大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想
简单解释 MapReduce 算法
一个有趣的例子:你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃?

MapReduce方法则是:
给在座的所有玩家中分配这摞牌
让每个玩家数自己手中的牌有几张是黑桃,然后把这个数目汇报给你
你把所有玩家告诉你的数字加起来,得到最后的结论
拆分
MapReduce合并了两种经典函数:
- 映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
- 化简(Reducing )遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
重新审视上面的例子
重新审视我们原来那个分散纸牌的例子,我们有MapReduce数据分析的基本方法。友情提示:这不是个严谨的例子。在这个例子里,人代表计算机,因为他们同时工作,所以他们是个集群。在大多数实际应用中,我们假设数据已经在每台计算机上了 – 也就是说把牌分发出去并不是MapReduce的一步。(事实上,在计算机集群中如何存储文件是Hadoop的真正核心。)
通过把牌分给多个玩家并且让他们各自数数,你就在并行执行运算,因为每个玩家都在同时计数。这同时把这项工作变成了分布式的,因为多个不同的人在解决同一个问题的过程中并不需要知道他们的邻居在干什么。通过告诉每个人去数数,你对一项检查每张牌的任务进行了映射。 你不会让他们把黑桃牌递给你,而是让他们把你想要的东西化简为一个数字。另外一个有意思的情况是牌分配得有多均匀。MapReduce假设数据是洗过的(shuffled)- 如果所有黑桃都分到了一个人手上,那他数牌的过程可能比其他人要慢很多。
如果有足够的人的话,问一些更有趣的问题就相当简单了 - 比如“一摞牌的平均值(二十一点算法)是什么”。你可以通过合并“所有牌的值的和是什么”及“我们有多少张牌”这两个问题来得到答案。用这个和除以牌的张数就得到了平均值。
MapReduce算法的机制要远比这复杂得多,但是主体思想是一致的 – 通过分散计算来分析大量数据。无论是Facebook、NASA,还是小创业公司,MapReduce都是目前分析互联网级别数据的主流方法。
Hadoop中的MapReduce
大规模数据处理时,MapReduce在三个层面上的基本构思:
如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略
上升到抽象模型:Mapper与Reducer
MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型
上升到构架:统一构架,为程序员隐藏系统层细节
MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节
三个层面详解
1.对付大数据处理-分而治之
什么样的计算任务可进行并行化计算?
并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。但一些计算问题恰恰无法进行这样的划分!
Nine women cannot have a baby in one month!
例如:Fibonacci函数: Fk+2 = Fk + Fk+1
前后数据项之间存在很强的依赖关系!只能串行计算!
结论:不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
大数据的并行化计算
一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是并行计算
例如:假设有一个巨大的2维数据需要处理(比如求每个元素的开立方),其中对每个元素的处理是相同的,并且数据元素间不存在数据依赖关系,可以考虑不同的划分方法将其划分为子数组,由一组处理器并行处理



2.构建抽象模型-Map和Reduce
借鉴函数式设计语言Lisp的设计思想
函数式程序设计(functional programming)语言Lisp是一种列表处理 语言(List processing),是一种应用于人工智能处理的符号式语言,由MIT的人工智能专家、图灵奖获得者John McCarthy于1958年设计发明。
Lisp定义了可对列表元素进行整体处理的各种操作,如:
如:(add #(1 2 3 4) #(4 3 2 1)) 将产生结果: #(5 5 5 5)
Lisp中也提供了类似于Map和Reduce的操作:
如: (map ‘vector #+ #(1 2 3 4 5) #(10 11 12 13 14))
通过定义加法map运算将2个向量相加产生结果#(11 13 15 17 19)
(reduce #’+ #(11 13 15 17 19)) 通过加法归并产生累加结果75
Map: 对一组数据元素进行某种重复式的处理
Reduce: 对Map的中间结果进行某种进一步的结果整

关键思想:为大数据处理过程中的两个主要处理操作提供一种抽象机制
MapReduce中的Map和Reduce操作的抽象描述
MapReduce借鉴了函数式程序设计语言Lisp中的思想,定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
输入:键值对(k1; v1)表示的数据
处理:文档数据记录(如文本文件中的行,或数据表格中的行)将以“键值对”形式传入map函数;map函数将处理这些键值对,并以另一种键值对形式输出处理的一组键值对中间结果 [(k2; v2)]
输出:键值对[(k2; v2)]表示的一组中间数据
输入: 由map输出的一组键值对[(k2; v2)] 将被进行合并处理将同样主键下的不同数值合并到一个列表[v2]中,故reduce的输入为(k2; [v2])
处理:对传入的中间结果列表数据进行某种整理或进一步的处理,并产生最终的某种形式的结果输出[(k3; v3)] 。
输出:最终输出结果[(k3; v3)]
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述
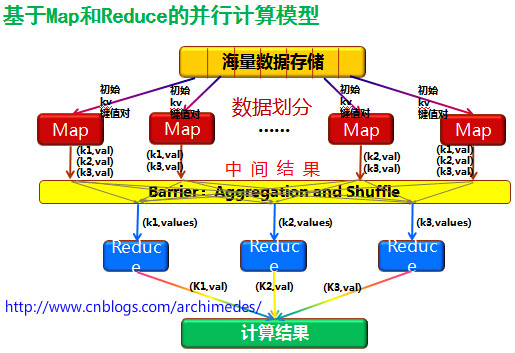
各个map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出
各个reduce也各自并行计算,各自负责处理不同的中间结果数据集合进行reduce处理之前,必须等到所有的map函数做完,因此,在进入reduce前需要有一个同步障(barrier);这个阶段也负责对map的中间结果数据进行收集整理(aggregation & shuffle)处理,以便reduce更有效地计算最终结果最终汇总所有reduce的输出结果即可获得最终结果
基于MapReduce的处理过程示例–文档词频统计:WordCount
设有4组原始文本数据:
Text 1: the weather is good Text 2: today is good
Text 3: good weather is good Text 4: today has good weather
传统的串行处理方式(Java):

输出:good: 5; has: 1; is: 3; the: 1; today: 2; weather: 3
基于MapReduce的处理过程示例–文档词频统计:WordCount
MapReduce处理方式
使用4个map节点:
map节点1:
输入:(text1, “the weather is good”)
输出:(the, 1), (weather, 1), (is, 1), (good, 1)
map节点2:
输入:(text2, “today is good”)
输出:(today, 1), (is, 1), (good, 1)
map节点3:
输入:(text3, “good weather is good”)
输出:(good, 1), (weather, 1), (is, 1), (good, 1)
map节点4:
输入:(text3, “today has good weather”)
输出:(today, 1), (has, 1), (good, 1), (weather, 1)
使用3个reduce节点:

MapReduce处理方式
MapReduce伪代码(实现Map和Reduce两个函数):


如何提供统一的计算框架
MapReduce提供一个统一的计算框架,可完成:
计算任务的划分和调度
数据的分布存储和划分
处理数据与计算任务的同步
结果数据的收集整理(sorting, combining, partitioning,…)
系统通信、负载平衡、计算性能优化处理
处理系统节点出错检测和失效恢复
MapReduce最大的亮点
通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架
程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码
如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用
MapReduce提供的主要功能
任务调度:提交的一个计算作业(job)将被划分为很多个计算任务(tasks), 任务调度功能主要负责为这些划分后的计算任务分配和调度计算节点(map节点或reducer节点); 同时负责监控这些节点的执行状态, 并负责map节点执行的同步控制(barrier); 也负责进行一些计算性能优化处理, 如对最慢的计算任务采用多备份执行、选最快完成者作为结果
数据/代码互定位:为了减少数据通信,一个基本原则是本地化数据处理(locality),即一个计算节点尽可能处理其本地磁盘上所分布存储的数据,这实现了代码向数据的迁移;当无法进行这种本地化数据处理时,再寻找其它可用节点并将数据从网络上传送给该节点(数据向代码迁移),但将尽可能从数据所在的本地机架上寻找可用节点以减少通信延迟
基于Map和Reduce的并行计算模型
4.MapReduce的主要设计思想和特征
1、向“外”横向扩展,而非向“上”纵向扩展(Scale “out”, not “up”)
即MapReduce集群的构筑选用价格便宜、易于扩展的大量低端商用服务器,而非价格昂贵、不易扩展的高端服务器(SMP)低端服务器市场与高容量Desktop PC有重叠的市场,因此,由于相互间价格的竞争、可互换的部件、和规模经济效应,使得低端服务器保持较低的价格基于TPC-C在2007年底的性能评估结果,一个低端服务器平台与高端的共享存储器结构的服务器平台相比,其性价比大约要高4倍;如果把外存价格除外,低端服务器性价比大约提高12倍对于大规模数据处理,由于有大量数据存储需要,显而易见,基于低端服务器的集群远比基于高端服务器的集群优越,这就是为什么MapReduce并行计算集群会基于低端服务器实现
2、失效被认为是常态(Assume failures are common)
MapReduce集群中使用大量的低端服务器(Google目前在全球共使用百万台以上的服务器节点),因此,节点硬件失效和软件出错是常态,因而:一个良好设计、具有容错性的并行计算系统不能因为节点失效而影响计算服务的质量,任何节点失效都不应当导致结果的不一致或不确定性;任何一个节点失效时,其它节点要能够无缝接管失效节点的计算任务;当失效节点恢复后应能自动无缝加入集群,而不需要管理员人工进行系统配置MapReduce并行计算软件框架使用了多种有效的机制,如节点自动重启技术,使集群和计算框架具有对付节点失效的健壮性,能有效处理失效节点的检测和恢复。
3、把处理向数据迁移(Moving processing to the data)
传统高性能计算系统通常有很多处理器节点与一些外存储器节点相连,如用区域存储网络(SAN,Storage Area Network)连接的磁盘阵列,因此,大规模数据处理时外存文件数据I/O访问会成为一个制约系统性能的瓶颈。为了减少大规模数据并行计算系统中的数据通信开销,代之以把数据传送到处理节点(数据向处理器或代码迁移),应当考虑将处理向数据靠拢和迁移。MapReduce采用了数据/代码互定位的技术方法,计算节点将首先将尽量负责计算其本地存储的数据,以发挥数据本地化特点(locality),仅当节点无法处理本地数据时,再采用就近原则寻找其它可用计算节点,并把数据传送到该可用计算节点。
4、顺序处理数据、避免随机访问数据(Process data sequentially and avoid random access)
大规模数据处理的特点决定了大量的数据记录不可能存放在内存、而只可能放在外存中进行处理。磁盘的顺序访问和随即访问在性能上有巨大的差异
例:100亿(1010)个数据记录(每记录100B,共计1TB)的数据库
更新1%的记录(一定是随机访问)需要1个月时间;而顺序访问并重写所有数据记录仅需1天时间!
5、为应用开发者隐藏系统层细节(Hide system-level details from the application developer)
软件工程实践指南中,专业程序员认为之所以写程序困难,是因为程序员需要记住太多的编程细节(从变量名到复杂算法的边界情况处理),这对大脑记忆是一个巨大的认知负担,需要高度集中注意力而并行程序编写有更多困难,如需要考虑多线程中诸如同步等复杂繁琐的细节,由于并发执行中的不可预测性,程序的调试查错也十分困难;大规模数据处理时程序员需要考虑诸如数据分布存储管理、数据分发、数据通信和同步、计算结果收集等诸多细节问题MapReduce提供了一种抽象机制将程序员与系统层细节隔离开来,程序员仅需描述需要计算什么(what to compute), 而具体怎么去做(how to compute)就交由系统的执行框架处理,这样程序员可从系统层细节中解放出来,而致力于其应用本身计算问题的算法设计
6、平滑无缝的可扩展性(Seamless scalability)
大数据 --> MapReduce原理与设计思想的更多相关文章
- MapReduce原理与设计思想
简单解释 MapReduce 算法 一个有趣的例子 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座的所有玩家中分配这摞牌 让每个玩家 ...
- 转:MapReduce原理与设计思想
转自:http://www.cnblogs.com/wuyudong/p/mapreduce-principle.html 简单解释 MapReduce 算法 一个有趣的例子 你想数出一摞牌中有多少张 ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
- 大数据技术原理与应用——大数据处理架构Hadoop
Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构. Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以 ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
- SpringMVC原理&MVC设计思想
什么是MVC? MVC是一种架构模式 --- 程序分层,分工合作,既相互独立,又协同工作 MVC是一种思考方式 --- 需要将什么信息展示给用户? 如何布局? 调用哪些业务逻辑? MVC流程图如下图所 ...
随机推荐
- hql查询实例
1.设计思路 (1)在页面中设计一个下拉框,数据取自数据库: (2)查询是用hql查询. 2.设计实例 (1)Java模型层 public class Tree { private String id ...
- 【mongodb系统学习之十一】mongodb删除数据
十一.mongodb删除数据: 1).删除全部文档:remove,语法db.collectionName.remove({}):小括号里边必须要有条件,否则不成功:如果只是一个空的{},则会删除集合内 ...
- freemarker报错之一
freemarker 1.错误描述 java.io.FileNotFoundException: Template user.ftl not found. at freemarker.template ...
- C#连接oracle数据库步骤
1. 确认操作系统类型,操作系统是64位还是32位: 2. 按对应版本安装oralce客户端版本(64位还是32位): 3. 安装oralce管理员模块,同时赋予安装目录权限 4. 注册old ...
- DataTable复制数据,深度复制
/**/ /// <summary> /// 复制数据,深度复制 /// </summary> /// <param name="dataSourceRow&q ...
- 【原】Java学习笔记029 - 映射
package cn.temptation; import java.util.HashMap; import java.util.Map; public class Sample01 { publi ...
- ASP.NET Core轻松入门Bind读取配置文件到C#实例
首先新建一个ASP.NET Core空项目,命名为BindReader 然后 向项目中添加一个名为appsettings.json的json文件,为什么叫appsettings呢? 打开Progra ...
- 异常-----The superclass "javax.servlet.http.HttpServlet" was not found on the Java Build Path。
1, 找到新建页面所在的工程名字,然后左键选中,右键弹出功能菜单,选择Build Path,进入配置路径. 2, 在java build path 页面的下选择Libraries栏目(默认选择),点击 ...
- VS2010 EXCEL2010 表格操作的编程实现
参考: http://blog.csdn.net/wxfy1977/article/details/3847450(另外一种实现方式,数据库方式) http://blog.csdn.net/evkj2 ...
- 网页加载进度的实现--JavaScript基础
总结了一些网页加载进度的实现方式…… 1.定时器实现加载进度 <!DOCTYPE html><html lang="en"><head> < ...