redis单节点集群
一、概念
redis是一种支持Key-Value等多种数据结构的存储系统。可用于缓存、事件发布或订阅、高速队列等场景。该数据库使用ANSI C语言编写,支持网络,提供字符串、哈希、列表、队列、集合结构直接存取,基于内存,可持久化。
二、redis的应用场景有哪些
1、会话缓存(最常用)
2、消息队列,比如支付
3、活动排行榜或计数
4、发布、订阅消息(消息通知)
5、商品列表、评论列表等
1.redis安装:
# wget http://download.redis.io/releases/redis-4.0.6.tar.gz
# yum install gcc
# make MALLOC=libc
# cd src && make install
# ./redis-server
2.修改配置文件:
# vim ../redis.conf
daemonize yes #以后台进程方式启动
#bind 127.0.0.1 #允许本地连接
requirepass redhat #设置连接密码
3.后台启动:
# ./redis-server /root/redis-4.0./redis.conf
4.登录:
# redis-cli -h 127.0.0.1 -p
认证:
auth redhat
5.redis数据类型:
字符串(string):set bp 123 #设置字符串类型bp 值为122
hget ID name #获取散列名ID的name对应的值
hgetall ID #获取散列ID的全部值
hmset age name linux kali contos debian #一次性设置散列age的值
hdel ood name #删除某个散列的值
hexists age kali #判断某个散列的值是否存在,0不存在
散列(hash):hset ID(散列名) name(键) passwd(值) #设置散列名ID存放的值对
hget ID name #获取散列名ID的name对应的值
hgetall ID #获取散列ID的全部值
hmset age name linux kali contos debian #一次性设置散列age的值
hdel ood name #删除某个散列的值
hexists age kali #判断某个散列的值是否存在,0不存在
列表(list):lpush test 1 #列表名为test,从左边加入1,编号为最后一位数
rpush test - #列表名为test,从右边加入-,编号为0
llen test #列表长度
lpop test #左边出去一个数
rpop test #右边出去一个数
lrange test #列表下标从0开始计算,显示第三个数和第四个数
lrem test #左数删除1个3
lindex test #获取2的下标
ltrim test #test取截取(删除)出来的下标0到2对应的值
集合(set):sadd linux a b c d e a b #增加linux集合,集合内容为a b c d e ,不能出现相同数据
srem linux d e #删除linux集合中的d e元素
smembers linux #查看linux的元素
sismember linux d #查看d是否是集合linux的元素,否
sdiff linux centos #两个集合取差集,(顺序不同,结果不同)
sinter linux centos #取交集
sunion linux centos #取并集
有序集合(zset):zadd test1 10(值) a(键) #增加test1有序集合,分数为10 等级为a
zrem test1 b #移除test1的等级b的值
zscore test1 a #查看test1的等级a的值
zrange test1 #查看test1第一个和第二个的值
zrangebyscore test1 #根据分数查看对应的的等级
三、redis持久化
1.RDB持久化
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,将Redis内存中的数据,完整的生成一个快照,以二进制格式文件(后缀RDB)保存在硬盘当中。当需要进行恢复时,再从硬盘加载到内存中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。但是一旦发生故障,可能会丢失几分钟的数据。
触发:
1.配置文件:
#vim redis.conf
save // 900内,有1条写入,则产生快照
save // 如果300秒内有1000次写入,则产生快照
save // 如果60秒内有10000次写入,则产生快照
stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入? 主进程不停止 容易造成数据不一致
rdbcompression yes // 导出的rdb文件是否压缩,如果rdb的大小很大的话建议这么做
Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性 验证版本是不是一致
dbfilename dump.rdb //导出来的rdb文件名
dir ./ //rdb的放置路径
2.手动:save(同步)
bgsave(异步)
2.AOF持久化
AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂,AOF 文件是一个只进行追加操作的日志文件
触发:
#vim redis.conf
appendonly no // 是否打开aof日志功能,aof跟rdb都打开的情况下
appendfsync always // 每1个命令,都立即同步到aof.安全,速度慢
appendfsync everysec // 折衷方案,每秒写1次
appendfsync no // 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快,
no-appendfsync-on-rewrite yes: // 正在导出rdb快照的过程中,要不要停止同步aof
auto-aof-rewrite-percentage 100 //aof文件大小比起上次重写时的大小,增长率100%时,重写缺点刚开始的时候重复重写多次
auto-aof-rewrite-min-size 64mb //aof文件,至少超过64M时,重写
3.测试使用 redis-benchmark -n 10000 ::表示 执行请求10000次
四,单节点集群
.创建集群目录:# mkdir /usr/local/redis-cluster # wget http://download.redis.io/releases/redis-3.0.6.tar.gz
.解压6次到该目录:# tar zxvf redis-3.0..tar.gz -C /usr/local/redis-cluster
.编译安装:# make MALLOC=libc
# cd src && make install
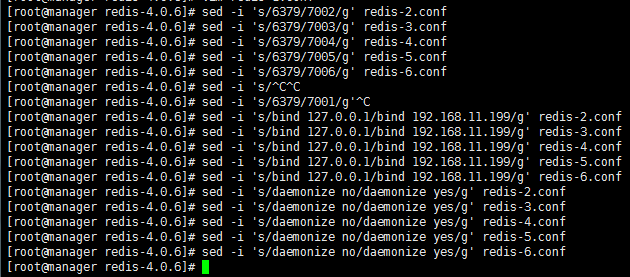
.修改绑定IP:# sed -i 's/bind 127.0.0.1/bind 192.168.11.199/g' redis.conf

.修改端口号7001-:# sed -i 's/port 6379/port 7001/g' redis-/redis.conf


6.开启后台启动模式:
# sed -i 's/daemonize no/daemonize yes/g' redis.conf

7.复制redis配置文件重命名为redis-2...6.conf,修改端口号7002-7006
8..安装ruby环境:
# yum -y install ruby
# yum -y install rubygems
9.安装执行ruby脚本redis-trib.rb执行所依赖的gem包:
# wget https://rubygems.global.ssl.fastly.net/gems/redis-3.2.1.gem
# gem install -l ./redis-3.2..gem
10.编写脚本启动所有实例
#!/bin/bash
set -e
redis1=/usr/local/redis-cluster/redis-4.0./redis-.conf
redis2=/usr/local/redis-cluster/redis-4.0./redis-.conf
redis3=/usr/local/redis-cluster/redis-4.0./redis-.conf
redis4=/usr/local/redis-cluster/redis-4.0./redis-.conf
redis5=/usr/local/redis-cluster/redis-4.0./redis-.conf
redis6=/usr/local/redis-cluster/redis-4.0./redis-.conf echo "start redis-1..."
{
/usr/local/bin/redis-server $redis1 >/dev/null >&
} || {
echo "start error"
exit
} echo "start redis-2..."
{
/usr/local/bin/redis-server $redis2 >/dev/null >&
} || {
echo "start error"
exit
} echo "start redis-3..."
{
/usr/local/bin/redis-server $redis3 >/dev/null >&
} || {
echo "start error"
exit
} echo "start redis-4..."
{
/usr/local/bin/redis-server $redis4 >/dev/null >&
} || {
echo "start error"
exit
} echo "start redis-5..."
{
/usr/local/bin/redis-server $redis5 >/dev/null >&
} || {
echo "start error"
exit
} echo "start redis-6..."
{
/usr/local/bin/redis-server $redis6 >/dev/null >&
} || {
echo "start error"
exit
}
10.启动

11.复制集群脚本命令
# cp src/redis-trib.rb .

12.开启每个配置文件的集群功能
# sed -i 's/# cluster-enabled yes/cluster-enabled yes/g' redis-.conf

13.创建集群
# cd src
# ./redis-trib.rb create --replicas 192.168.11.199: 192.168.11.199: 192.168.11.199: 192.168.11.199: 192.168.11.199: 192.168.11.199:
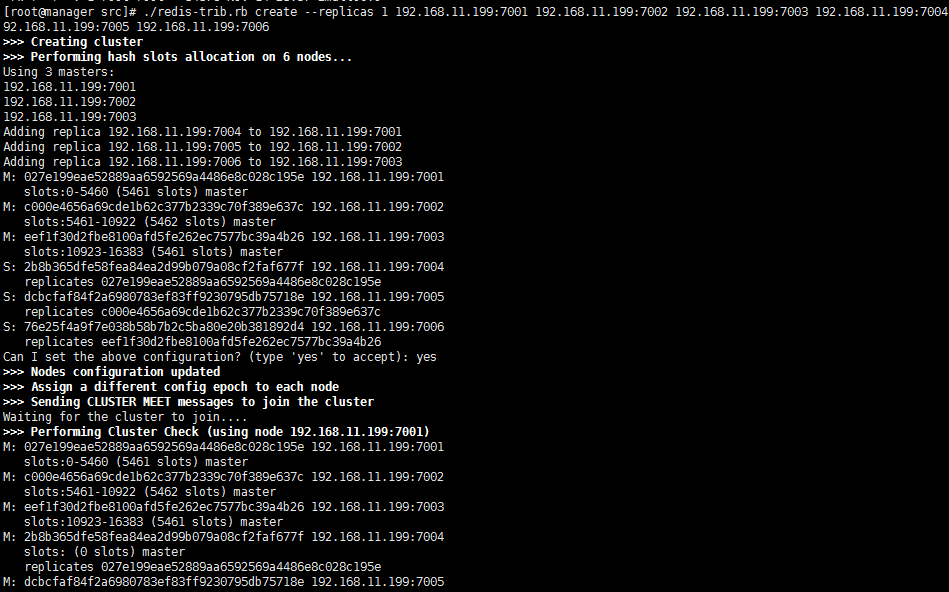
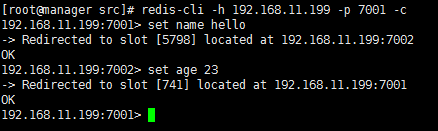
14.连接集群,自动切换集群节点
# redis-cli -h 192.168.11.199 -p -c
15.检查集群状态
# ./redis-trib.rb check 192.168.11.199:

redis单节点集群的更多相关文章
- Ambari安装之部署单节点集群
前期博客 大数据领域两大最主流集群管理工具Ambari和Cloudera Manger Ambari架构原理 Ambari安装之Ambari安装前准备(CentOS6.5)(一) Ambari安装之部 ...
- kubernetes系列:(一)、kubeadm搭建kubernetes(v1.13.1)单节点集群
kubeadm是Kubernetes官方提供的用于快速部署Kubernetes集群的工具,本篇文章使用kubeadm搭建一个单master节点的k8s集群. 节点部署信息 节点主机名 节点IP 节点角 ...
- Hadoop学习笔记(两)设置单节点集群
本文描写叙述怎样设置一个单一节点的 Hadoop 安装.以便您能够高速运行简单的操作,使用 Hadoop MapReduce 和 Hadoop 分布式文件系统 (HDFS). 參考官方文档:Hadoo ...
- ELK日志框架(1):安装Elasticsearch组建单服务器多节点集群
ELK简介 最近有个需求搭建一套日志系统用于集成几个业务系统的日志提供快速的检索功能,目前是用Log4net存数据库+Error级别发邮件方式,也算简单暴力好用,但历史日志的模糊查询确实很慢,所以使用 ...
- redis 安装和单机多节点集群
环境: centOs系统 一.安装redis: 1.下载安装(先装c编译器yum -y install gcc) $ wget http://download.redis.io/releases/re ...
- redis单机多节点集群
# ##安装Redis redis安装参考 https://www.cnblogs.com/renxixao/p/11442770.html Reids安装包里有个集群工具,要复制到/usr/loca ...
- kubeadm安装K8S单master双节点集群
宿主机:master:172.16.40.97node1:172.16.40.98node2:172.16.40.99 # 一.k8s初始化环境:(三台宿主机) 关闭防火墙和selinux syste ...
- CentOS7搭建hadoop2.6.4双节点集群
环境: CentOS7+SunJDK1.8@VMware12. NameNode虚拟机节点主机名:master,IP规划:192.168.23.101,职责:Name node,Secondary n ...
- Hyperledger Fabric 1.0 从零开始(七)——启动Fabric多节点集群
5:启动Fabric多节点集群 5.1.启动orderer节点服务 上述操作完成后,此时各节点的compose配置文件及证书验证目录都已经准备完成,可以开始尝试启动多机Fabric集群. 首先启动or ...
随机推荐
- WeinView 与 MITSUBISHI FX 系列 PLC 通讯范例
1. 范例操作概述 此范例将介绍如何快捷简易地建立WEINVIEW HMI与MITSUBISHI FX系列 PLC通讯. 注意事项:通讯参数设置,通讯线接法. 2. 规划说明 (1) 新建简单 PLC ...
- windows7x64系统中配置mysql5.7.17为本地开发环境(win2008类似)
1. 下载mysql压缩包mysql-5.7.17-winx64.ziphttps://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.17-winx64.z ...
- 软工读书笔记 week3 (《黑客与画家》上)
一.何谓黑客? 黑客,在我们大多数普通人眼里,就是入侵计算机的人,通常还与干坏事挂钩.而书中告诉我们,这 并不是它的真正含义.而要想理解这本书,就要首先理解什么是黑客. 黑客这个词最初起源时,完全是一 ...
- Centos 7配置docker-阿里云镜像加速
阿里云加速网址:https://cr.console.aliyun.com/cn-hangzhou/mirrors(自行注册账密码) sudo mkdir -p /etc/docker sudo vi ...
- JFinal启动报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/eclipse/jetty/server/Connector
- 错误: Exception in thread "main" java.lang.NoClassDefFoundError: org/eclipse/jetty/server/ ...
- Java学习---Quartz定时任务快速入门
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用.Quartz可以用来创建简单或为运行十个,百个, ...
- mongodb的安装和启动
1.在mongodb的官网上下载安装包 https://www.mongodb.com/download-center 选择对应你的系统的安装包下载 如果下载不了 可以使用这个链接下载http://d ...
- GPL & Apache License
Copyleft[编辑] GPL不会授予许可证接受人无限的权利.再发行权的授予需要许可证接受人开放软件的源代码,及所有修改.且复制件.修改版本,都必须以GPL为许可证. 这些要求就是copyleft, ...
- 【解决方案】[XCUITest] WDA is not listening at 'http://localhost:8100/'
1. 使用Xcode 编译 WebDriver 发现端口为:serverurlhere->http://手机ip:0 <-serverurlhere 2. 解决方案: xcodebuild ...
- stderr: xcode-select: error: tool 'xcodebuild' requires Xcode, but active developer directory '/Library/Developer/CommandLineTools' is a command line tools instance
错误提示: (1). stderr: xcode-select: error: tool 'xcodebuild' requires Xcode, but active developer direc ...