对Spark2.2.0文档的学习3-Spark Programming Guide
Spark Programming Guide
Link:http://spark.apache.org/docs/2.2.0/rdd-programming-guide.html
每个Spark Application包含一个driver程序(运行main方法)以及在集群中执行不同的并行操作。
Spark的一级抽象是RDD(2.0之后推荐使用Dataset)划分在不同节点上的元素的集合支持并行处理和自动的故障恢复。
RDD的创建:(1)a file in the Hadoop file system (or any other Hadoop-supported file system),(2) an existing Scala collection in the driver program,(3) transforming it.
用户可以persist RDD到内存中,以便高效重用
By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task.
Spark的二级抽象是shared variables 支持并行操作的共享变量,共享变量用于Task之间以及Task和Driver程序之间。Spark支持两种类型的共享变量,broadcast variables(cache a value in memory on all nodes),accumulators(which are variables that are only “added” to, such as counters and sums.)
Linking with Spark
写Spark应用,需要添加Spark的Maven依赖,如果需要访问HDFS,需要添加HDFS的Maven依赖,然后在程序中添加Spark相关的包。
Initializing Spark
通过SparkConf对象创建SparkContext对象,告诉Spark如何访问一个集群。

masteris a Spark, Mesos or YARN cluster URL, or a special “local” string to run in local mode,一般是使用spark-summit脚本来指定master,而不是在程序中硬编码
Using the Shell
$SPARK_HOME/bin/spark-shell可以指定一些参数
Resilient Distributed Datasets (RDDs)
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
创建RDDs的两种方式:(1)parallelizing an existing collection in your driver program
(2) referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
(1) Parallelized Collections
SparkContext的parallelize方法可以将集合并行化,即将集合中的元素进行拷贝,形成分布式的数据集,从而实现并行操作。
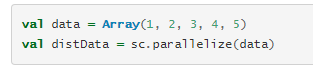
parallelize方法可以带两个参数,第二个参数指定the number of partitions to cut the dataset into。Spark在每个partition上运行一个Task。
(2)External Datasets
Spark可以通过Hadoop支持的任意数据源创建RDD,包括local file system, HDFS, Cassandra, HBase, Amazon S3, etc. Spark supports text files, SequenceFiles, and any other Hadoop InputFormat.
SparkContext的textFile(URI)方法可以创建RDD,

Note:
(1)如果是本地文件系统,那么textFile在每个worker节点上被访问的路径应该是相同的,可以将textFile复制到不同的节点中或者使用网络挂载的文件系统
(2)Spark所有基于文件的输入方法支持目录、压缩文件、通配符
(3)textFile方法可以有俩个参数,第二个参数代表文件被划分成的partition的数量。By default, Spark creates one partition for each block of the file (blocks being 128MB by default in HDFS), but you can also ask for a higher number of partitions by passing a larger value. Note that you cannot have fewer partitions than blocks.
除了文本文件,Spark还支持
(1) SparkContext.wholeTextFiles,a directory containing multiple small text files, and returns each of them as (filename, content) pairs.
(2) For SequenceFiles, use SparkContext’s sequenceFile[K, V] method where K and V are the types of key and values in the file
(3) For other Hadoop InputFormats, you can use the SparkContext.hadoopRDD method
(4) RDD.saveAsObjectFile and SparkContext.objectFile support saving an RDD in a simple format consisting of serialized Java objects. While this is not as efficient as specialized formats like Avro, it offers an easy way to save any RDD.
RDD Operations
RDD支持两种操作
(1) transformations,create a new dataset from an existing one
(2) actions,return a value to the driver program after running a computation on the dataset.
例如map是一种transformation,reduce是一种action。(但是parallel reduceByKey that returns a distributed dataset)
为了高效性,Spark中所有的transformation都是Lazy的,The transformations are only computed when an action requires a result to be returned to the driver program. 例如一般使用map都是想再通过reduce得到一个结果,因此Lazy。默认情况下, each transformed RDD may be recomputed each time you run an action on it,因此为了高效性可以使RDD驻留在内存中,通过persist或者cache。也有将RDD存储到磁盘中以及在不同节点之间复制RDD的方法。
Basics

第一行定义RDD,This dataset is not loaded in memory or otherwise acted on: lines is merely a pointer to the file.
第二行的lineLengths没有被立即计算,由于Lazy
reduce那行将计算分成任务,交给不同的机器,每个机器执行它对应的map任务和本地的reduction,最终向driver程序返回结果
Passing Functions to Spark
Spark的API时常需要将函数传递到driver程序中,两种推荐的方法
(1)Anonymous function syntax, which can be used for short pieces of code.
(2)Static methods in a global singleton object.
Understanding closures
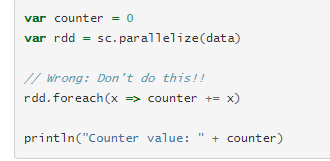
在executors执行之前,Spark会先计算闭包。The closure is those variables and methods which must be visible for the executor to perform its computations on the RDD (in this case foreach()).闭包通过序列化传递给每executor。发送给每个executor的闭包中的变量是counter的拷贝,而不是driver程序中的counter,因此主程序中的counter对executors是不可见的。集群环境下运行以上代码counter的结果是0。而在local mode下有可能得到正确的结果,但是不要这么用。可以使用Spark提供的Accumulator实现全局的聚合。
Printing elements of an RDD
rdd.foreach(println)或者rdd.map(println)
单机模式下:可以打印出所有rdd的元素
集群模式下:结果会被输出到executor的stdout中,而不是driver节点的stdout中。
如果想在driver节点看到rdd的结果:
(1) rdd.collect().foreach(println),将所有的rdd加载到driver的内存中,可能会oom
(2) 只想取出一部分元素,比如取出100个。rdd.take(100).foreach(println).
Working with Key-Value Pairs
大部分的操作对于包含任意对象的RDD都可以执行,不过有的操作只能操作包含key-value对的RDD,最常见的就是分布式的shuffle操作,例如grouping or aggregating the elements by a key
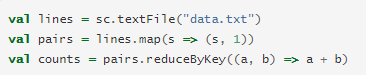
reduceByKey operation on key-value pairs to count how many times each line of text occurs in a file
use counts.sortByKey(), for example, to sort the pairs alphabetically, and finally counts.collect() to bring them back to the driver program as an array of objects.
注意:用户自定义类型作为key,需要重写equals方法和hashcode方法
Transformations &Actions
http://spark.apache.org/docs/2.2.0/api/scala/index.html#package
Shuffle operations
(1)Spark的shuffle操作将不同partition的数据重新分布,通常包括将数据在不同的executors和机器之间的拷贝,是一个复杂且耗时的操作(disk I/O, data serialization, and network I/O.)。能够引发Shuffle的一些操作:repartition operations like repartition and coalesce, ‘ByKey operations (except for counting) like groupByKey and reduceByKey, and join operations like cogroup and join.
(2)每个partition由一个Task进行计算。以reduceByKey为例,由于同一个key的不同value可能分布在不同的partition或者机器, It must read from all partitions to find all the values for all keys, and then bring together values across partitions to compute the final result for each key - this is called the shuffle.
(3)shuffle操作会占用很大的堆内存和磁盘空间
RDD Persistence
为了在之后继续使用RDD或Dataset,可以将他们通过persist方法或者cache方法(fault-tolerant)持久化,持久化的时机:The first time it is computed in an action, it will be kept in memory on the nodes.
可以指定StorageLevel来决定将RDD persist到哪里,disk,memory ,serialized Java objects (to save space), replicate it across nodes.
Which Storage Level to Choose?
trade-offs between memory usage and CPU efficiency
- If your RDDs fit comfortably with the default storage level (
MEMORY_ONLY), leave them that way. This is the most CPU-efficient option, allowing operations on the RDDs to run as fast as possible. - If not, try using
MEMORY_ONLY_SERand selecting a fast serialization library to make the objects much more space-efficient, but still reasonably fast to access. (Java and Scala) - Don’t spill to disk unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk.
- Use the replicated storage levels if you want fast fault recovery (e.g. if using Spark to serve requests from a web application). All the storage levels provide full fault tolerance by recomputing lost data, but the replicated ones let you continue running tasks on the RDD without waiting to recompute a lost partition.
Removing Data
Spark自动监视每个节点上的cache使用率,通过Least-recently-used (LRU)的方式自动remove旧的数据。用户也可以使用RDD.unpersist()方法.
Shared Variables
Normally, when a function passed to a Spark operation (such as map or reduce) is executed on a remote cluster node, it works on separate copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are propagated back to the driver program. Supporting general, read-write shared variables across tasks would be inefficient.
Driver程序中rdd的操作传递进来函数,然后rdd的具体计算在每个节点上的executor上执行,这些节点上操作的变量都是独立的,并且不会将操作结果返回给driver程序。
Spark提供两种共享变量:(1)broadcast variables (2)accumulators
Broadcast Variables
read-only variable cached on each machine rather than shipping a copy of it with tasks.
Spark actions are executed through a set of stages, separated by distributed “shuffle” operations. Spark automatically broadcasts the common data needed by tasks within each stage. The data broadcasted this way is cached in serialized form and deserialized before running each task. This means that explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.
创建方式:SparkContext.broadcast(v)

得到广播变量之后,应该使用得到的广播变量而不是原来的变量v,并且创建广播变量之后不要改变v。
Accumulators
Accumulators are variables that are only “added” to through an associative and commutative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types.
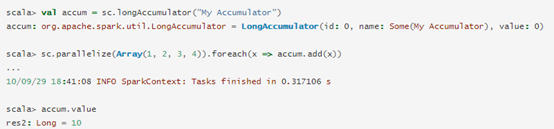
numeric accumulator可以通过SparkContext创建,
SparkContext.longAccumulator()
集群中的Task可以向accumulator中使用add方法,但是不能读取accumulator的值。只有Driver程序可以使用value方法访问accumulator的值
用户可以通过继承AccumulatorV2实现自己的Accumulator,需要实现的方法:
reset for resetting the accumulator to zero,
add for adding another value into the accumulator,
merge for merging another same-type accumulator into this one

For accumulator updates performed inside actions only, Spark guarantees that each task’s update to the accumulator will only be applied once, i.e. restarted tasks will not update the value. In transformations, users should be aware of that each task’s update may be applied more than once if tasks or job stages are re-executed.
每个task对accumulator的更新只会应用一次,重启任务不会更新accumulator的值。但是task的更新可能会随着task的重新执行,被执行多次
Accumulator不会改变Spark的Lazy的特点。如果在RDD的操作中更新accumulator,只有RDD执行action的时候,才会改变accumulator的值。因此在执行map的时候,accumulator的值不会改变
对Spark2.2.0文档的学习3-Spark Programming Guide的更多相关文章
- 对Spark2.2.0文档的学习2-Job Scheduling
Job Scheduling Link:http://spark.apache.org/docs/2.2.0/job-scheduling.html 概况: (1)集群中多个应用的调度主要考虑的是不同 ...
- 对Spark2.2.0文档的学习1-Cluster Mode Overview
Cluster Mode Overview Link:http://spark.apache.org/docs/2.2.0/cluster-overview.html Spark应用(Applicat ...
- webpack搭建vue项目开发环境【文档向学习】
为何有这篇文章 各个社区已经有无数篇帖子介绍如何使用webpack搭建前端项目,但无论是出于学习webpack的目的还是为了解决工作实际需要都面临着一个现实问题,那就是版本更新.别人的帖子可能刚写好版 ...
- vue mand-mobile按2.0文档默认安装的是1.6.8版本
vue mand-mobile按2.0文档默认安装的是1.6.8版本 npm list mand-mobilebigbullmobile@1.0.0 E:\webcode\bigbullmobile` ...
- Beautiful Soup 4.2.0 文档
Beautiful Soup 4.2.0 文档 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方 ...
- css2.0文档查阅及字体样式
css2.0文档查阅下载 网址:http://soft.hao123.com/soft/appid/9517.html <html xmlns="http://www.w3.o ...
- Unity shader 官网文档全方位学习(一)
转载:https://my.oschina.net/u/138823/blog/181131 摘要: 这篇文章主要介绍Surface Shaders基础及Examples详尽解析 What?? Sha ...
- C# 动态生成word文档 [C#学习笔记3]关于Main(string[ ] args)中args命令行参数 实现DataTables搜索框查询结果高亮显示 二维码神器QRCoder Asp.net MVC 中 CodeFirst 开发模式实例
C# 动态生成word文档 本文以一个简单的小例子,简述利用C#语言开发word表格相关的知识,仅供学习分享使用,如有不足之处,还请指正. 在工程中引用word的动态库 在项目中,点击项目名称右键-- ...
- 【PyTorch v1.1.0文档研习】60分钟快速上手
阅读文档:使用 PyTorch 进行深度学习:60分钟快速入门. 本教程的目标是: 总体上理解 PyTorch 的张量库和神经网络 训练一个小的神经网络来进行图像分类 PyTorch 是个啥? 这是基 ...
随机推荐
- bootsrtap带表格面板内容居中
css中,添加 .table th, .table td { text-align: center; vertical-align: middle!important;}
- QT-2D编程
QT-[转]2D编程 Qt中提供了强大的2D绘图系统,可以使用相同的API在屏幕上和绘图·设备上进行绘制,主要基于QPainter.QPainterDevice和QPainterEngine这3个类. ...
- dsp6657的helloworld例程测试-第一篇
环境搭建可以参考http://blog.sina.com.cn/s/blog_ed2e19900102xi2j.html 1. 先从mcsdk导入工程,helloworld例程 2. 提示有错误,估计 ...
- 在BAE上部署Pomelo
BAE升级到3.0后顿时感觉好用了很多,俨然云主机的感觉. 底下我将分享我在BAE上部署Pomelo的过程. 首先需要拥有一个BAE的执行单元.没有的可以自行百度并部署. 接着svn得出代码到本地.此 ...
- GitHub中webhooks的使用
目录 GitHub中的webhooks的配置 对配置的webhooks的进行测试 目前在团队在设计一个应用管理的功能,需要了解到常用代码托管的Webhooks的使用.GitHub中的webhooks首 ...
- 教你thinkphp5怎么配置二级域名
有些项目要将移动端和PC端分离开来,比如访问xxx.com,展示的是PC端的页面.而访问m.xxx.com,展示的是移动端的页面.thinkphp源码需要多多学习,这里记录一下知识点,顺便分享给需要的 ...
- 爬虫2.4-scrapy框架-图片分类下载
目录 scrapy框架-图片下载 1 传统下载方法: 2 scrapy框架的下载方法 3 分类下载完整代码 scrapy框架-图片下载 python小知识: map函数:将一个可迭代对象的每个值,依次 ...
- 爬虫2.3-scrapy框架-post、shell、验证码
目录 scrapy框架-post请求和shell 1. post请求 2. scrapy shell 3. 验证码识别 scrapy框架-post请求和shell 1. post请求 scrapy框架 ...
- 基于marathon-lb的服务自发现与负载均衡
参考文档: Marathon-lb介绍:https://docs.mesosphere.com/1.9/networking/marathon-lb/ 参考:http://www.cnblogs.co ...
- 阿里与ShopRunner达成协议 联手在国内推出服务
阿里巴巴集团与美国在线零售商 ShopRunner 达成协议,将帮助后者在中国大陆销售商品和履行订单交付产品. ShopRunner 首席战略官菲奥娜·迪亚斯(Fiona Dias)周三接受媒体采访时 ...