Titanic幸存预测分析(Kaggle)
分享一篇kaggle入门级案例,泰坦尼克号幸存遇难分析。
参考文章: 技术世界,原文链接 http://www.jasongj.com/ml/classification/
案例分析内容:
通过训练集分析预测什么人可能生还,并对测试集中乘客做出预测判断
案例分析
加载包
library(dplyr) #bind_rows()
library(ggplot2) #绘图
library(ggthemes)
library(InformationValue) #计算WOE和IV
library(stringr) #数据处理
library(rpart) #预测乘客年龄
library(scales) #dollar_format()
library(party) #cforest()
library(gbm) #AdaBoost
library(MLmetrics) # Mache learning metrics.e.g. Recall, Precision, Accuracy, AUC
加载文件
train <- read.csv("F:\\R/泰坦尼克幸存分析/train.csv",header = T,stringsAsFactors = F) #ID 1~891乘客信息
test <- read.csv("F:\\R/泰坦尼克幸存分析/test.csv",header = T,stringsAsFactors = F) #ID 892~1309号乘客信息(缺少是否存活信息)
test_survived <-read.csv("F:/R/泰坦尼克幸存分析/gender_submission.csv",header = T,stringsAsFactors = F) #ID 892~1309号 是否存活信息数据整理
#合并训练数据和测试数据
data <- bind_rows(train,test)
##Sex:性别,Age:年龄,SibSP:配偶/兄妹数,Parch:父母/子女数,Ticket:船票号
##Fare:费用,Cabin:舱位区域,Pclass:舱位等级,Embarked:到达码头,Title:头衔
#将是否存活设为因子
data$Survived <- as.factor(data$Survived)
train$Survived <-as.factor(train$Survived)
test$Survived <- as.factor(test$Survived)统计幸存和遇难人数是否与舱位等级有关
ggplot(data = data[1:nrow(train),],aes(Pclass,..count..,fill=factor(Survived)))+ #载入训练数据分析
geom_bar(stat = 'count',position = 'dodge')+
labs(title='舱位等级对乘客存活影响',x='舱位等级',y='存活人数',fill='Survived')+ #fill为图例标题属性
scale_fill_discrete(limits=c(0,1),labels=c('遇难','获救'))+ #修改图例标签文本
scale_x_continuous(breaks=c(1,2,3),labels=c('头等舱','二等舱','三等舱'))+ #修改X轴刻度文本
geom_text(stat = "count",aes(label=..count..),position = position_dodge(width = 1),vjust=-0.3)+ #添加数据标签
theme(plot.title = element_text(hjust = 0.5)) #修改标题位置
可以看到,头等舱的乘客获救率是最高的,舱位等级越高,获救几率越大

计算舱位等级(Pclass)的WOE和IV
class(data$Pclass) #查看变量(舱位)类型,求WOE时需要转换为因子
WOETable(X = factor(data$Pclass[1:nrow(train)]),Y = data$Survived[1:nrow(train)])
IV(X = factor(data$Pclass[1:nrow(train)]),Y = data$Survived[1:nrow(train)] )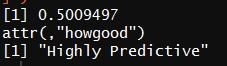
为了更为定量的计算Pclass的预测价值,可以算出Pclass的WOE和IV如下。从结果可以看出,Pclass的IV为0.5,且“Highly Predictive”。由此可以暂时将Pclass作为 预测模型的特征变量之一。
统计不同title(头衔)的乘客存活率
- 训练集中给出了乘客姓名,其中含有MR,Capt等常见称号,这通常标志着一个人处于的社会阶层,所以猜测可能与存活率存在一定联系。接下来要进行分类整理。提取出Name中的title标签,并进行分类。
data$Title <- sapply(data$Name,FUN=function(x){strsplit(x,split = '[,.]')[[1]][2]}) #依次提取出每行的title标签
#head(strsplit(data$Name,split = '[,.]')[[1]][2])
head(data$Title)
data$Title <- sub(pattern = ' ',replacement = '',data$Title)
data$Title[data$Title %in%c('Mme','Mlle')] <-'Mlle'
data$Title[data$Title %in%c('Capt','Don','Major','Sir')] <-'Sir'
data$Title[data$Title%in%c('Dona','Lady','thhe Countess','Jonkheer')] <-'Lady'
data$Title <- factor(data$Title)抽取完乘客Title后,绘图观察
ggplot(data = data[1:nrow(train),],aes(x = Title,y = ..count..,fill=factor(Survived)))+
geom_bar(stat = 'count')+
geom_text(stat = 'count' ,aes(label=..count..),position = position_stack(vjust = 0.85))+
labs(title='头衔是否影响存活率',x='尊称/头衔',y='人数',fill='Survived')+
theme(plot.title = element_text(hjust =0.55))+
scale_fill_discrete(limit=c(0,1),labels=c("遇难","获救"))+
theme_economist()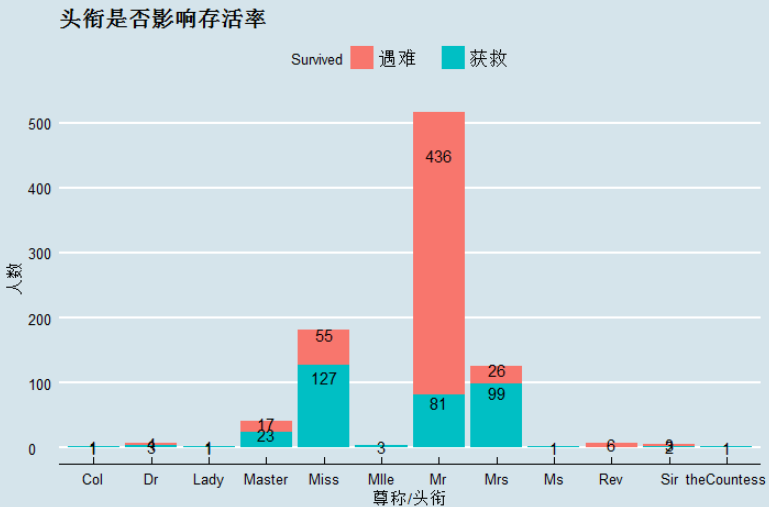
观察图中不难发现,图中Master,Miss,Mlle,Mrs,Ms获救比例均超过50%,而Mr的获救比例不到15.7%。接下来计算WOE和IV,
查看Title这一变量对于最终的预测是否有用
计算头衔(Title)的WOE和IV
WOETable(X = factor(data$Title[1:nrow(train)]),Y = factor(data$Survived[1:nrow(train)]))
2 IV(X = factor(data$Title[1:nrow(train)]),Y = factor(data$Survived[1:nrow(train)]) )
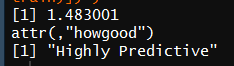
IV为1.520702,且”Highly Predictive”。因此,可暂将Title作为预测模型中的一个特征变量。
猜测性别和存活率有关
ggplot(data = data[1:nrow(train),],aes(x =Sex,y = ..count..,fill=factor(Survived)))+
geom_bar(stat='count',position = 'fill')+
geom_text(stat = 'count',aes(label=..count..),position = 'fill',vjust=1)+
labs(title="性别是否影响存活率",fill="Survived",x='性别',y='获救比例')+
scale_x_discrete(breaks = c('female','male'),labels = c('女','男'))+
scale_fill_discrete(limits=c(0,1),labels=c('遇难','获救'))
泰坦尼克号遇难之际,船上乘客秉承‘女士优先’的原则,实际情况是,75%的女性乘客获救,而仅有不到25%的男性乘客获救,这也充分说明了这 一原则的真实性。

计算性别(Sex)的WOE和IV
WOETable(X = factor(data$Sex[1:nrow(train)]),Y = factor(data$Survived[1:nrow(train)]))

IV(X =factor(data$Sex[1:nrow(train)]),Y = factor(data$Survived[1:nrow(train)]) )
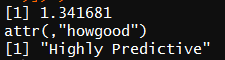
为高预测变量
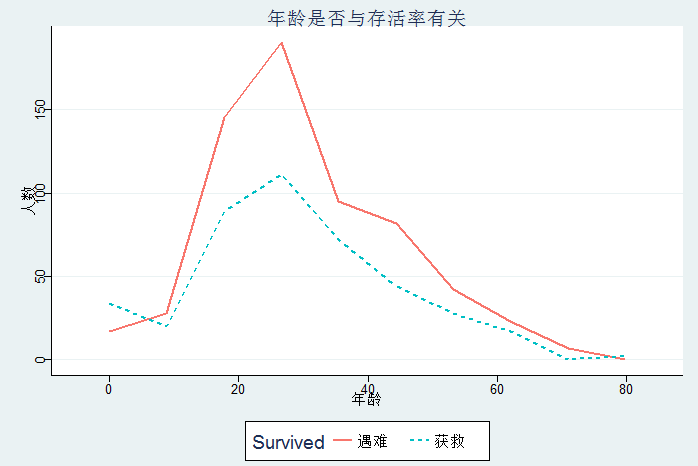
统计年龄与存活率是否有关
summary(data$Age[1:nrow(train)])
ggplot(data = data[!is.na(data$Age),],aes(Age,linetype=Survived,color=Survived))+
geom_line(stat='bin',bins=10,size=0.8)+
labs(title='年龄是否与存活率有关',x='年龄',y='人数',color="Survived",linetype="Survived")+
scale_color_discrete(limits=c(0,1),labels=c('遇难','获救'))+
scale_linetype_discrete(limits=c(0,1),labels=c('遇难','获救'))+
theme_stata()除了女士优先,老弱人士可能也是优先照顾的对象,图中显示,20岁以下的人员获救比例确实较高,而25岁左右的青年人士获救人数最多,但遇难的人数也接近200人。
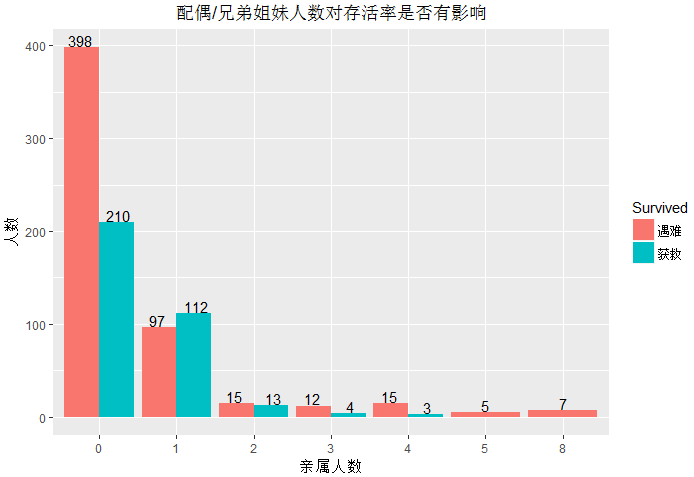
统计(SibSp)配偶/兄弟姐妹人数同时在船对存活率是否有影响
ggplot(data = train,aes(x=as.factor(train$SibSp),fill=Survived))+geom_bar(stat='count',position = 'dodge')+
geom_text(stat = 'count',position = position_dodge(width = 1),aes(label=..count..),vjust=-0.1)+
labs(x='亲属人数',y='人数',title='配偶/兄弟姐妹人数对存活率是否有影响')+
scale_fill_discrete(limits=c(0,1),labels=c('遇难','获救'))+
theme(plot.title = element_text(hjust = 0.5))训练集中提供了乘客配偶或兄弟姐妹的人数,观察后发现没有亲属在船上的人数较多,沉船时,独身出行的乘客获救几率只有34%,有1~2名配偶或兄弟姐妹同时在船上时,该名乘客获救几率也较高。而人数达 4人以上时,几乎同时遇难。
统计SibSp的WOE和IV
WOETable(X = factor(train$SibSp),Y = factor(train$Survived))
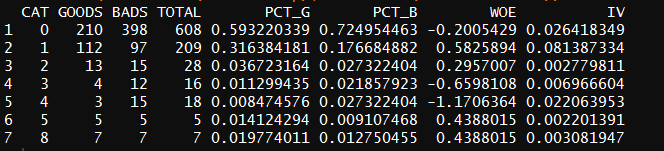
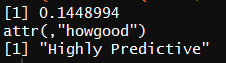
IV(X = factor(train$SibSp),Y = factor(train$Survived))
IV为0.1449,为高预测性变量
统计Parch(父母/子女人数)对存活率影响
ggplot(data = train,aes(Parch,fill=Survived))+
geom_bar(stat='count',position = 'dodge')+
labs(title='父母/子女数对存活率是否有影响',x='父母/子女数',y='人数')+
geom_text(aes(label=..count..),stat = 'count',position = position_dodge(width = 1),vjust=-0.1)+
scale_fill_discrete(limits=c(0,1),label=c('遇难','获救'))+
theme(plot.title = element_text(hjust = 0.5))Parch列中提供的为乘客的父母/子女人数(同时在船),探究是否该变量会影响存活率。由图可看出,当船上没有自己的父母或者子女时,乘客存活率与SibSp情况相仿,不足1/3。当船上Parch数为1~3人时,获救率高于50%。

计算Parch的WOE和IV
WOETable(X = factor(train$Parch),Y = factor(train$Survived))
IV(X = factor(train$Parch),Y = factor(train$Survived))
计算Parch得0.116,认为高预测变量

找出Ticket与存活率关系,共享船票号的可能为一家人,单独船票为独身一人,分成两组进行比较。
ticket.count <- aggregate(data$Ticket,by=list(data$Ticket),function(x)sum(!is.na(x)))
#整合船票号,记录重复的次数,ticket.count记录这两列(有序),但data中船票号分布是无序的
head(ticket.count)
data$TicketCount <- apply(X = data,MARGIN = 1,FUN = function(x)ticket.count[which(ticket.count[,1]==x['Ticket']),2])
#主体(X)为data,将ticket.count中的船票号(有序)与data$Ticket(无序)进行一一对应
head(data$TicketCount)
data$TicketCount <- factor(sapply(X = data$TicketCount,FUN = function(x)ifelse(x>1,'Share','Unique')))
#重复次数>1则说明为共享船票,=1为独自一人.比较两组人员的存活率.数据集中提供了Ticket列,提供了乘客的船票号。整合船票号,发现存在重复的船票号,猜想可以与家庭共享船票号有关。前面得存活率与SibSP和Parch有关,现可将Ticket分成两类,一类为家庭共享船票,一类为独自乘船所用船票号。
1 #重复次数>1则说明为共享船票,=1为独自一人.比较两组人员的存活率.
ggplot(data,aes(TicketCount,..count..,fill=factor(Survived)))+
geom_bar(stat = 'count',position = 'dodge')+
labs(title='船票号与存活率联系',x='船票号',y='人数',fill='Survived')+
geom_text(stat = 'count',aes(label=..count..),position = position_dodge(width = 0.9),vjust=-0.1)+
scale_fill_discrete(limits=c(0,1),labels=c('遇难','获救'))+
theme(plot.title = element_text(hjust = 0.5))
图可看出,共用一张船票的家庭,存活率为50%,而单张船票(即独自出行)的乘客,遇难的可能性高达73%

计算TicketCount的WOE和IV
WOETable(X = factor(data$TicketCount),Y = factor(data$Survived))
## CAT GOODS BADS TOTAL PCT_G PCT_B WOE IV
## 1 share 308 288 596 0.6234818 0.3533742 0.5677919 0.1533649
## 2 unique 186 527 713 0.3765182 0.6466258 -0.5408013 0.1460745> IV(X = factor(data$TicketCount),Y = factor(data$Survived))
## [1] 0.2994394
## attr(,"howgood")
## [1] "Highly Predictive"IV为0.29,且为Highly Predictive
统计船费(Fare)和存活率关系
船费与舱位等级和行程距离有关,已知存活率与舱位等级(Pclass)存在一定关系,猜想船费可能也存在关系
1 summary(data$Fare)
class(data$Fare)
ggplot(data[!is.na(data$Fare),],aes(x = Fare,color=factor(Survived)))+geom_line(stat = 'bin',binwidth=10,size=1)+
labs(title='船费是否影响存活率',x='船费',y='人数',color='Survived')+
scale_color_discrete(labels=c('遇难','获救'))+
theme(plot.title = element_text(hjust=0.5))
由图可看出,船费超过100元的乘客几乎都获救

计算Fare的WOE和IV
WOETable(X = factor(data$Fare),Y = data$Survived)
IV(X = factor(data$Fare),Y = data$Survived)
[1] 0.709573
attr(,"howgood")
[1] "Highly Predictive"
同样Fare为高预测变量
统计舱位区域(Carbin)对存活率影响
对于Cabin变量,其值以字母开始,后面伴以数字。这里有一个猜想,字母代表某个区域,数据代表该区域的序号。类似于火车票即有车箱号又有座位 号。因此,这里可尝试将Cabin的首字母提取出来,并分别统计出不同首字母仓位对应的乘客的幸存率。
1 data$Cabin_level <- substr(x = data$Cabin,start = 1,stop = 1)
ggplot(data,aes(data$Cabin_level,fill=Survived))+geom_bar(stat = 'count',position = 'dodge')+
geom_text(stat = 'count', aes(label=..count..),position = position_dodge(width = 1),vjust=-0.1)+
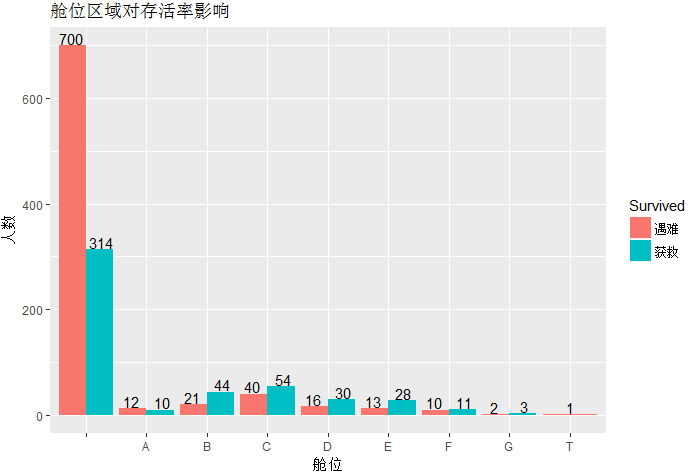
labs(title='舱位区域对存活率影响',x='舱位',y='人数')+
scale_fill_discrete(label=c('遇难','获救'))
Cabin变量中存在的空字符串较多,分析其他得B,C,D,E舱的乘客幸存率远高于50%,其他舱的乘客则低于50%。
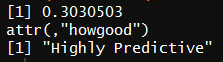
计算data$Cabin_level的WOE和IV
WOETable(X = factor(data$Cabin_level),Y = data$Survived)

IV(X = factor(data$Cabin_level),Y = data$Survived)
统计登船码头是否与存活率有关
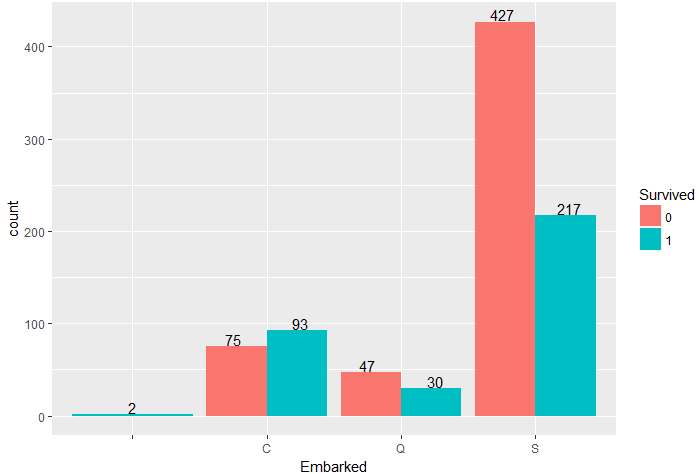
ggplot(train,aes(Embarked,fill=Survived))+geom_bar(stat = 'count',position = 'dodge')+
geom_text(stat = 'count',aes(label=..count..),position = position_dodge(width = 1),vjust=-0.1)
到达C码头的乘客获救率高于50%,而到达S码头的乘客遇难人数达427人,幸存率仅有29%
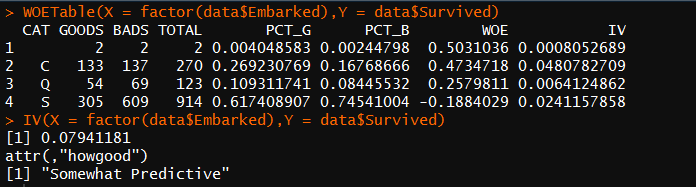
计算Embarked(登船码头)WOE和IV
列出所有缺失数据
研究完变量后,接下来要对缺失数据进行处理
attach(data)
head(missing)
missing<- list(Pclass=nrow(data[is.na(Pclass),]))
missing$Name <- nrow(data[is.na(Name),])
missing$Sex <- nrow(data[is.na(Sex),])
missing$Age <- nrow(data[is.na(Age),])
missing$SibSp <- nrow(data[is.na(SibSp),])
missing$Parch <- nrow(data[is.na(Parch),])
missing$Ticket <- nrow(data[is.na(Ticket),])
missing$Fare <- nrow(data[is.na(Fare),])
missing$Cabin <- nrow(data[which(data$Cabin==''),])
missing$Embarked <- nrow(data[which(data$Embarked==''),])
#names(missing)
#missing[["Cabin"]][1]
for (name in names(missing)) {
if(missing[[name]][1]>0){
print(paste('',name,' miss ',missing[[name]][1],' values',sep=''))
}
}
detach(data)

预测乘客年龄
乘客年龄数据共缺失263条,缺失量较大,不适合使用中位数或均值填补,通过使用其它变量预测或者直接将缺失值设置为默认值的方法填补,这 里通过其它变量来预测缺失的年龄信息。
1 age.model <- rpart(Age~Pclass+factor(Sex)+SibSp+Parch+Fare+factor(Embarked)+Title,data = data[!is.na(data$Age),],method = 'anova')
data$Age[is.na(data$Age)]
data$Age[is.na(data$Age)] <- predict(age.model,data[is.na(data$Age),])
中位数填补缺失的Embarked值
查看缺失码头,发现船费都为80,猜想船费与舱位和到达码头有关。绘图查看后发现到达码头C的头等舱船票为80,可以将该缺失的空值补为C
1 ggplot(data[which(data$Embarked!=''),],aes(Embarked,Fare,fill=factor(Pclass)))+
geom_boxplot()+
geom_hline(yintercept = 80,color='red',linetype=2,lwd=1)+
scale_y_continuous(labels = dollar_format())+
labs(title='船费和舱位及登船码头的关系',x='登船码头',y='船费',fill='舱位等级')+
theme(plot.title = element_text(hjust=0.5),panel.grid.major = element_blank())+
scale_fill_discrete(label=c('头等舱','二等舱','三等舱'))
data$Embarked[which(data$Embarked=='')] <- 'C'
data$Embarked <- as.factor(data$Embarked)

补船费的缺失值
船费和舱位等级,到达码头存在联系,已知另外两个条件,不难猜出船费为多少,将缺失的船费的数据补齐
1 data[is.na(data$Fare),c('Pclass','Embarked')]
summary(data[which(data$Pclass==''&&data$Embarked=='S'),'Fare'])
data[is.na(data$Fare),'Fare'] <-7.25
补Cabin(设为默认值)
因为除去这些缺失值后,测得IV已较高,所以可直接设为一个默认值
1 summary(data$Cabin)
head(data$Cabin)
data$Cabin <- as.factor(sapply(data$Cabin,FUN = function(x) ifelse(x=='','X',str_sub(x,1,1))))
训练模型
set.seed(123)
class(data$Embarked)
data$Sex <- as.factor(data$Sex)
model <- cforest(Survived~Pclass+Title+Sex+Age+SibSp+Parch+TicketCount+Fare+Cabin+Embarked,data,controls = cforest_unbiased(ntree=2000,mtry=3)
交叉验证
cv.summarize <- function(data.true, data.predict) {
print(paste('Recall:', Recall(data.true, data.predict)))
print(paste('Precision:', Precision(data.true, data.predict)))
print(paste('Accuracy:', Accuracy(data.predict, data.true)))
print(paste('AUC:', AUC(data.predict, data.true)))
预测
predict.result <-predict(model,data[(1+nrow(train)):(nrow(data)),],OOB=TRUE,type='response')
output <- data.frame(PassengerID=test$PassengerId,Survived=predict.result)
write.csv(output,file ='F:/R/泰坦尼克幸存分析/cit1.csv',row.names = FALSE)
Titanic幸存预测分析(Kaggle)的更多相关文章
- 编译原理实习(应用预测分析法LL(1)实现语法分析)
#include<iostream> #include<fstream> #include<iomanip> #include<cstdio> #inc ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- 时间序列 预测分析 R语言
在对短期数据的预测分析中,我们经常用到时间序列中的指数平滑做数据预测,然后根据不同. 下面我们来看下具体的过程 x<-data.frame(rq=seq(as.Date('2016-11-15' ...
- 语法设计——基于LL(1)文法的预测分析表法
实验二.语法设计--基于LL(1)文法的预测分析表法 一.实验目的 通过实验教学,加深学生对所学的关于编译的理论知识的理解,增强学生对所学知识的综合应用能力,并通过实践达到对所学的知识进行验证.通过对 ...
- FIRST集合、FOLLOW集合、SELECT集合以及预测分析表地构造
FIRST集合.FOLLOW集合.SELECT集合以及预测分析表地构造 FIRST集合的简单理解就是推导出的字符串的开头终结符的集合. FOLLOW集合简单的理解就对于非终结符后面接的第一个终结符. ...
- 预测分析建模 Python与R语言实现
预测分析建模 Python与R语言实现 目录 前言 第1章 分析与数据科学1第2章 广告与促销10第3章 偏好与选择24第4章 购物篮分析31第5章 经济数据分析42第6章 运营管理56第7章 文本分 ...
- 利用预测分析改进欠款催收策略,控制欺诈风险和信贷风险—— Altair Knowledge Studio 预测分析和机器学习
前提摘要 在数字经济新时代,金融服务主管正在寻求方法去细分他们的产品和市场,保持与客户的联系,寻找能够推动增长和收入的新市场,并利用可以增加优势和降低风险的新技术. 在拥有了众多可用数据之后,金融机构 ...
- 数据可视化之powerBI技巧(六)在PowerBI中简单的操作,实现复杂的预测分析
时间序列预测就是利用过去一段时间内的数据来预测未来一段时间内该数据的走势,比如根据过去5年的销售数据进行来年的收入增长预测,根据上个季度的股票走势推测未来一周的股价变化等等. 对于大部分人来说,这是个 ...
- 如何用Excel进行预测分析?
[面试题] 一个社交APP, 它的新增用户次日留存.7日留存.30日留存分别是52%.25%.14%. 请模拟出来,每天如果日新增6万用户,那么第30天,它的日活数会达到多少?请使用Excel进行 ...
随机推荐
- matlab 黑白格子
有一个生成黑白格子的函数 40 这个参数是改变大小的 img=checkerboard(40)<0.5; figure; imshow(img,[])
- 20、资源与本地化 System.Resources
可以将字符串.图像或对象数据等资源包含在资源文件中,方便应用程序使用. .NET Framework 提供了五种创建资源文件的方法: •创建一个包含字符串资源的文本文件.或创建一个包含字符串.图像或对 ...
- css3 圣诞红包雨效果
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 组合数取模方法总结(Lucas定理介绍)
1.当n,m都很小的时候可以利用杨辉三角直接求. C(n,m)=C(n-1,m)+C(n-1,m-1): 2.n和m较大,但是p为素数的时候 Lucas定理是用来求 c(n,m) mod p,p为素数 ...
- 解决 php7下 igbinary_unserialize_ref: invalid reference 的bug
最近组内升级了PHP7,某个接口偶发502,看了下php的错误日志如下: igbinary_unserialize_ref: invalid reference >= Memcached::ge ...
- virtualbox+vagrant学习-5-Boxes-1-简介
Boxes boxes是vagrant环境的包格式.在vagrant支持的任何平台上,任何人都可以使用一个box来创建一个相同的工作环境.vagrant box实用程序提供了管理boxes的所有功能. ...
- linux内核中网络文件系统的注册初始化
针对内核3.9 系统开启时,会使用init/main.c,然后再里面调用kernel_init(),在里面会再调用do_basic_setup(),调用do_initcalls(),调用do_one_ ...
- POJ 1157 LITTLE SHOP OF FLOWERS (超级经典dp,两种解法)
You want to arrange the window of your flower shop in a most pleasant way. You have F bunches of flo ...
- NodeJS平台下的前后端文件共享
一.前后端文件共享的需要背景——为什么需要共享? 项目基本JS/NodeJS全端开发,有部分代码前后端都需要用得到 有一些配置是在前后端都需要用得到的 区别其他开发平台,NodeJS平台下的前后端文件 ...
- EF Core中如何正确地设置两张表之间的关联关系
数据库 假设现在我们在SQL Server数据库中有下面两张表: Person表,代表的是一个人: CREATE TABLE [dbo].[Person]( ,) NOT NULL, ) NULL, ...