Unicode字符集和UTF-8, UTF-16, UTF-32编码
ASCII
在过去的计算中,ASCII码被用来表示字符。英语只有26个字母和其他一些特殊字符和符号。
下表提供了ASCII字符及其相应的十进制和十六进制值。
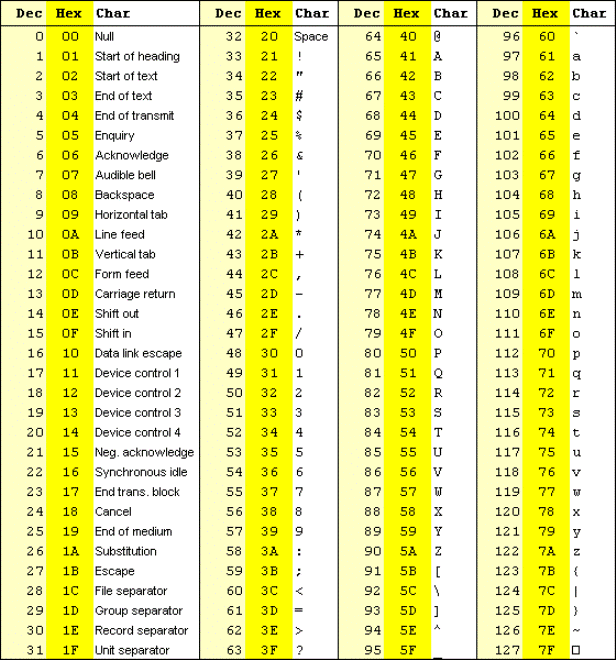
可以从上面的表中推断,在十进制数系统中,ASCII值可以表示为0到127。
让我们看一下0和127的二进制表示形式,在8位字节中。
0表示为
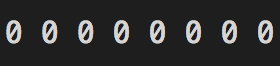
127表示为

可以从上面的二进制表示中推断出,0到127的十进制值可以用7位表示,而不是8位。
这就是事情开始变得混乱的地方。
人们想出了不同的方法来使用剩下的8位,它代表了从128到255的十进制值,并且开始发生碰撞。
例如使用的十进制值182在越南代表越南字母ờ而相同的值182被印第安人代表印地语字母घ。
如果电子邮件写的一个印度包含字母表घ如果是阅读一个人在越南似乎ờ。不打算出现的方法。
这就是Unicode字符集来保存这一天的地方。
Unicode和代码点
Unicode字符集将世界上的每个字符映射到一个唯一的数字。这确保了不同语言的字母表之间没有冲突。这些数字是平台无关的。
这些独特的数字被称为unicode术语中的代码点。
让我们看看它们是如何被引用的。
拉丁字符ṍ被称为使用代码点
U+1E4D
U +表示unicode和1 e4d十六进制值分配给角色ṍ
英文字母A被表示为U+0041。
请访问http://www.unicode.org/charts/了解代码点对所有语言和世界的字母
utf - 8编码
现在我们知道了什么是unicode,以及如何将世界上的每个字母表分配给一个惟一的代码点,我们需要一种方法来表示计算机内存中的这些代码点。这就是角色编码进入画面的地方。一个这样的编码方案是UTF-8。
UTF-8编码是一种可变大小的编码方案,用于表示内存中的unicode代码点。可变大小的编码意味着代码点使用1、2、3或4字节表示,这取决于它们的大小。
utf - 8 1字节编码
一个1字节的编码是通过在第一个比特中出现0来确定的。

英文字母A有unicode码点U+0041。它的二进制表示是1000001。
A用UTF-8编码表示。
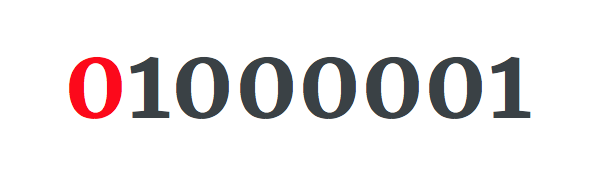
红色0位表示使用1字节编码,其余的位表示代码点。
utf - 8 2字节编码
带有代码点U+00F1的拉丁字母n有二进制值11110001。这个值大于使用1字节编码格式表示的最大值,因此这个字母表将使用UTF-8 2字节编码表示。
2字节编码是由位序列110在第1位和第10位在第2位中出现。

unicode代码点U+00F1的二进制值为1111 0001。将这些位填充到2字节编码格式中,我们得到了如下所示的UTF-8 2字节编码表示。
填充是先从最不重要的代码点开始,然后将其映射到第二个字节中最不重要的部分。

蓝色11110001中的二进制数字表示代码点U+00F1的二进制值,红色的是2字节编码标识符。黑颜色的零被用来填充字节中的空比特。
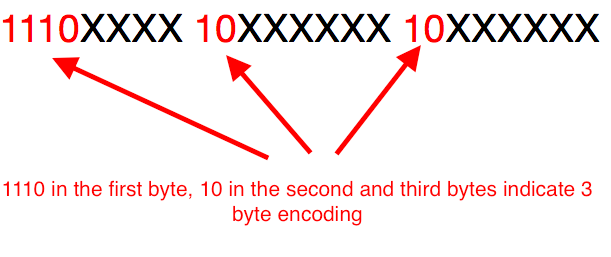
utf - 8 3字节编码
ṍ的拉丁字符的代码点U + 1 e4d表示使用3字节编码是大于最大值,可以使用2字节编码表示。
一个3字节的编码是通过在第一个字节中出现的位序列1110和第二个和第三个字节中的10来标识的。
十六进制代码点0x1E4D的二进制值是1111001001101。填充这些位在上面的编码格式给我们的utf - 8 3字节编码表示ṍ显示如下。
开始填充的时候,最不重要的代码点映射到第三个字节中最不重要的部分。
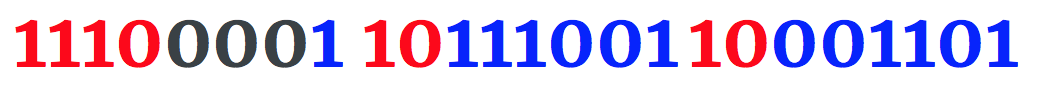
红色位表示3字节编码,黑色表示填充位,蓝色表示代码点。
utf - 8 4字节编码
的Emoji
Unicode字符集和UTF-8, UTF-16, UTF-32编码的更多相关文章
- 转:Unicode字符集和多字节字符集关系
原文地址: http://my.oschina.net/alphajay/blog/5691 unicode.ucs-2.ucs-4.utf-16.utf-32.utf-8 http://stallm ...
- Unicode字符集和多字节字符集关系
在计算机中字符通常并不是保存为图像,每个字符都是使用一个编码来表示的,而每个字符究竟使用哪个编码代表,要取决于使用哪个字符集(charset). 在最初的时候,Internet上只有一种字符集—— ...
- Unicode字符集和编码方式
通常将一个标准中能够表示的所有字符的集合称为字符集,比如ISO/Unicode所定义的字符集为Unicode.在Unicode中,每个字符占据一个码位/Unicode 编号(用4位十六进制数表示,Co ...
- 有关UNICODE、ANSI字符集和相关字符串操作
Q UNICODE字符串如何显示 A 如果程序定义了_UNICODE宏直接用 WCHAR *str=L"unicodestring"; TextOut(0,0,str); 否则就需 ...
- 字符集研究之多字节字符集和unicode字符集
作者:朱金灿 来源:http://blog.csdn.net/clever101 本文简介计算机中两大字符集:多字节字符集和unicode字符集的出现及关系. 首先我们须要明确的是计算机是怎样找到字符 ...
- Unicode 字符和UTF编码的理解
Unicode 编码的由来 我们都知道,计算机的内部全部是由二进制数字0, 1 组成的, 那么计算机就没有办法保存我们的文字, 这怎么行呢? 于是美国人就想了一个办法(计算机是由美国人发明的),也把文 ...
- Unicode字符以16进制表示
int(x [,base ]) 将x转换为一个整数 long(x [,base ]) 将x转换为一个长整数 float(x ) 将x转换到一个 ...
- 转载一篇关于unicode字符编码的文章
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们认为8个开关状态作为原子单位很好,于是他们把这称为"字节". 再后来,他们又做了一 ...
- 字符集和字符编码(Charset & Encoding)
字符集和字符编码(Charset & Encoding)[转] 1.基础知识 计算机中储存的信息都是用二进制数表示的:而我们在屏幕上看到的英文.汉字等字符是二进制数转换之后的结果.通俗的说,按 ...
随机推荐
- 一、cent OS安装配置JDK
到oracle官网下载JDKhttp://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html 在cent OS ...
- Spring Boot学习笔记(二)全局捕获异常处理
非常简单只需要创建自己的异常处理类,加上两个注解,就可以了
- golang 编码转化
在网上搜索golang编码转化时,我们经常看到的文章是使用下面一些第三方库: https://github.com/djimenez/iconv-go https://github.com/qiniu ...
- Elasticsearch数据类型
Elasticsearch自带的数据类型是Lucene索引的依据,也是做手动映射调整的依据.映射中主要就是针对字段设置类型以及类型相关参数.1.JSON基础类型如下:字符串:string数字:byte ...
- 5.Resource注解解析
Resource有两种使用场景 1.Resource 当Resource后面没带参数的时候是根据它所注释的属性名称到applicationContext.xml文件中查找是否有bean的id与之匹配, ...
- 中小型研发团队架构实践三:微服务架构(MSA)
一.MSA 简介 1.1.MSA 是什么 微服务架构 MSA 是 Microservice Architect 的简称,它是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相通讯.互相 ...
- javascript中函数的写法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 51NOD1847:奇怪的数学题
传送门 Sol 设 \(f(d)\) 表示 \(d\) 所有约数中第二大的,\(low_d\) 表示 \(d\) 的最小质因子 \[f(d)=\frac{d}{low_d}\] 那么 \[\sum_{ ...
- background-position为什么会出现负值?
上篇文章讲到了雪碧图,其中小机器人抖腿的动作设置了图片的background-position:-640px 循环到-1200px,那么这个数值是如何得出来的?下面具体分析一下如何计算backgrou ...
- SQL server查找指定表的所有索引
WITH tmp AS ( SELECT indexname = a.name , tablename = c.name , indexcolumns = d.name , a.indid FROM ...