机器学习之梯度提升决策树GBDT
GBDT(Gradient Boosting Decision Tree)
Boosted Tree:一篇很有见识的文章
https://www.zhihu.com/question/54332085
AdaBoost与GBDT的区别
作者:大器不早成
链接:https://www.zhihu.com/question/54332085/answer/281676652
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从回归树到GBDT
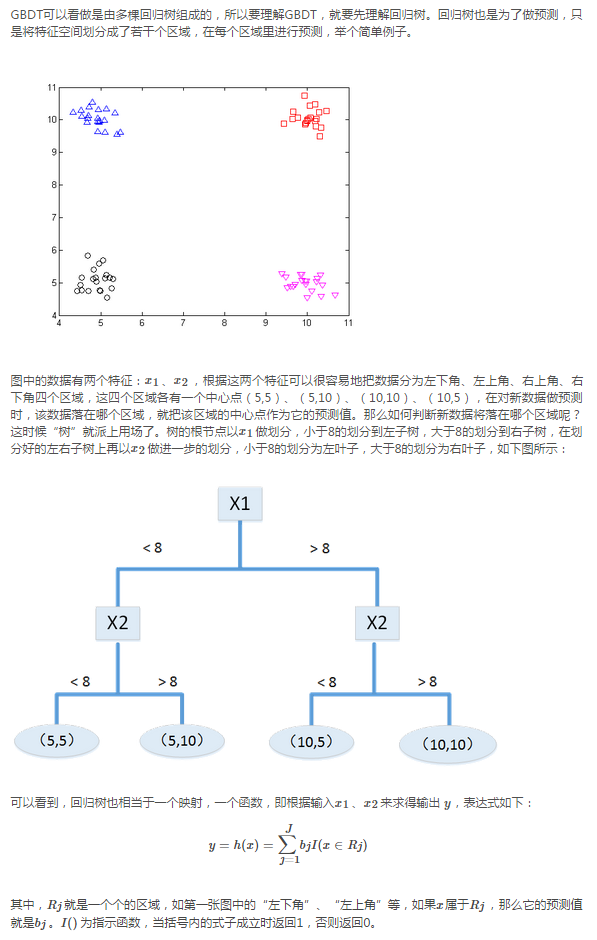


7、GBDT
https://www.2cto.com/kf/201605/509184.html
此处,请仅关注GBDT的流程那个例子
一、DT:回归树RegressionDecisionTree
提起决策树(DT,DecisionTree)绝大部分人首先想到的就是C4.5分类决策树。但如果一开始就把GBDT中的树想成分类树,那就是一条歪路走到黑,一路各种坑,最终摔得都要咯血了还是一头雾水说的就是LZ自己啊有木有。咳嗯,所以说千万不要以为GBDT是很多棵分类树。决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;后者用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。这里要强调的是,前者的结果加减是有意义的,如10岁+5岁-3岁=12岁,后者则无意义,如男+男+女=到底是男是女?GBDT的核心在于累加所有树的结果作为最终结果,就像前面对年龄的累加(-3是加负3),而分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树,不是分类树,这点对理解GBDT相当重要(尽管GBDT调整后也可用于分类但不代表GBDT的树是分类树)。那么回归树是如何工作的呢?
下面我们以对人的性别判别/年龄预测为例来说明,每个instance都是一个我们已知性别/年龄的人,而feature则包括这个人上网的时长、上网的时段、网购所花的金额等。
作为对比,先说分类树,我们知道C4.5分类树在每次分枝时,是穷举每一个feature的每一个阈值,找到使得按照feature<=阈值,和feature>阈值分成的两个分枝的熵最大的feature和阈值(熵最大的概念可理解成尽可能每个分枝的男女比例都远离1:1),按照该标准分枝得到两个新节点,用同样方法继续分枝直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的性别。
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差--即(每个人的年龄-预测年龄)^2的总和/N,或者说是每个人的预测误差平方和除以N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。若还不明白可以Google"RegressionTree",或阅读本文的第一篇论文中RegressionTree部分。
二、GB:梯度迭代GradientBoosting
好吧,我起了一个很大的标题,但事实上我并不想多讲GradientBoosting的原理,因为不明白原理并无碍于理解GBDT中的GradientBoosting。喜欢打破砂锅问到底的同学可以阅读这篇英文wikihttp://en.wikipedia.org/wiki/Gradient_boosted_trees
Boosting,迭代,即通过迭代多棵树来共同决策。这怎么实现呢?难道是每棵树独立训练一遍,比如A这个人,第一棵树认为是10岁,第二棵树认为是0岁,第三棵树认为是20岁,我们就取平均值10岁做最终结论?--当然不是!且不说这是投票方法并不是GBDT,只要训练集不变,独立训练三次的三棵树必定完全相同,这样做完全没有意义。之前说过,GBDT是把所有树的结论累加起来做最终结论的,所以可以想到每棵树的结论并不是年龄本身,而是年龄的一个累加量。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是GradientBoosting在GBDT中的意义,简单吧。
三、GBDT工作过程实例。
还是年龄预测,简单起见训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图1所示结果:

现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:

在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是:A的预测值+A的残差=A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!:
A:14岁高一学生,购物较少,经常问学长问题;预测年龄A=15–1=14
B:16岁高三学生;购物较少,经常被学弟问问题;预测年龄B=15+1=16
C:24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C=25–1=24
D:26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D=25+1=26
那么哪里体现了Gradient呢?其实回到第一棵树结束时想一想,无论此时的costfunction是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1,1,-1,1)都是它的全局最优方向,这就是Gradient。
机器学习之梯度提升决策树GBDT的更多相关文章
- [机器学习]梯度提升决策树--GBDT
概述 GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由 ...
- 机器学习 之梯度提升树GBDT
目录 1.基本知识点简介 2.梯度提升树GBDT算法 2.1 思路和原理 2.2 梯度代替残差建立CART回归树 1.基本知识点简介 在集成学习的Boosting提升算法中,有两大家族:第一是AdaB ...
- 梯度提升决策树(GBDT)
1.提升树 以决策树为基函数的提升方法称为提升树.决策树可以分为分类树和回归树.提升树模型可以表示为决策树的加法模型. 针对不同的问题的提升术算法的主要区别就是损失函数的不同,对于回归问题我们选用平方 ...
- Spark2.0机器学习系列之6:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析
概念梳理 GBDT的别称 GBDT(Gradient Boost Decision Tree),梯度提升决策树. GBDT这个算法还有一些其他的名字,比如说MART(Multiple Addi ...
- GBDT:梯度提升决策树
http://www.jianshu.com/p/005a4e6ac775 综述 GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Ad ...
- chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况
单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序.Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型, ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
随机推荐
- linux下判断文件和目录是否存在
1.前言 工作中涉及到文件系统,有时候需要判断文件和目录是否存在.我结合APUE第四章文件和目录,总结一下如何正确判断文件和目录是否存在,方便以后查询. 2.stat系列函数 stat函数用来返回与文 ...
- Java将数据库数据导入EXCEL
一般的数据库数据怎么导入excel中呢??这让人非常疑惑,今天我找到了一个方法能够实现 须要导入一个第三方包下载地址 详细内容例如以下: 里面含有指导文档,index.html里面含有怎样读取数据库文 ...
- 超低压差LDO XC6206P332MR
XC6206:It is selectable in 0.1V increments within a range of 1.2V to 5.0V. 可实现压差为0.1V的降压,最大输出电流200毫安 ...
- npm 国内淘宝镜像cnpm、设置淘宝源
1.下载和使用cnpm 某些插件很奇怪,需要用国内的镜像下载才可以 #安装淘宝镜像npm install cnpm -g --registry=https://registry.npm.taobao. ...
- Flask教程 —— Web表单(上)
第二章中介绍的request对象公开了所有客户端发送的请求信息.特别是request.form可以访问POST请求提交的表单数据. 尽管Flask的request对象提供的支持足以处理web表单,但依 ...
- yii2 关系...
link($name) 会使用..get$name...即有hasmany和hasone... // update lazily loaded related objects if (!$relati ...
- 【Java】创建线程对象两种方式
1.继承Thread类,重载run方法: Thread t = new Thread(new Runnable() { @Override public void run() { // TODO Au ...
- tomcat logs 目录下各日志文件的含义
tomcat每次启动时,自动在logs目录下生产以下日志文件,按照日期自动备份 localhost.2016-07-05.txt //经常用到的文件之一 ,程序异常没有被捕获的时候抛出的地方 ca ...
- c++之——template模板函数
为了实现与数据类型无关的编程,模板应运而生: #include<iostream> #include<string.h> using namespace std; templa ...
- C语言 · 贪心算法
发现蓝桥杯上好多题目涉及到贪心,决定学一学. 贪心算法是指在对问题求解时,总是做出在当前看来是最好的选择.也就是说:不从整体最优上考虑,而是在某种意义上的局部最优解.其关键是贪心策略的选择,选择的贪心 ...