Redis 由浅入深
1.redis是什么?
redis是nosql(也是个巨大的map) 单线程,但是可处理1秒10w的并发(数据都在内存中)
使用java对redis进行操作类似jdbc接口标准对mysql,有各类实现他的实现类,我们常用的是druid
其中对redis,我们通常用Jedis(也为我们提供了连接池JedisPool)
在redis中,key就是byte[](string)
redis的数据结构(value):
String,list,set,orderset,hash
每种数据结构对应不同的命令语句~
2.redis怎么使用?
先安装好redis,然后运行,在pom文件中引入依赖,在要使用redis缓存的类的mapper.xml文件配置redis的全限定名。引入redis的redis.properties文件(如果要更改配置就可以使用)
3.应用场景:
String :
1存储json类型对象,2计数器,3优酷视频点赞等
list(双向链表)
1可以使用redis的list模拟队列,堆,栈
2朋友圈点赞(一条朋友圈内容语句,若干点赞语句)
规定:朋友圈内容的格式:
1,内容: user:x:post:x content来存储;
2,点赞: post:x:good list来存储;(把相应头像取出来显示)
hash(hashmap)
1保存对象
2分组
4.为什么redis是单线程的都那么快?
1.数据存于内存
2.用了多路复用I/O

多路复用图解
3.单线程
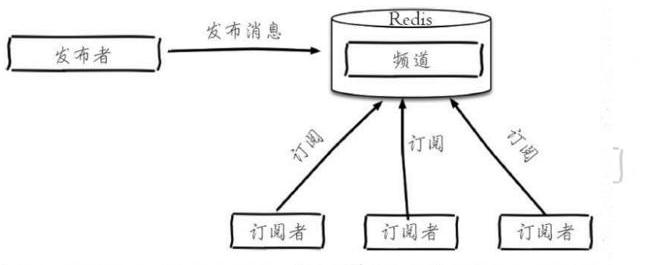
5.redis也可以进行发布订阅消息吗?
可以,(然后可以引出哨兵模式(后面会讲)怎么互相监督的,就是因为每隔2秒哨兵节点会发布对某节点的判断和自身的信息到某频道,每个哨兵订阅该频道获取其他哨兵节点和主从节点的信息,以达到哨兵间互相监控和对主从节点的监控)和很多专业的消息队列系统(例如Kafka、RocketMQ)相比,Redis的发布订阅略显粗糙,例如无法实现消息堆积和回溯。但胜在足够简单。
Redis 的一些问题与解决方案 :
6.redis能否将数据持久化,如何实现?
能,将内存中的数据异步写入硬盘中,两种方式:RDB(默认)和AOF
RDB持久化原理:通过bgsave命令触发,然后父进程执行fork操作创建子进程,子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换(定时一次性将所有数据进行快照生成一份副本存储在硬盘中)
优点:是一个紧凑压缩的二进制文件,Redis加载RDB恢复数据远远快于AOF的方式。
缺点:由于每次生成RDB开销较大,非实时持久化,
AOF持久化原理:开启后,Redis每执行一个修改数据的命令,都会把这个命令添加到AOF文件中。
优点:实时持久化。
缺点:所以AOF文件体积逐渐变大,需要定期执行重写操作来降低文件体积,加载慢
7.主从复制模式下,主挂了怎么办?redis提供了哨兵模式(高可用)
何谓哨兵模式?就是通过哨兵节点进行自主监控主从节点以及其他哨兵节点,发现主节点故障时自主进行故障转移。

8.哨兵模式实现原理?(2.8版本或更高才有)
1.三个定时监控任务:
1.1 每隔10s,每个S节点(哨兵节点)会向主节点和从节点发送info命令获取最新的拓扑结构
1.2 每隔2s,每个S节点会向某频道上发送该S节点对于主节点的判断以及当前Sl节点的信息,
同时每个Sentinel节点也会订阅该频道,来了解其他S节点以及它们对主节点的判断(做客观下线依据)
1.3 每隔1s,每个S节点会向主节点、从节点、其余S节点发送一条ping命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达
2.主客观下线:
2.1主观下线:根据第三个定时任务对没有有效回复的节点做主观下线处理
2.2客观下线:若主观下线的是主节点,会咨询其他S节点对该主节点的判断,超过半数,对该主节点做客观下线
3.选举出某一哨兵节点作为领导者,来进行故障转移。选举方式:raft算法。每个S节点有一票同意权,哪个S节点做出主观下线的时候,就会询问其他S节点是否同意其为领导者。获得半数选票的则成为领导者。基本谁先做出客观下线,谁成为领导者。
4.故障转移(选举新主节点流程):

9.redis集群(采用虚拟槽方式,高可用)原理(和哨兵模式原理类似,3.0版本或以上才有)?
1.Redis集群内节点通过ping/pong消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(pfail)和客观下线(fail)
2.主客观下线:
2.1主观下线:集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果通信一直失败,则发送节点会把接收节点标记为主观下线(pfail)状态。
2.2客观下线:超过半数,对该主节点做客观下线
3.主节点选举出某一主节点作为领导者,来进行故障转移。
4.故障转移(选举从节点作为新主节点)
10.缓存更新策略(即如何让缓存和mysql保持一致性)?

10.1 key过期清除(超时剔除)策略
惰性过期(类比懒加载,这是懒过期):只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。)
问:比如这么个场景,我设计了很多key,过期时间是5分钟,当前内存占用率是50%。但是5分钟到了,内存占用率还是很高,请问为什么?
Redis中同时使用了惰性过期和定期过期两种过期策略,即使过期时间到了,但是有部分并没有真正删除,等待惰性删除。
为什么有定期还要有惰性呢?其实很简单,比如10万个key就要过期了,Redis默认是100ms检查一波。如果他检查出10万个即将要清除,那他接下来的时间基本都是在干这些清空内存的事了,那肯定影响性能,所以他只会部分删除,剩下的等惰性
10.2 Redis的内存淘汰策略
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
11.缓存粒度控制?

12.如何防止缓存穿透?
(缓存穿透指的是查询一个根本不存在的数据,缓存层不命中,又去查存储层,又不命中。但如果有大量这种查询不存在的数据的请求过来,会对存储层有较大压力,若是恶意攻击,黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。后果就)

12.1:缓存空值存在的问题:

12.2:布隆过滤器:

其他解决方案:
1.. 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
2..采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
3..提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
布隆过滤器存在的问题:相对来说布隆过滤器搞起来代码还是比较复杂的,现阶段我们暂时还不需要,后面实在需要再考虑去做,什么阶段做什么样的事情,不是说这个系统一下子就能做的各种完美。
13.无底洞优化?
造成原因:redis分布式越来越多,导致性能反而下降,因为键值分布到更多的 节点上,所以无论是Memcache还是Redis的分布式,批量操作通常需要从不 同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作 会涉及多次网络时间。 即分布式过犹不及。

14.雪崩优化
如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。

解决方案 :
1..给缓存的失效时间,加上一个随机值,避免集体失效。
2.. 使用互斥锁,但是该方案吞吐量明显下降了。
3..双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
I 从缓存A读数据库,有则直接返回
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B。
15.热点key优化
当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。

Redis 由浅入深的更多相关文章
- 这次一定要教会你搭建Redis集群和MySQL主从同步(非Docker)
前言 一直都想自己动手搭建一个Redis集群和MySQL的主从同步,当然不是依靠Docker的一键部署(虽然现在企业开发用的最多的是这种方式),所以本文就算是一个教程类文章吧,但在动手搭建之前,会先聊 ...
- 由浅入深学习springboot中使用redis
很多时候,我们会在springboot中配置redis,但是就那么几个配置就配好了,没办法知道为什么,这里就详细的讲解一下 这里假设已经成功创建了一个springboot项目. redis连接工厂类 ...
- (一)由浅入深学习springboot中使用redis
很多时候,我们会在springboot中配置redis,但是就那么几个配置就配好了,没办法知道为什么,这里就详细的讲解一下 这里假设已经成功创建了一个springboot项目. redis连接工厂类 ...
- 初识Redis(1)
Redis 是一款依据BSD开源协议发行的高性能Key-Value存储系统(cache and store). 它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希( ...
- Redis进阶实践之十三 Redis的Redis-trib.rb文件详解
一.简介 事先说明一下,本篇文章不涉及对redis-trib.rb源代码的分析,只是从使用的角度来阐述一下,对第一次使用的人来说很重要.redis-trib.rb是redis官方推出的管理re ...
- redis简介(keeper实时报表的基本部分)
网上有一篇介绍Redis的文章,由浅入深地讲解了Redis:http://blog.mjrusso.com/2010/10/17/redis-from-the-ground-up.html.强烈建议对 ...
- Redis教程(Linux)
这里汇总了从简单的安装到较为复杂的配置,由浅入深的学习redis... 一 , 安装 1) redis扩展安装 从官网上下载扩展压缩包 wget http://pecl.php.net/get/red ...
- redis lru实现策略
转载自http://blog.chinaunix.net/uid-20708886-id-5753422.html 在使用redis作为缓存的场景下,内存淘汰策略决定的redis的内存使用效率.在大部 ...
- Redis进阶实践之十三 Redis的Redis-trib.rb脚本文件使用详解
转载来源:http://www.cnblogs.com/PatrickLiu/p/8484784.html 一.简介 事先说明一下,本篇文章不涉及对redis-trib.rb源代码的分析,只是从使用的 ...
随机推荐
- 设计模式之面向切面编程AOP
动态的将代码切入到指定的方法.指定位置上的编程思想就是面向切面的编程. 代码只有两种,一种是逻辑代码.另一种是非逻辑代码.逻辑代码就是实现功能的核心代码,非逻辑代码就是处理琐碎事务的代码,比如说获取连 ...
- 小程序 wepy框架 + iview-weapp的用法
最近在弄wepy的时候在想有没有什么ui比较合适一点的wepy的,也是在网上看了好久发现iview还不错.引用简单,上手超快,组件绚丽!当然,这里还介绍下微信官方建议的框架也是和不错的,有需要的可以看 ...
- geodocker-geomesa安装指南
最近研究geopyspark原本以为大数据研究能告一段落,因为... 开玩笑的,还要一起建设社会主义呢!! 背景 geotrellis作为一个处理遥感数据的框架,对于遥感数据支 ...
- Flutter 即学即用系列博客——07 RenderFlex overflowed 引发的思考
背景 在进行 Flutter UI 开发的时候,控制台报出了下面错误: flutter: ══╡ EXCEPTION CAUGHT BY RENDERING LIBRARY >╞════════ ...
- Ubuntu安装apache+Yii2
1.下载Yii2 https://www.yiichina.com/download 2.将解压后的文件放在指定的位置,这里是/home/www/yii/ 3.安装apache2 sudo apt-g ...
- Vim中设置括号自动补全
1.打开用户Vim配置文件:~/.vimrc vim ~/.vimrc 2.输入以下配置: set tabstop=4 inoremap " ""<ESC>i ...
- 使用BCDEDIT创建BCD文件
网上找了好久,总算找到一个完全的BCD文件编辑过程的代码,分享下: ###第1步############################################################ ...
- cmd命令重定向到剪切板
Windows下 使用系统自带的 clip 命令. # 位于 C:\Windows\system32\clip.exe. 示例: # 将字符串 Hello 放入 Windows 剪贴板 echo He ...
- java中的伪泛型---泛型擦除(不需要手工强转类型,却可以调用强转类型的方法)
Java集合如Map.Set.List等所有集合只能存放引用类型数据,它们都是存放引用类型数据的容器,不能存放如int.long.float.double等基础类型的数据. 使用反射可以破解泛型T类型 ...
- JVM回收算法
根搜索算法 原理:设立若干种根对象,当任何一个根对象到某一个对象均不可达时,则认为这个对象是可以被回收的.一般是对象持有的引用指向该对象不可达 在JAVA语言中,可以当做GC roots的对象有以下几 ...