Spark Shuffle(二)Executor、Driver之间Shuffle结果消息传递、追踪(转载)
1. 前言
2. StatusUpdate消息
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) {
val msg = StatusUpdate(executorId, taskId, state, data)
driver match {
case Some(driverRef) => driverRef.send(msg)
case None => logWarning(s"Drop $msg because has not yet connected to driver")
}
}
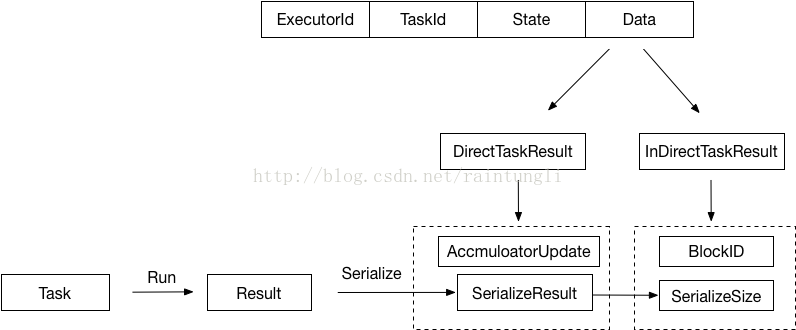
- ExecutorId: Executor自己的ID
- TaskId: task分配的ID
- State: Task的运行状态
LAUNCHING, RUNNING, FINISHED, FAILED, KILLED, LOST
- Data: 保存序列化的Result
2.1 Executor端发送
- 最大的返回结果大小,如果超过设定的最大返回结果时,返回的结果内容会被丢弃,只是返回序列化的InDirectTaskResult,里面包含着BlockID和序列化后的结果大小
spark.driver.maxResultSize
- 最大的直接返回结果大小:如果返回的结果大于最大的直接返回结果大小,小于最大的返回结果大小,采用了保存的折中的策略,将序列化DirectTaskResult保存到BlockManager中,关于BlockManager可以参考前面写的BlockManager系列,返回InDirectTaskResult,里面包含着BlockID和序列化的结果大小
spark.task.maxDirectResultSize
- 直接返回:如果返回的结果小于等于最大的直接返回结果大小,将直接将序列化的DirectTaskResult返回给Driver端
val serializedResult: ByteBuffer = {
if (maxResultSize > && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
2.2 Driver端接收
Driver端处理StatusUpdate的消息的代码如下:
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
scheduler实例是TaskSchedulerImpl.scala
if (TaskState.isFinished(state)) {
cleanupTaskState(tid)
taskSet.removeRunningTask(tid)
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
}
statusUpdate函数调用了enqueueSuccessfulTask方法
def enqueueSuccessfulTask(
taskSetManager: TaskSetManager,
tid: Long,
serializedData: ByteBuffer): Unit = {
getTaskResultExecutor.execute(new Runnable {
override def run(): Unit = Utils.logUncaughtExceptions {
try {
val (result, size) = serializer.get().deserialize[TaskResult[_]](serializedData) match {
case directResult: DirectTaskResult[_] =>
if (!taskSetManager.canFetchMoreResults(serializedData.limit())) {
return
}
// deserialize "value" without holding any lock so that it won't block other threads.
// We should call it here, so that when it's called again in
// "TaskSetManager.handleSuccessfulTask", it does not need to deserialize the value.
directResult.value(taskResultSerializer.get())
(directResult, serializedData.limit())
case IndirectTaskResult(blockId, size) =>
if (!taskSetManager.canFetchMoreResults(size)) {
// dropped by executor if size is larger than maxResultSize
sparkEnv.blockManager.master.removeBlock(blockId)
return
}
logDebug("Fetching indirect task result for TID %s".format(tid))
scheduler.handleTaskGettingResult(taskSetManager, tid)
val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId)
if (!serializedTaskResult.isDefined) {
/* We won't be able to get the task result if the machine that ran the task failed
* between when the task ended and when we tried to fetch the result, or if the
* block manager had to flush the result. */
scheduler.handleFailedTask(
taskSetManager, tid, TaskState.FINISHED, TaskResultLost)
return
}
val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]](
serializedTaskResult.get.toByteBuffer)
// force deserialization of referenced value
deserializedResult.value(taskResultSerializer.get())
sparkEnv.blockManager.master.removeBlock(blockId)
(deserializedResult, size)
} // Set the task result size in the accumulator updates received from the executors.
// We need to do this here on the driver because if we did this on the executors then
// we would have to serialize the result again after updating the size.
result.accumUpdates = result.accumUpdates.map { a =>
if (a.name == Some(InternalAccumulator.RESULT_SIZE)) {
val acc = a.asInstanceOf[LongAccumulator]
assert(acc.sum == 0L, "task result size should not have been set on the executors")
acc.setValue(size.toLong)
acc
} else {
a
}
} scheduler.handleSuccessfulTask(taskSetManager, tid, result)
} catch {
case cnf: ClassNotFoundException =>
val loader = Thread.currentThread.getContextClassLoader
taskSetManager.abort("ClassNotFound with classloader: " + loader)
// Matching NonFatal so we don't catch the ControlThrowable from the "return" above.
case NonFatal(ex) =>
logError("Exception while getting task result", ex)
taskSetManager.abort("Exception while getting task result: %s".format(ex))
}
}
})
}
2.2.1 DirectTaskResult处理过程
- 直接反序列化成DirectTaskResult,反序列化后进行了整体返回内容的大小的判断,在前面的2.1中介绍参数:spark.driver.maxResultSize,这个参数是Driver端的参数控制的,在Spark中会启动多个Task,参数的控制是一个整体的控制所有的Tasks的返回结果的数量大小,当然单个task使用该筏值的控制也是没有问题,因为只要有一个任务返回的结果超过maxResultSize,整体返回的数据也会超过maxResultSize。
- 对DirectTaskResult里的result进行了反序列化。
2.2.2 InDirectTaskResult处理过程
- 通过size判断大小是否超过spark.driver.maxResultSize筏值控制
- 通过BlockManager来获取BlockID的内容反序列化成DirectTaskResult
- 对DirectTaskResult里的result进行了反序列化
最后调用handleSuccessfulTask方法
sched.dagScheduler.taskEnded(tasks(index), Success, result.value(), result.accumUpdates, info)
回到了Dag的调度,向eventProcessLoop的队列里提交了CompletionEvent的事件
def taskEnded(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Seq[AccumulatorV2[_, _]],
taskInfo: TaskInfo): Unit = {
eventProcessLoop.post(
CompletionEvent(task, reason, result, accumUpdates, taskInfo))
}
2.3 MapOutputTracker

2.3.1 RegisterMapOutput
def compressSize(size: Long): Byte = {
if (size == ) {
} else if (size <= 1L) {
} else {
math.min(, math.ceil(math.log(size) / math.log(LOG_BASE)).toInt).toByte
}
}
private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
............
case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
updateAccumulators(event)
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from executor $execId")
} else {
shuffleStage.addOutputLoc(smt.partitionId, status)
}
if (runningStages.contains(shuffleStage) && shuffleStage.pendingPartitions.isEmpty) {
markStageAsFinished(shuffleStage)
logInfo("looking for newly runnable stages")
logInfo("running: " + runningStages)
logInfo("waiting: " + waitingStages)
logInfo("failed: " + failedStages)
// We supply true to increment the epoch number here in case this is a
// recomputation of the map outputs. In that case, some nodes may have cached
// locations with holes (from when we detected the error) and will need the
// epoch incremented to refetch them.
// TODO: Only increment the epoch number if this is not the first time
// we registered these map outputs.
mapOutputTracker.registerMapOutputs(
shuffleStage.shuffleDep.shuffleId,
shuffleStage.outputLocInMapOutputTrackerFormat(),
changeEpoch = true)
clearCacheLocs()
if (!shuffleStage.isAvailable) {
// Some tasks had failed; let's resubmit this shuffleStage
// TODO: Lower-level scheduler should also deal with this
logInfo("Resubmitting " + shuffleStage + " (" + shuffleStage.name +
") because some of its tasks had failed: " +
shuffleStage.findMissingPartitions().mkString(", "))
submitStage(shuffleStage)
} else {
// Mark any map-stage jobs waiting on this stage as finished
if (shuffleStage.mapStageJobs.nonEmpty) {
val stats = mapOutputTracker.getStatistics(shuffleStage.shuffleDep)
for (job <- shuffleStage.mapStageJobs) {
markMapStageJobAsFinished(job, stats)
}
}
submitWaitingChildStages(shuffleStage)
}
}
当处理shuffleMapTask的结果的时候,mapOutputTracker.registerMapOutputs进行了MapOutputs的注册
protected val mapStatuses = new ConcurrentHashMap[Int, Array[MapStatus]]().asScala
def registerMapOutputs(shuffleId: Int, statuses: Array[MapStatus], changeEpoch: Boolean = false) {
mapStatuses.put(shuffleId, statuses.clone())
if (changeEpoch) {
incrementEpoch()
}
}
2.3.2 获取MapStatus
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * * ,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
通过getMapSizesByExecutorId获取ShuffledId所对应的MapStatus
def getMapSizesByExecutorId(shuffleId: Int, startPartition: Int, endPartition: Int)
: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = {
logDebug(s"Fetching outputs for shuffle $shuffleId, partitions $startPartition-$endPartition")
val statuses = getStatuses(shuffleId)
// Synchronize on the returned array because, on the driver, it gets mutated in place
statuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, startPartition, endPartition, statuses)
}
}
在getStatuses方法中
private def getStatuses(shuffleId: Int): Array[MapStatus] = {
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) {
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
val startTime = System.currentTimeMillis
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
// Someone else is fetching it; wait for them to be done
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
// Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId
}
}
if (fetchedStatuses == null) {
// We won the race to fetch the statuses; do so
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
// This try-finally prevents hangs due to timeouts:
try {
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
logDebug(s"Fetching map output statuses for shuffle $shuffleId took " +
s"${System.currentTimeMillis - startTime} ms")
if (fetchedStatuses != null) {
return fetchedStatuses
} else {
logError("Missing all output locations for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, -, "Missing all output locations for shuffle " + shuffleId)
}
} else {
return statuses
}
}
- 封装了一层缓存mapStatus,对同一个Executor来说,里面的线程都是运行同一个Driver的提交的任务,对相同的shuffeID,MapStatus是一样的
- 对同一个Executor、ShuffeID来说,通过Driver获取信息只需要一次,Driver里保存的Shuffle的结果是单点的,对同一个Executor来说获取同一个ShuffleID只需要请求一次,在Traker里面保存了一个队列fetching,里面保存的ShuffeID代表的是有线程正在从Driver端获取ShuffleID的MapStatus,如果发现有值,当前线程会等待,直到其他的线程获取ShuffleID状态并保存到缓存结束,当前线程直接从缓存中获取当前状态
- Executor 向Driver发送GetMapOutputStatuses(shuffleId)消息
- Driver收到GetMapOutputStatuses消息后保存到消息队列mapOutputRequests,Map-Output-Dispatcher-x多线程处理消息队列,返回序列化的MapStatus
- Executor反序列化成MapStatus
2.2.3 以BlockManagerId为key的Shuffle的序列

private def convertMapStatuses(
shuffleId: Int,
startPartition: Int,
endPartition: Int,
statuses: Array[MapStatus]): Seq[(BlockManagerId, Seq[(BlockId, Long)])] = {
assert (statuses != null)
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(BlockId, Long)]]
for ((status, mapId) <- statuses.zipWithIndex) {
if (status == null) {
val errorMessage = s"Missing an output location for shuffle $shuffleId"
logError(errorMessage)
throw new MetadataFetchFailedException(shuffleId, startPartition, errorMessage)
} else {
for (part <- startPartition until endPartition) {
splitsByAddress.getOrElseUpdate(status.location, ArrayBuffer()) +=
((ShuffleBlockId(shuffleId, mapId, part), status.getSizeForBlock(part)))
}
}
} splitsByAddress.toSeq
}
Spark Shuffle(二)Executor、Driver之间Shuffle结果消息传递、追踪(转载)的更多相关文章
- [Spark性能调优] 第三章 : Spark 2.1.0 中 Sort-Based Shuffle 产生的内幕
本課主題 Sorted-Based Shuffle 的诞生和介绍 Shuffle 中六大令人费解的问题 Sorted-Based Shuffle 的排序和源码鉴赏 Shuffle 在运行时的内存管理 ...
- Spark Executor Driver资源调度小结【转】
一.引子 在Worker Actor中,每次LaunchExecutor会创建一个CoarseGrainedExecutorBackend进程,Executor和CoarseGrainedExecut ...
- Spark Executor Driver资源调度汇总
一.简介 于Worker Actor于,每次LaunchExecutor这将创建一个CoarseGrainedExecutorBackend流程.Executor和CoarseGrainedExecu ...
- 大数据:Spark Core(二)Driver上的Task的生成、分配、调度
1. 什么是Task? 在前面的章节里描写叙述过几个角色,Driver(Client),Master,Worker(Executor),Driver会提交Application到Master进行Wor ...
- Spark Core(二)Driver上的Task的生成、分配、调度(转载)
1. 什么是Task? 在前面的章节里描述过几个角色,Driver(Client),Master,Worker(Executor),Driver会提交Application到Master进行Worke ...
- Spark源码分析之Sort-Based Shuffle读写流程
一 .概述 我们知道Spark Shuffle机制总共有三种: 1.未优化的Hash Shuffle:每一个ShuffleMapTask都会为每一个ReducerTask创建一个单独的文件,总的文件数 ...
- Spark 调优之ShuffleManager、Shuffle
Shuffle 概述 影响Spark性能的大BOSS就是shuffle,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作. 因此,如果要让作业的性能更上一层楼,就有必要对 shuffle 过 ...
- 大话Spark(4)-一文理解MapReduce Shuffle和Spark Shuffle
Shuffle本意是 混洗, 洗牌的意思, 在MapReduce过程中需要各节点上同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程成为Shuffle. 在Ha ...
- Spark Tungsten揭秘 Day2 Tungsten-sort Based Shuffle
Spark Tungsten揭秘 Day2 Tungsten-sort Based Shuffle 今天在对钨丝计划思考的基础上,讲解下基于Tungsten的shuffle. 首先解释下概念,Tung ...
随机推荐
- JBPM4.4_jBPM4.4的流程定义语言(设计流程)
1. jBPM4.4的流程定义语言(设计流程) 1.1. process(流程) 是.jpdl.xml的根元素,可以指定的属性有: 属性名 作用说明 name 流程定义的名称,用于显示. key 流程 ...
- python 数据类型详解(转)
转自:http://www.cnblogs.com/linjiqin/p/3608541.html 目录1.字符串2.布尔类型3.整数4.浮点数5.数字6.列表7.元组8.字典9.日期 1.字符串1. ...
- m4a文件在iOS上的流媒体播放
Date: 2016-03-23 Title: m4a文件在iOS上的流媒体播放 Tags: m4a, mp4, iOS, Android URL: m4a-streaming-play-on-mob ...
- 开源的PaaS方案:在OpenStack上部署CloudFoundry (一)简介
目录(?)[-] OpenStack简介 OpenStack是一个美国国家航空航天局和Rackspace合作研发的以Apache许可证授权并且是一个自由软件和开放源代码项目 OpenStack是一个云 ...
- Java中UDP协议的基本原理和简单用法
UDP协议是非面向连接的,相对于TCP协议效率较高,但是不安全.UDP协议类似发信息的过程,不管接收方是在线还是关机状态,都会把信息发送出去.但是如果接收方不处于接收信息的状态,发送出去的数据包就会丢 ...
- $.data(elem, key, val) 和 elem.data(key, val)
var div1 = $("div"), div2 = $("div"); 1. div1.data("key", &quo ...
- 【BZOJ4423】[AMPPZ2013]Bytehattan 对偶图+并查集
[BZOJ4423][AMPPZ2013]Bytehattan Description 比特哈顿镇有n*n个格点,形成了一个网格图.一开始整张图是完整的.有k次操作,每次会删掉图中的一条边(u,v), ...
- 一个Activity中使用两个layout实例
package com.sbs.aas2l; import android.app.Activity; import android.os.Bundle; import android.view.Vi ...
- 线段树(成段更新,区间求和lazy操作 )
hdu1556 Color the ball Time Limit: 9000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- 【node】---socket---网络通信---【巷子】
1.什么是一个socket? 网络上两个程序通过一个双向的通信连接实现数据交换,这个连接的一端称为socket 2.http与socket的区别 在以前我们实现数据交换已经有了HTTP协议,为什么还要 ...