B+索引、Hash索引、数据类型长度
1.为什么在数据库中要用B树索引而不是Hash索引?
Mysql Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
但 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)MySQL Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于 MySQL Hash索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)MySQL Hash索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(3)MySQL Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
(4)MySQL Hash索引无法被用来避免数据的排序操作。
由于 MySQL Hash索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(5)MySQL Hash索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(2)
2. B-Tree索引
MySQL 中的 B-Tree 索引的物理文件大多都是以平衡树的结构来存储的,所有实际需要的数据都存放于 Tree 的 Leaf Node ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以称之为 B-Tree 索引。
Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree ,但在每一个Leaf Node 上面出了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息,这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
在 Innodb 存储引擎中,存在两种不同形式的索引,一种是 Cluster 形式的主键索引( Primary Key ),另外一种则是和其他存储引擎(如 MyISAM 存储引擎)存放形式基本相同的普通 B-Tree 索引,这种索引在 Innodb 存储引擎中被称为 Secondary Index 。
图示中左边为 Clustered 形式存放的 Primary Key ,右侧则为普通的 B-Tree 索引。两种 Root Node 和 Branch Nodes 方面都还是完全一样的。而 Leaf Nodes 就出现差异了。在 Prim中, Leaf Nodes 存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据据以主键值有序的排列。而 Secondary Index 则和其他普通的 B-Tree 索引没有太大的差异,Leaf Nodes 出了存放索引键 的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过 Secondary Index 来访问数据的话, Innodb 首先通过 Secondary Index 的相关信息,通过相应的索引键检索到 Leaf Node之后,需要再通过 Leaf Node 中存放的主键值再通过主键索引来获取相应的数据行。MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空 的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的 Secondary Index 的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在 Leaf Nodes 上面出了存放索引键信息之外,再存放能直接定位到 MyISAM 数据文件中相应的数据行的信息(如 Row Number ),但并不会存放主键的键值信息。
B~树:
B~树,又叫平衡多路查找树。一棵m阶的B~树 (m叉树)的特性如下:
1) 树中每个结点至多有m个孩子;
2) 除根结点和叶子结点外,其它每个结点至少有[m/2]个孩子;
3) 若根结点不是叶子结点,则至少有2个孩子;
4) 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
5) 每个非终端结点中包含有n个关键字信息: (n,A0,K1,A1,K2,A2,......,Kn,An)。其中,
a) Ki (i=1...n)为关键字,且关键字按顺序排序Ki < K(i-1)。
b) Ai为指向子树根的接点,且指针A(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [m/2]-1 <= n <= m-1
B+树:
B+树:是应文件系统所需而产生的一种B~树的变形树。
一棵m阶的B+树和m阶的B-树的差异在于:
1) 有n棵子树的结点中含有n个关键字; (B~树是n棵子树有n+1个关键字)
2) 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (B~树的叶子节点并没有包括全部需要查找的信息)
3) 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B~树的非终节点也包含需要查找的有效信息)
B+树的叶子结点包含了所有待查询关键字,而非终节点只是作为叶子结点中最大(最小)关键字的索引。因此B+树的非终结点没有文件内容所在物理存储的地址,而B~树所有结点均有文件内容所在的磁盘物理地址(B~树结构图中结点内部的小红方块)。
2.java数据类型长度
1、整数:包括int,short,byte,long
2、浮点型:float,double
3、字符:char
4、布尔:boolean
| 基本型别 | 大小 | 最小值 | 最大值 |
| boolean | ----- | ----- | ------ |
| char | 16-bit | Unicode 0 | Unicode 2^16-1 |
| byte | 8-bit | -128 | +127 |
| short | 16-bit | -2^15 | +2^15-1 |
| int | 32-bit | -2^31 | +2^31-1 |
| long | 64-bit | -2^63 | +2^63-1 |
| float | 32-bit | IEEE754 | IEEE754 |
| double | 64-bit | IEEE754 | IEEE754 |
| void |
3.TCP/IP模型
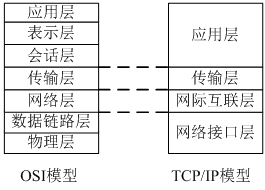
① 网络接口层:主要参与IP分组时建立和网络介质的物理连接
② 网际互联层:主要解决主机到主机的通信问题。该层有四个主要协议:网际协议(IP)、地址解析协议(ARP)、互联网组管理协议(IGMP)和互联网控制报文协议(ICMP)。IP协议是网际互联层最重要的协议,它提供的是一个不可靠、无连接的数据报传递服务。
③ 传输层:为应用层实体提供端到端的通信功能。该层定义了两个主要的协议:传输控制协议(TCP)和用户数据报协议(UDP)。TCP协议提供的是一种可靠的、面向连接的数据传输服务;而UDP协议供的是不可靠的、无连接的数据传输服务。
④ 应用层:为用户提供所需要的各种服务,例如FTP、Telnet、DNS、SMTP等。
4.Date中的Month-1
因为JDK的月份表示范围是0~11,分别表示1月至12月。
5.线程读写锁(和数据库一样)
读写锁:
读写锁算法主要实现对共享资源访问时,可以在多个线程间同时进行读操作,但是在同一时间内只能有一个线程对共享资源进行修改,并且在写操作时不能有线程进行读操作。
算法思想:
当进行读操作时不能进行写操作,因此当有读操作时需要一把锁来锁住写操作,由于允许多个线程同时读操作,因此还需要一个变量(count)来记录当前读操作的线程个数,由于对count的修改需要互斥,因此还需要一个锁用来保存count的修改。
在多线程的环境下,对同一份数据进行读写,会涉及到线程安全的问题。比如在一个线程读取数据的时候,另外一个线程在
写数据,而导致前后数据的不一致性;一个线程在写数据的时候,另一个线程也在写,同样也会导致线程前后看到的数据的
不一致性。
读写锁的机制: "读-读"不互斥 "读-写"互斥 "写-写"互斥
即在任何时候必须保证:
只有一个线程在写入;
线程正在读取的时候,写入操作等待;
线程正在写入的时候,其他线程的写入操作和读取操作都要等待;
缺点:
1. 进行读操作时会进行再次加锁和解锁操作,计算开销比较大,因此对锁内计算比较小的操作不适合使用读写锁。
2. 如果读操作比较密集,使得rwLock.m_icount永远不可能为0,因此会使写操作线程饿死。
B+索引、Hash索引、数据类型长度的更多相关文章
- mysql索引hash索引和b-tree索引的区别
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-T ...
- 数据库索引------Hash索引的使用限制
1.hash索引必须进行二次查找. 2.hash索引无法进行排序. 3.hash索引不支持部分索引查找也不支持范围查找. 4.hash索引中hash码的计算可能存在hash冲突.
- Hash索引与B-Tree索引
Hash索引 Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要 ...
- Hash索引和BTREE索引2
索引是数据库中用来提高性能的最常用工具.所有MySql列类型都可以被索引.索引用于快速找出在某个列中有一特定值的行.如果不使用索引,MYSQL必须从第一条记录开始然后读完整个表直到找出相关的行.常用的 ...
- MySQL索引结构之Hash索引、full-text全文索引(面)
Hash索引 主要就是通过Hash算法(常见的Hash算法有直接定址法.平方取中法.折叠法.除数取余法.随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位 ...
- MySQL的btree索引和hash索引的区别
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-T ...
- Mysql 自定义HASH索引带来的巨大性能提升----[挖坑篇]
有这样一个业务场景,需要在2个表里比较存在于A表,不存在于B表的数据.表结构如下: T_SETTINGS_BACKUP | CREATE TABLE `T_SETTINGS_BACKUP` ( `FI ...
- SQLServer中间接实现函数索引或者Hash索引
本文出处:http://www.cnblogs.com/wy123/p/6617700.html SQLServer中没有函数索引,在某些场景下查询的时候要根据字段的某一部分做查询或者经过某种计算之后 ...
- MySQL的btree索引和hash索引的区别 (转)
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-T ...
随机推荐
- Android Studio库依赖问题
Error:Execution failed for task ':app:transformResourcesWithMergeJavaResForDebug'. > com.android. ...
- 一个ios的各种组件、代码分类,供参考
http://github.ibireme.com/github/list/ios/#
- Linux时间转标准时间
[root@nhserver2 ~]# date -d '1970-1-1 0:0:0 GMT + 1394592071 seconds'Wed Mar 12 10:41:11 CST 2014
- Java NIO 之 Buffer
Java NIO 之 Buffer Java NIO (Non Blocking IO 或者 New IO)是一种非阻塞IO的实现.NIO通过Channel.Buffer.Selector几个组件的协 ...
- [SF] Symfony 组件 BrowserKit 原理
直接看下面的注释中针对每一个文件的作用说明. <?php /** * BrowserKit - Make internal requests to your application. * * I ...
- (转载)用VS2012或VS2013在win7下编写的程序在XP下运行就出现“不是有效的win32应用程序“
原文地址:http://www.vcerror.com/?p=1483 问题描述: 用VC2013编译了一个程序,在Windows 8.Windows 7(64位.32位)下都能正常运行.但在Win ...
- 网页转图片--- html2canvas截图
最近有个做在线名片(可保存图片至本地)的任务,特意研究了一下图片生成,也踩了几个坑.特此总结一下,顺便分享一下demo: 链接:https://pan.baidu.com/s/1o98UBJO 密码: ...
- C#基础(四)--值类型和引用类型,栈和堆的含义
本文主要是讨论栈和堆的含义,也就是讨论C#的两种类据类型:值类型和引用类型: 虽然我们在.net中的框架类库中,大多是引用类型,但是我们程序员用得最多的还是值类型. 引用类型如:string,Obje ...
- IOLI-crackme0x01-0x05 writeup
上一篇开了个头, 使用Radare2并用3中方法来解决crackme0x00, 由于是第一篇, 所以解释得事无巨细, 今天就稍微加快点步伐, 分析一下另外几个crackme. 如果你忘记了crackm ...
- SDOI2017 Round1
SDOI2017 Round1 在回去的车上写的 cnblog的markdown貌似有bug,空行都没有了 Day -several [清明节] 没想到在省选之前还会有一次放假 放假前一天晚上走到校门 ...