Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创)
Spark显式缓存
NVMe SSD面临的调整
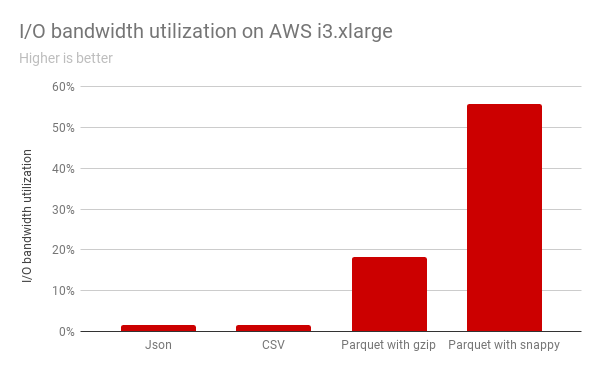
自适应运行
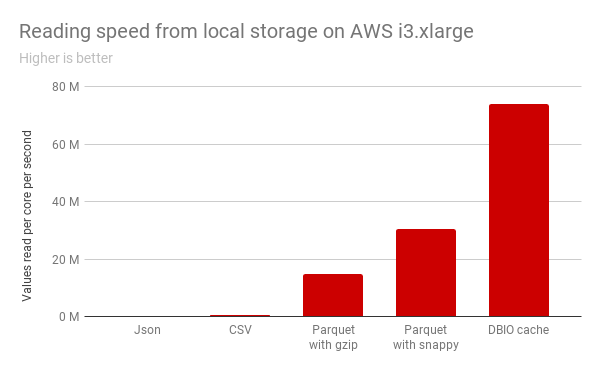
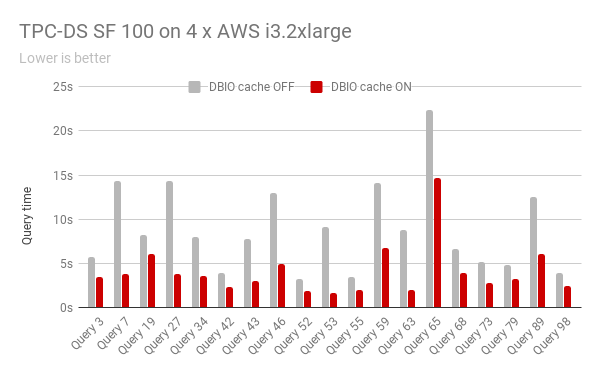
性能
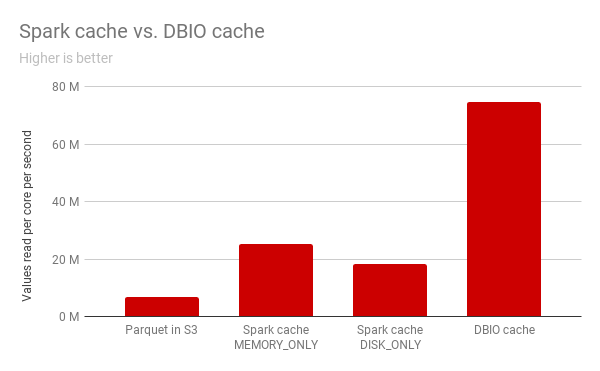
对比Spark缓存和Databricks缓存
Databricks缓存配置
spark.databricks.io.cache.enabled true
spark.databricks.io.cache.maxDiskUsage "{DISK SPACE PER NODE RESERVED FOR CACHED DATA}"
spark.databricks.io.cache.maxMetaDataCache "{DISK SPACE PER NODE RESERVED FOR CACHED METADATA}"
结论
Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创)的更多相关文章
- NVMe固态硬盘工具箱使用说明
https://www.bilibili.com/read/cv562989/ 浦科特NVMe固态硬盘工具箱使用说明 数码 2018-6-7 687阅读7点赞3评论 浦科特已经推出针对NVMe固态硬盘 ...
- 一文看懂SATA和NVMe固态硬盘用起来有何区别?
本文摘自:https://www.sohu.com/a/203688929_615464 NVMe固态硬盘正在逐步扩张,而包括三星.东芝在内的大厂并没有停止SATA固态硬盘新品的研发.到底那种固态硬盘 ...
- ubuntu 开机进入grub rescue> 解决办法(nvme固态硬盘)
起因: 我是在windows下格式化了ubuntu的盘,然后重新安装ubuntu就出现了这种问题.卸载ubuntu的正确姿势,要去查一下,千万不要直接格式化. 解决方法: 1. 先使用ls命令,找到 ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- Web 应用性能提升 10 倍的 10 个建议
转载自http://blog.jobbole.com/94962/ 提升 Web 应用的性能变得越来越重要.线上经济活动的份额持续增长,当前发达世界中 5 % 的经济发生在互联网上(查看下面资源的统计 ...
- 把WinXP装进内存 性能飚升秒杀固态硬盘
现在用户新配置的电脑,内存很少有小于2GB的,配置4GB内存的朋友也有不少.容量如此大的内存,我们在使用电脑的日常操作中绝对用不完.而目前制约系统性能最大的瓶颈就是硬盘的传输速度,所以,这里教你怎么把 ...
- M.2接口NVMe协议的固态硬盘读写速度是SATA接口的两倍
原文:https://www.sohu.com/a/203688929_615464 中午走路的时候,同事说的,M 2 nvme接口的更快. 树莓派开发板可以跑linux . ------------ ...
- 固态硬盘寿命实测让你直观SSD寿命!--转
近年来,高端笔记本及系列上网本越来越多的采用固态硬盘来提升整机性能,尽管众所周知固态硬盘除 了在正常的使用中带来更快速度的体验外,还具有零噪音.不怕震动.低功耗等优点,但大家对固态硬盘的寿命问题的担忧 ...
- 机械硬盘和ssd固态硬盘的原理对比分析
固态硬盘和机械硬盘的区别 机械硬盘 磁头是不是直接和盘片接触的呢 磁盘中有几个盘片 机械硬盘的工作原理 固态硬盘的寻址方式 SMR叠瓦式真的比PMR优秀吗 固态硬盘 主控芯片 闪存颗粒 缓存单元 固态 ...
随机推荐
- 数据挖掘概念与技术15--为快速高维OLAP预计算壳片段
1. 论数据立方体预计算的多种策略的优弊 (1)计算完全立方体:需要耗费大量的存储空间和不切实际的计算时间. (2)计算冰山立方体:优于计算完全立方体,但在某种情况下,依然需要大量的存储空间和计算时间 ...
- Asp.net SignalR 让实时通讯变得简单
巡更项目中,需要发送实时消息,以及需要任务开始提醒,于是便有机会接触到SignalR,在使用过程中,发现用SignalR实现通信非常简单,下面我思明将从三个方面分享一下: 一.SignalR是什么 A ...
- 献给迷惘的Java架构工程师
1. 工程化专题 (团队大于3个人之后,你需要去考虑团队合作,科学管理) 2. 源码分析专题 (好的程序员,一行代码一个设计就能看出来,源码分析带你品味代码,感受架构) 3.高性能及分布式专题 ( ...
- JIRA开启时间追踪并为问题记录工作日志
在升级版的JIRA中(4.2or4.3),我们可以使用其记录工作日志的功能.之前研究了很长时间,就是找不到初始预估时间在哪里设置,但是剩余工作时间与耗费时间都可以填写.根据官网的帮助文档也没找到合适的 ...
- 通过例子理解 k8s 架构 - 每天5分钟玩转 Docker 容器技术(122)
为了帮助大家更好地理解 Kubernetes 架构,我们部署一个应用来演示各个组件之间是如何协作的. 执行命令 kubectl run httpd-app --image=httpd --replic ...
- AtCoder Regular Contest 082
我都出了F了……结果并没有出E……atcoder让我差4分上橙是啥意思啊…… C - Together 题意:把每个数加1或减1或不变求最大众数. #include<cstdio> #in ...
- poj_2251
Dungeon Master Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 24311 Accepted: 9425 D ...
- FineReport父子格实现动态参数注入
"深入学习FineReport后发现其功能及其强大,之前使用存储过程实现的报表完全可以使用FineReport本身的功能实现. 当你需要的表名,查询条件等均未知的时候,使用"动态参 ...
- Video Target Tracking Based on Online Learning—深度学习在目标跟踪中的应用
摘要 近年来,深度学习方法在物体跟踪领域有不少成功应用,并逐渐在性能上超越传统方法.本文先对现有基于深度学习的目标跟踪算法进行了分类梳理,后续会分篇对各个算法进行详细描述. 看上方给出的3张图片,它们 ...
- 分布式监控系统--zabbix
1Zabbix简介 Zabbix 是一个企业级的分布式开源监控方案. 2.监控系统架构 C/S架构 客户端/服务器端,这种架构适合规模较小,处于同一地域的环境 C/P/S 客户端/代理端/服务器端/, ...