Kafka(1)-概述
一. 内部原理
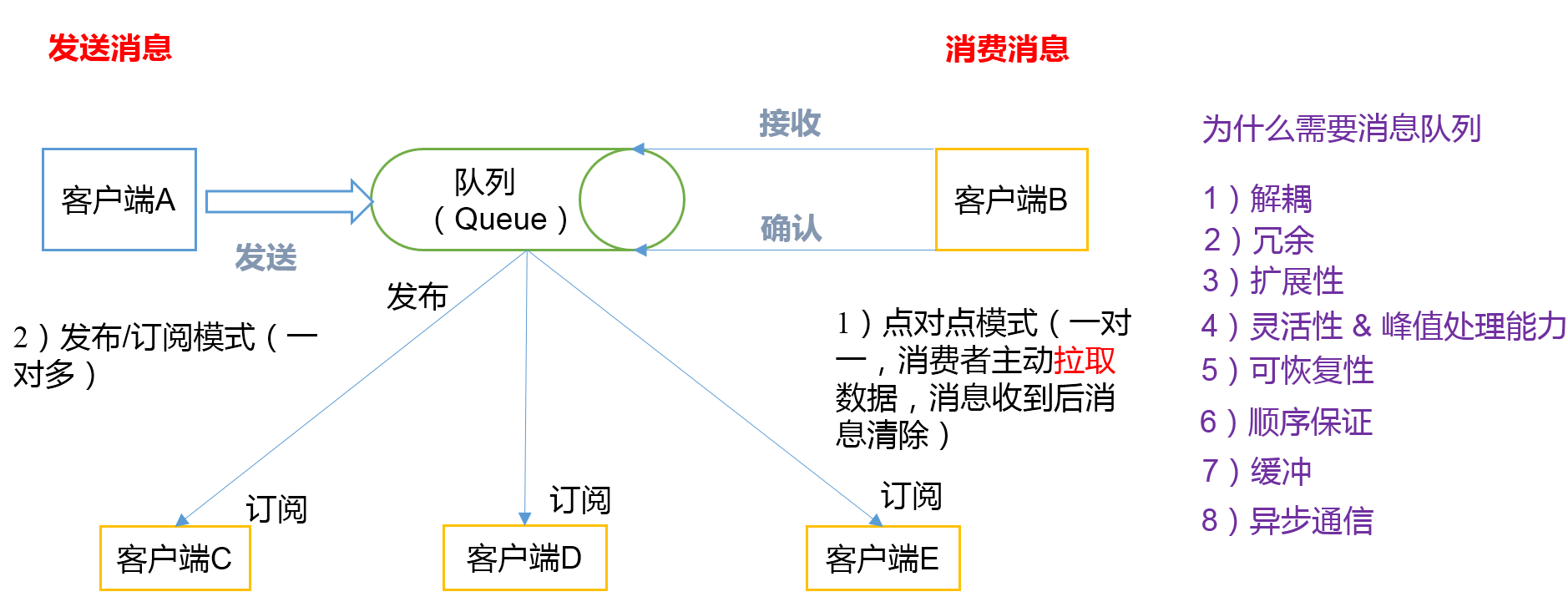
1. 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
2. 发布/订阅模式(一对多)
发布订阅模型则是另一个消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
二. 为什么需要消息队列
1. 解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2. 冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3. 扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4. 灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5. 可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6. 顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
7. 缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8. 异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
三. Kafka架构
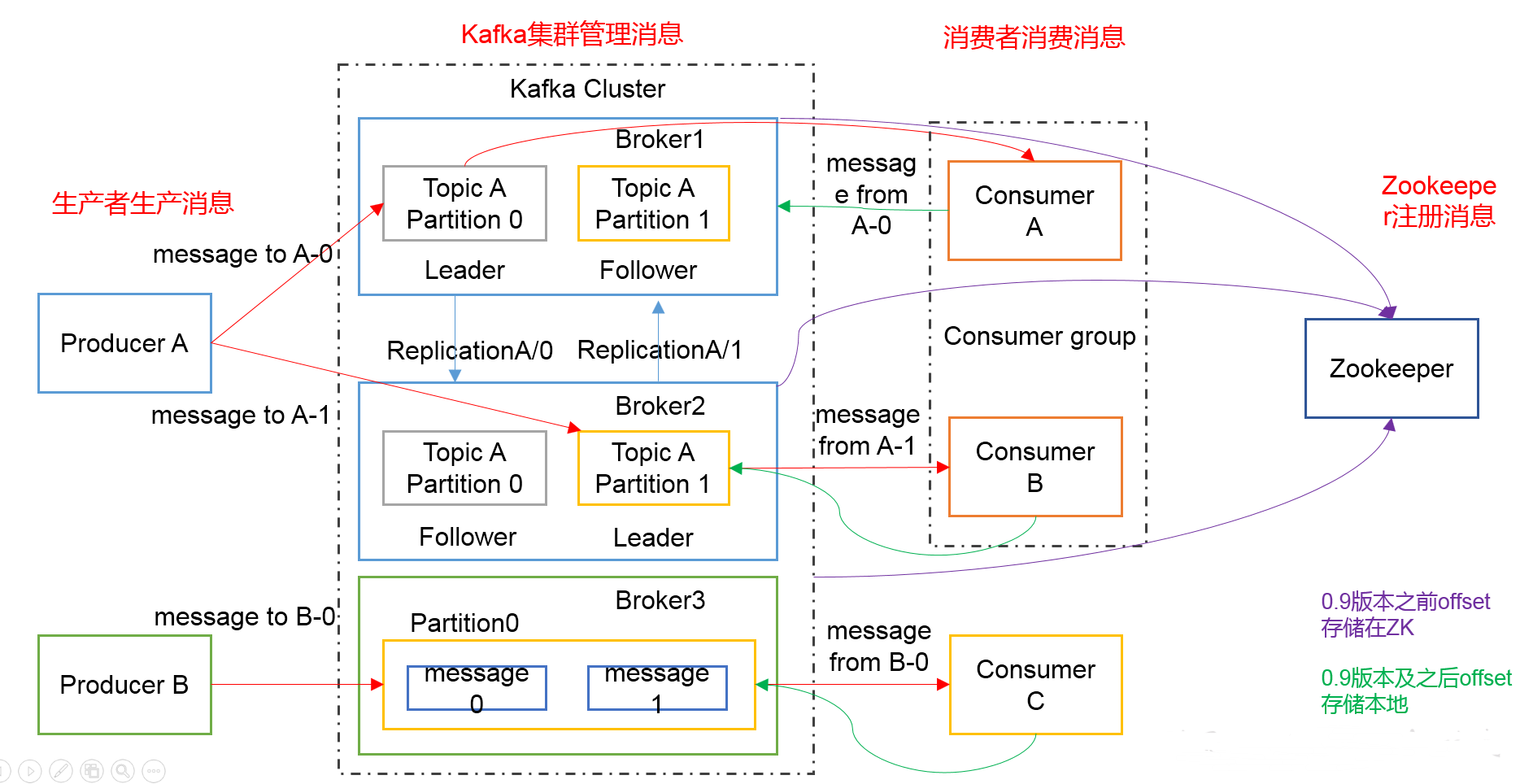
1. Producer :消息生产者,就是向kafka broker发消息的客户端;
2. Consumer :消息消费者,向kafka broker取消息的客户端;
其中的offset需要存在其他位置,低版本0.9之前将offset保存在Zookeeper中,0.9及之后保存在Kafka的“__consumer_offsets”主题中。
3. Topic :可以理解为一个队列或一个消息分类;
4. Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。
一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。
如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
5. Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
6. Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
Kafka(1)-概述的更多相关文章
- Kafka之概述
Kafka之概述 一.消息队列内部实现原理 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消 ...
- kafka模块概述
简介 kafka主要用于实现低延迟的发送和收集大量的事件和日志数据--通常是活跃的数据(PV.访问记录等),数据以日志形式记录下来,然后由一个专门的系统来进行日志的收集与统计: 吞吐量极高的分布式消息 ...
- kafka基本原理概述——patition与replication分配
kafka一直在大数据中承受着数据的压力也扮演着对数据维护转换的角色,下面重点介绍kafka大致组成及其partition副本的分配原则: 文章参考:http://www.linkedkeeper.c ...
- Kafka基本原理概述
Kafka的基本介绍 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ngi ...
- 【Kafka】Kafka-副本-分区设置-性能调优
Kafka-副本-分区设置-性能调优 SparkKafkaDemo - Executors kafka replication 负载均衡_百度搜索 Kafka 高性能吞吐揭秘 - 友盟博客 - Seg ...
- Kafka(五)Kafka的API操作和拦截器
一 kafka的API操作 1.1 环境准备 1)在eclipse中创建一个java工程 2)在工程的根目录创建一个lib文件夹 3)解压kafka安装包,将安装包libs目录下的jar包拷贝到工程的 ...
- Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka 1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来 ...
- 带你涨姿势的认识一下 Kafka
Kafka 基本概述 什么是 Kafka Kafka 是一个分布式流式平台,它有三个关键能力 订阅发布记录流,它类似于企业中的消息队列 或 企业消息传递系统 以容错的方式存储记录流 实时记录流 Kaf ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
随机推荐
- DockerFile简介以及使用
DockerFile是用来构建docker镜像的构建文件,是有一系列命令和参数构成的脚本 构建的三步骤:编写dockerfile文件→build构建→docker run dockerfile保留字指 ...
- 四、python小功能记录——按键转点击事件
import win32api,win32gui,win32confrom pynput.keyboard import Listener def clickLeftCur(): win32api.m ...
- 在 Windows Server Container 中运行 Azure Storage Emulator(二):使用自定义的 SQL Server Instance
上一节,我们解决了 Azure Storage Emulator 自定义监听地址的问题,这远远不够,因为在我们 DEV/QA 环境有各自的 SQL Server Instance,我们需要将 ASE ...
- Shell脚本例子集合
# vi xx.sh 退出并保存 # chmod +x xx.sh # ./xx.sh -2. 调试脚本的方法 # bash -x xx.sh 就可以调试了 . -1. 配置 secureCRT 的设 ...
- 3 Dockerfile指令详解-FROM&MAINTAINER&RUN
1.FROM指令 FROM centos #指定centos为基础镜像 2.MAINTAINER 指令 MAINTAINER @QQ.COM #指定维护人等信息,方便维护 3.RUN 命令 #新建 ...
- LNMP-day1-安装并配置
Nginx安装 #Nginx [root@localhost downloads]# pwd /root/downloads #安装依赖pcre [root@localhost downloads]# ...
- PHP面试常用算法(推荐)
一.冒泡排序 基本思想: 对需要排序的数组从后往前(逆序)进行多遍的扫描,当发现相邻的两个数值的次序与排序要求的规则不一致时,就将这两个数值进行交换.这样比较小(大)的数值就将逐渐从后面向前面移动. ...
- Angular实现多标签页效果(路由重用)
1.需求 做了几年的MES系统,从ASP.NET WebForm至MVC,系统决定了用户界面必须为标签页方式实现,因为用户在进行一项操作的时候很有可能会进行其它的操作,比如查询之类的.如果按MVC的方 ...
- yarn-site.xml
要保证spark on yarn的稳定性,避免报错,就必须保证正确的配置,尤其是yarn-site.xml. 首先来理解一下yarn-site.xml各个参数的意义(引自董的博客) 注:下面<v ...
- struts2(2.0.x到2.1.2版本)的核心和工作原理(转)
在学习struts2之前,首先我们要明白使用struts2的目的是什么?它能给我们带来什么样的好处? 设计目标 Struts设计的第一目标就是使MVC模式应用于web程序设计.在这儿MVC模式的好处就 ...