Hadoop源码学习笔记之NameNode启动场景流程三:FSNamesystem初始化源码剖析
上篇内容分析了http server的启动代码,这篇文章继续从initialize()方法中按执行顺序进行分析。内容还是分为三大块:
一、源码调用关系分析
二、伪代码执行流程
三、代码图解
一、源码调用关系分析
上一篇内容是NameNode启动http server的分析,是根据锁定NameNode的main()入口,发现了该入口仅有两行核心代码,先进入到了第一行核心代码
createNameNode()中,发现默认情况是new了一个NameNode对象。在NameNode的构造方法中,有一些很重要的初始化操作,比如启动
http server、加载元数据、初始化rpc server、安全模式检查等。
废话不多说,前面的NameNode.main()、createNameNode()、new NameNode()都不再赘述、直接从initialize()说起:
protected void initialize(Configuration conf) throws IOException {
// 可以通过找到下面变量名的映射,在hdfs-default.xml中找到对应的配置
if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
if (intervals != null) {
conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
intervals);
}
}
......
// 核心代码:启动HttpServer
if (NamenodeRole.NAMENODE == role) {
startHttpServer(conf);
}
this.spanReceiverHost = SpanReceiverHost.getInstance(conf);
// 核心代码:FSNamesystem初始化
loadNamesystem(conf);
// 核心代码:后面rpc server启动流程篇研究
rpcServer = createRpcServer(conf);
......
// 核心代码:启动一些服务组件,包括rpc server等
startCommonServices(conf);
}
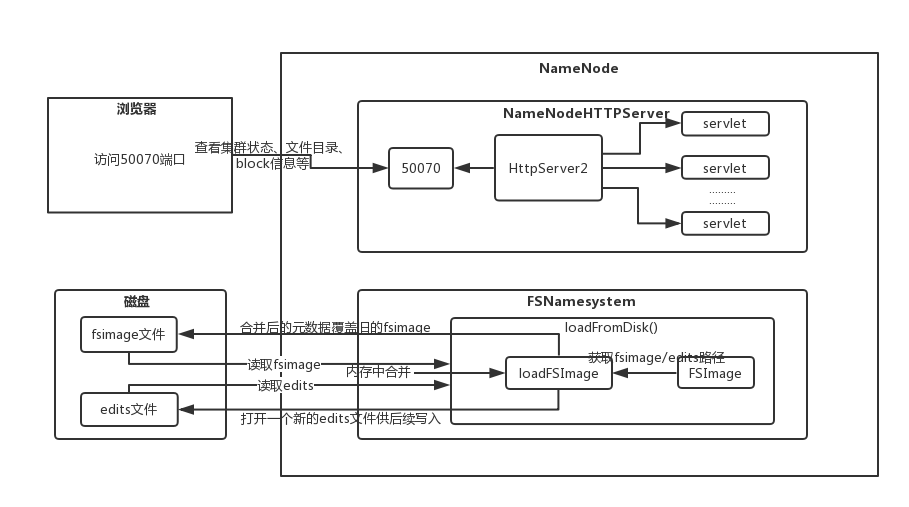
本篇内容主要是关于管理磁盘元数据的FSNamesystem初始化流程,所以从方法名即可推测loadNamesystem()是需要我们重点关注的核心中的核心。
点进去:
protected void loadNamesystem(Configuration conf) throws IOException {
// 核心代码:从磁盘上加载元数据,loadFromDisk()就是从磁盘上读取fsimage和edits文件。
this.namesystem = FSNamesystem.loadFromDisk(conf);
}
我们都知道NameNode的功能之一是,在NameNode启动的时候,会将磁盘上的fsimage和edits两个文件都读取到内存中进行合并,形成一份最新的
元数据。这份最新的元数据放在哪呢?其实是放在了内存中由FSNamesystem进行管理。真的是这样的吗?我们继续往下看,进入到loadFromDisk():
/**
* Instantiates an FSNamesystem loaded from the image and edits
* directories specified in the passed Configuration.
*
* @param conf the Configuration which specifies the storage directories
* from which to load
* @return an FSNamesystem which contains the loaded namespace
* @throws IOException if loading fails
*/
static FSNamesystem loadFromDisk(Configuration conf) throws IOException {
checkConfiguration(conf);
// 核心代码:构造一个FSImage对象,从NamespaceDirs、NamespaceEditsDirs指定的路径加载
FSImage fsImage = new FSImage(conf,
// 默认是从 DFS_NAMENODE_NAME_DIR_KEY 加载fsimage文件
FSNamesystem.getNamespaceDirs(conf),
// 默认是从 DFS_NAMENODE_EDITS_DIR_KEY 加载edits文件
FSNamesystem.getNamespaceEditsDirs(conf));
// 核心代码:根据指定了fsimage和edits文件路径的fsimage对象,实例化FSNamesystem对象
FSNamesystem namesystem = new FSNamesystem(conf, fsImage, false);
StartupOption startOpt = NameNode.getStartupOption(conf);
if (startOpt == StartupOption.RECOVER) {
namesystem.setSafeMode(SafeModeAction.SAFEMODE_ENTER);
}
...try {
// 核心代码:从磁盘上加载数据,在内存中合并数据
// 在NameNode刚启动的时候,会从磁盘读取fsimage和edits文件到内存中,合并为一份最新的
// 元数据,然后将这份新的元数据写出到磁盘替换之前旧的fsimage。然后,还会重新打开一个
// 空的edits文件,以供接下来的元数据变动日志写入。这个loadFSImage()主要就是干了这么一件事情
// 会在namenode元数据管理研究时进行深入详细剖析。
namesystem.loadFSImage(startOpt);
} catch (IOException ioe) {
...
}
...
return namesystem;
}
首先这个loadFromDisk()有一段注释,将这个方法的功能和目的说的也很明白了:根据配置文件指定的路径,实例化一个从image和edits加载元数据
的FSNamesystem对象。下面开始分析核心代码,这段有3行核心代码:
fsimage = new FSImage(conf, NameSpaceDirs, NameSpaceEditsDirs);
这行代码是构造了一个FSImage对象,从NameSpaceDirs, NameSpaceEditsDirs分别
读取fsimage和edits文件。其中NameSpaceDirs和NameSpaceEditsDirs经过溯源分别对应 dfs.namenode.name.dir 和
dfs.namenode.shared.edits.dir,这两个属性都可以在hdfs-default.xml中查看和配置。
FSNamesystem namesystem = new FSNamesystem(conf, fsimage, false);
根据上面指定了fsimage路径和edits路径的fsimage对象,构造一个FSNamesystem对象。
namesystem.loadFSImage();
开始执行loadFSImage()方法,从磁盘上加载数据并在内存中进行合并。
注意,在合并fsimage和edits形成一份新的元数据之后,会将这份新的元数据写出到磁盘替换旧的fsimage文件,然后还会打开一个新的edits
文件,以供接下来的元数据变动的日志写入。这些操作都是在loadFSImage()中完成的,具体的进入到该方法中可以详细了解。
二、伪代码执行流程
NameNode.main() // 入口函数
|——createNameNode(); // 通过new NameNode()进行实例化
|——initialize(); // 方法进行初始化操作
|——startHttpServer(); // 启动HttpServer
|——loadNamesystem(); // 加载元数据
|——loadFromDisk(); // 从磁盘加载数据
|——new FSImage(); // 实例化FSImage对象
|——new FSNamesystem(fsImage); // 根据FSImage对象实例化FSNamesystem
|——loadFSImage(startOpt); // 加载并合并fsimage、edits,然后写出到磁盘
|——join()
三、代码图解
Hadoop源码学习笔记之NameNode启动场景流程三:FSNamesystem初始化源码剖析的更多相关文章
- Hadoop源码学习笔记之NameNode启动场景流程四:rpc server初始化及启动
老规矩,还是分三步走,分别为源码调用分析.伪代码核心梳理.调用关系图解. 一.源码调用分析 根据上篇的梳理,直接从initialize()方法着手.源码如下,部分代码的功能以及说明,已经在注释阐述了. ...
- Hadoop源码学习笔记之NameNode启动场景流程二:http server启动源码剖析
NameNodeHttpServer启动源码剖析,这一部分主要按以下步骤进行: 一.源码调用分析 二.伪代码调用流程梳理 三.http server服务流程图解 第一步,源码调用分析 前一篇文章已经锁 ...
- Hadoop源码学习笔记之NameNode启动场景流程五:磁盘空间检查及安全模式检查
本篇内容关注NameNode启动之前,active状态和standby状态的一些后台服务及准备工作,即源码里的CommonServices.主要包括磁盘空间检查. 可用资源检查.安全模式等.依然分为三 ...
- Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程.想到了这个废弃已久的blog账号,决定重新开始更新. 主要分以下几步来进行源码学习: 一.搭建源码阅读环境二. ...
- JUC源码学习笔记5——线程池,FutureTask,Executor框架源码解析
JUC源码学习笔记5--线程池,FutureTask,Executor框架源码解析 源码基于JDK8 参考了美团技术博客 https://tech.meituan.com/2020/04/02/jav ...
- (三)Netty源码学习笔记之boss线程处理流程
尊重原创,转载注明出处,原文地址:http://www.cnblogs.com/cishengchongyan/p/6160194.html 本文我们将先从NioEventLoop开始来学习服务端的 ...
- Spring源码学习笔记12——总结篇,IOC,Bean的生命周期,三大扩展点
Spring源码学习笔记12--总结篇,IOC,Bean的生命周期,三大扩展点 参考了Spring 官网文档 https://docs.spring.io/spring-framework/docs/ ...
- async-validator 源码学习笔记(六):validate 方法
系列文章: 1.async-validator 源码学习(一):文档翻译 2.async-validator 源码学习笔记(二):目录结构 3.async-validator 源码学习笔记(三):ru ...
- Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构
Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构 之前我们简要的看过了DataNode的main函数以及整个类的大至,现在结合前面我们研究的线程和RPC,则可以进一步 ...
随机推荐
- C#写入文本文档
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- Python实例---FTP小程序
[更多参考] 点击下载
- Apache配置支持目录浏览
主配置文件 httpd.conf 中修改: 1)添加支持模块 LoadModule autoindex_module modules/mod_autoindex.so LoadModule dir ...
- 沉淀再出发:java中的CAS和ABA问题整理
沉淀再出发:java中的CAS和ABA问题整理 一.前言 在多并发程序设计之中,我们不得不面对并发.互斥.竞争.死锁.资源抢占等等问题,归根到底就是读写的问题,有了读写才有了增删改查,才有了所有的一切 ...
- August 13th 2017 Week 33rd Sunday
The best accessory a girl can own is confidence. 女生最好的饰品就是自信. Only when we have our own ideas and on ...
- December 26th 2016 Week 53rd Monday
Better to light one candle than to curse the darkness. 与其诅咒黑暗,不如燃起蜡烛. If the world is so cruel, I wo ...
- iOS测试基础(命令篇)-iPhone型号及其他信息
首先安装libimobiledevice和ideviceinstaller brew uninstall ideviceinstaller brew uninstall libimobiledevic ...
- 通过iframe标签绕过csp
iframe.php代码如下: allow-popups开启时,window.open就可以打开新的窗口. 看csp规则,默认是在当前域内,如果这是一个ctf题的话,就很简单了,window.loca ...
- Linux 问题处理集锦
安装nginx,编译过程中遇到的问题 wget command not found yum -y install wget c compiler cc is not found yum -y inst ...
- [教程] macOS打开原生的NTFS读写功能
Mac本身实际上是支持原生的NTFS读写的,只不过这一功能被隐藏了,但是可以手动打开,这比第三方的的工具要安全得多,有时第三方工具可能会发生整个NTFS分区数据丢失的情况,下面是打开MAC原生NTFS ...