,player索引的player type包含5个字段,姓名,年龄,薪水,球队,场上位置。
index的mapping为:
"mappings": {
"player": {
"properties": {
"name": {
"index": "not_analyzed",
"type": "string"
},
"age": {
"type": "integer"
},
"salary": {
"type": "integer"
},
"team": {
"index": "not_analyzed",
"type": "string"
},
"position": {
"index": "not_analyzed",
"type": "string"
}
},
"_all": {
"enabled": false
}
}
}
索引中的全部数据:
首先,初始化Builder:
SearchRequestBuilder sbuilder = client.prepareSearch("player").setTypes("player");
接下来举例说明各种聚合操作的实现方法,因为在es的api中,多字段上的聚合操作需要用到子聚合(subAggregation),初学者可能找不到方法(网上资料比较少,笔者在这个问题上折腾了两天,最后度了源码才彻底搞清楚T_T),后边会特意说明多字段聚合的实现方法。另外,聚合后的排序也会单独说明。
- group by/count
例如要计算每个球队的球员数,如果使用SQL语句,应表达如下:
select team, count(*) as player_count from player group by team;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
sbuilder.addAggregation(teamAgg);
SearchResponse response = sbuilder.execute().actionGet();
- group by多个field
例如要计算每个球队每个位置的球员数,如果使用SQL语句,应表达如下:
select team, position, count(*) as pos_count from player group by team, position;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
TermsBuilder posAgg= AggregationBuilders.terms("pos_count").field("position");
sbuilder.addAggregation(teamAgg.subAggregation(posAgg));
SearchResponse response = sbuilder.execute().actionGet();
- max/min/sum/avg
例如要计算每个球队年龄最大/最小/总/平均的球员年龄,如果使用SQL语句,应表达如下:
select team, max(age) as max_age from player group by team;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
MaxBuilder ageAgg= AggregationBuilders.max("max_age").field("age");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg));
SearchResponse response = sbuilder.execute().actionGet();
- 对多个field求max/min/sum/avg
例如要计算每个球队球员的平均年龄,同时又要计算总年薪,如果使用SQL语句,应表达如下:
select team, avg(age)as avg_age, sum(salary) as total_salary from player group by team;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("team");
AvgBuilder ageAgg= AggregationBuilders.avg("avg_age").field("age");
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg).subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
- 聚合后对Aggregation结果排序
例如要计算每个球队总年薪,并按照总年薪倒序排列,如果使用SQL语句,应表达如下:
select team, sum(salary) as total_salary from player group by team order by total_salary desc;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("team").order(Order.aggregation("total_salary ", false);
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
需要特别注意的是,排序是在TermAggregation处执行的,Order.aggregation函数的第一个参数是aggregation的名字,第二个参数是boolean型,true表示正序,false表示倒序。
- Aggregation结果条数的问题
默认情况下,search执行后,仅返回10条聚合结果,如果想反悔更多的结果,需要在构建TermsBuilder 时指定size:
TermsBuilder teamAgg= AggregationBuilders.terms("team").size(15);- Aggregation结果的解析/输出
得到response后:
Map<String, Aggregation> aggMap = response.getAggregations().asMap();
StringTerms teamAgg= (StringTerms) aggMap.get("keywordAgg");
Iterator<Bucket> teamBucketIt = teamAgg.getBuckets().iterator();
while (teamBucketIt .hasNext()) {
Bucket buck = teamBucketIt .next();
//球队名
String team = buck.getKey();
//记录数
long count = buck.getDocCount();
//得到所有子聚合
Map subaggmap = buck.getAggregations().asMap();
//avg值获取方法
double avg_age= ((InternalAvg) subaggmap.get("avg_age")).getValue();
//sum值获取方法
double total_salary = ((InternalSum) subaggmap.get("total_salary")).getValue();
//...
//max/min以此类推
}
- 总结
综上,聚合操作主要是调用了SearchRequestBuilder的addAggregation方法,通常是传入一个TermsBuilder,子聚合调用TermsBuilder的subAggregation方法,可以添加的子聚合有TermsBuilder、SumBuilder、AvgBuilder、MaxBuilder、MinBuilder等常见的聚合操作。
从实现上来讲,SearchRequestBuilder在内部保持了一个私有的 SearchSourceBuilder实例, SearchSourceBuilder内部包含一个List<AbstractAggregationBuilder>,每次调用addAggregation时会调用 SearchSourceBuilder实例,添加一个AggregationBuilder。
同样的,TermsBuilder也在内部保持了一个List<AbstractAggregationBuilder>,调用addAggregation方法(来自父类addAggregation)时会添加一个AggregationBuilder。有兴趣的读者也可以阅读源码的实现。
如果有什么问题,欢迎一起讨论,如果文中有什么错误,欢迎批评指正。
ElasticSearch AggregationBuilders java api常用聚会查询的更多相关文章
- Elasticsearch java api 常用查询方法QueryBuilder构造举例
转载:http://m.blog.csdn.net/u012546526/article/details/74184769 Elasticsearch java api 常用查询方法QueryBuil ...
- Elasticsearch中JAVA API的使用
1.Elasticsearch中Java API的简介 Elasticsearch 的Java API 提供了非常便捷的方法来索引和查询数据等. 通过添加jar包,不需要编写HTTP层的代码就可以开始 ...
- Java API 常用类(一)
Java API 常用类 super类详解 "super"关键字代表父类对象.通过使用super关键字,可以访问父类的属性或方法,也可以在子类构造方法中调用父类的构造方法,以便初始 ...
- ElasticSearch实战系列三: ElasticSearch的JAVA API使用教程
前言 在上一篇中介绍了ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解,本篇文章就来讲解下 ElasticSearch 6.x官方Java API的 ...
- 使用Java操作Elasticsearch(Elasticsearch的java api使用)
1.Elasticsearch是基于Lucene开发的一个分布式全文检索框架,向Elasticsearch中存储和从Elasticsearch中查询,格式是json. 索引index,相当于数据库中的 ...
- HDFS Java API 常用操作
package com.luogankun.hadoop.hdfs.api; import java.io.BufferedInputStream; import java.io.File; impo ...
- Elasticsearch Java API—多条件查询(must)
多条件设置 //多条件设置 MatchPhraseQueryBuilder mpq1 = QueryBuilders .matchPhraseQuery("pointid",&qu ...
- [ElasticSearch]Java API 之 词条查询(Term Level Query)
1. 词条查询(Term Query) 词条查询是ElasticSearch的一个简单查询.它仅匹配在给定字段中含有该词条的文档,而且是确切的.未经分析的词条.term 查询 会查找我们设定的准确值 ...
- ElasticSearch的java api
pom <dependencies> <dependency> <groupId>org.elasticsearch.client</groupId> ...
随机推荐
- maven系列--maven目录
我们在玩maven,首先就是利用maven来管理我们的项目.其实maven并不难,它无非是一种目录结构.所以在本系列开始之前,我们要细致的了解下maven的目录,其实也就是maven的约定. 约定优于 ...
- jdk源码->集合->HashSet
类的属性 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, ...
- 解决ubuntu系统root用户下Chrome无法启动问题
由于ubuntu16.04系统自带的是Firefox浏览器,需要安装Chrome浏览器,但是在root用户下安装后发现,Chrome无法正常启动.安装及问题解决具体如下: 1. ubuntu上Chro ...
- zabbix_sender用法实例
环境centos6.8 zabbix版本3.2.4 需求: 要远程监控一台服务器A,但只能通过远程服务器连接本地服务器B,但B不能主动连A(因为A没有固定公网ip) 使用了zabbix_agent的a ...
- 2018-01-28-TF源码做版本兼容的一个粗暴方法
layout: post title: 2018-01-28-TF源码做版本兼容的一个粗暴方法 key: 20180128 tags: IT AI TF modify_date: 2018-01-28 ...
- Android开发模板代码(二)——为ImageView设置图片,退出后能保存ImageView的状态
接着之前的那个从图库选择图片,设置到ImageView中去,但是,我发现了一个问题,就是再次进入的时候ImageView是恢复到了默认状态,搜索了资料许久之后,终于是发现了解决方法,使用SharePr ...
- H3c交换机配置端口镜像详情
端口镜像 需要将G0/0/1口的全部流量镜像到G0/0/2口,即G0/0/1为源端口,G0/0/2为目的端口. 配置步骤 1.进入配置模式:system-view: 2.创建本地镜像组:mirrori ...
- python字符串常用的方法解析
这是本人在学习python过程中总结的一些关于字符串的常用的方法. 文中引用了python3.5版本内置的帮助文档,大致进行翻译,并添加了几个小实验. isalnum S.isalnum() -> ...
- 安装redis 2.6.4
下载redis-2.6.4下载链接:http://pan.baidu.com/s/1eQ9Z8NS make MALLOC=jemalloc/server/redis2/src/redis-serve ...
- 基本的socket编程的介绍
网络IPC:套接字 用socket实现两个不同的主机之间的通信(涉及到一些基本的计算机网络知识 略过..) 服务器端: 1.socket函数:生成一个套接字 int socket(int domai ...