python使用scikit-learn计算TF-IDF
1 Scikit-learn下载安装
1.1 简介
Scikit-learn是一个用于数据挖掘和数据分析的简单且有效的工具,它是基于Python的机器学习模块,基于BSD开源许可证。
Scikit-learn的基本功能主要被分为六个部分:分类(Classification)、回归(Regression)、聚类(Clustering)、数据降维(Dimensionality reduction)、模型选择(Model selection)、数据预处理(Preprocessing)。
Scikit-Learn中的机器学习模型非常丰富,包括SVM,决策树,GBDT,KNN等等,可以根据问题的类型选择合适的模型,具体可以参考官网文档,推荐大家从官网中下载资源、模块、文档进行学习。
1.2 安装软件
pip install scikit-learn- 1
再通过”from sklearn import feature_extraction”导入。
2 TF-IDF基础知识
2.1 TF-IDF概念
TF-IDF(Term Frequency-InversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
- TF(Term Frequency)表示某个关键词在整篇文章中出现的频率。
- IDF(InversDocument Frequency)表示计算倒文本频率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文档频率又称为逆文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。
计算方法:通过将局部分量(词频)与全局分量(逆文档频率)相乘来计算tf-idf,并将所得文档标准化为单位长度。文件中的文档中的非标准权重的公式,如图:
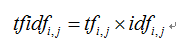
分开的步骤
(1)计算词频
词频 = 某个词在文章中出现的总次数/文章的总词数
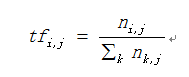
(2)计算逆文档频率
逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1)
2.2 举例说明计算
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行”词频”(Term Frequency,缩写为TF)统计。
(注意:出现次数最多的词是—-“的”、”是”、”在”—-这一类最常用的词。它们叫做”停用词”(stop words),表示对找到结果毫无帮助、必须过滤掉的词。)
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现”中国”、”蜜蜂”、”养殖”这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为”中国”是很常见的词,相对而言,”蜜蜂”和”养殖”不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,”蜜蜂”和”养殖”的重要程度要大于”中国”,也就是说,在关键词排序上面,”蜜蜂”和”养殖”应该排在”中国”的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个”重要性”权重。最常见的词(”的”、”是”、”在”)给予最小的权重,较常见的词(”中国”)给予较小的权重,较少见的词(”蜜蜂”、”养殖”)给予较大的权重。这个权重叫做”逆文档频率”(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
- 第一步,计算词频。

- 第二步,计算逆文档频率
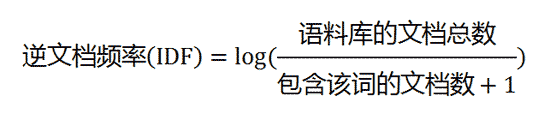
- 第三步,计算TF-IDF。
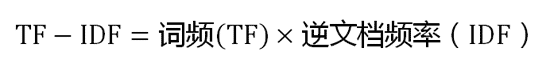
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,”中国”、”蜜蜂”、”养殖”各出现20次,则这三个词的”词频”(TF)都为0.02。然后,搜索Google发现,包含”的”字的网页共有250亿张,假定这就是中文网页总数。包含”中国”的网页共有62.3亿张,包含”蜜蜂”的网页为0.484亿张,包含”养殖”的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
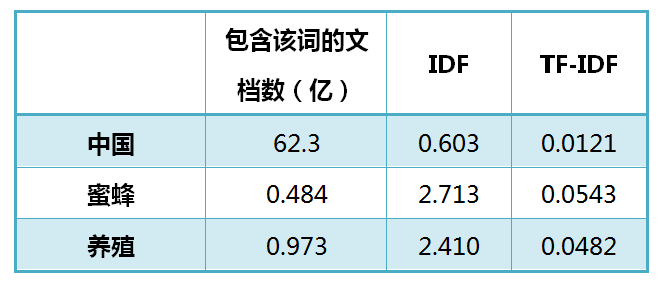
从上表可见,”蜜蜂”的TF-IDF值最高,”养殖”其次,”中国”最低。(如果还计算”的”字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,”蜜蜂”就是这篇文章的关键词。
3 Scikit-Learn中计算TF-IDF
Scikit-Learn中TF-IDF权重计算方法主要用到两个类:CountVectorizer和TfidfTransformer。
3.1 CountVectorizer
CountVectorizer类会将文本中的词语转换为词频矩阵。
例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频。
它通过fit_transform函数计算各个词语出现的次数,
通过get_feature_names()可获取词袋中所有文本的关键字,
通过toarray()可看到词频矩阵的结果。
# coding:utf-8
from sklearn.feature_extraction.text import CountVectorizer #语料
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X = vectorizer.fit_transform(corpus)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
print word
#查看词频结果
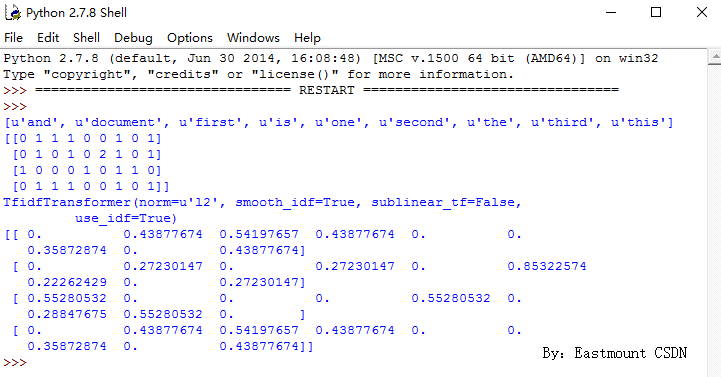
print X.toarray()[u'and', u'document', u'first', u'is', u'one', u'second', u'the', u'third', u'this']
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]从结果中可以看到,总共包括9个特征词,即:
[u’and’, u’document’, u’first’, u’is’, u’one’, u’second’, u’the’, u’third’, u’this’]
同时在输出每个句子中包含特征词的个数。
例如,第一句“This is the first document.”,它对应的词频为[0, 1, 1, 1, 0, 0, 1, 0, 1],
假设初始序号从1开始计数,则该词频表示存在第2个位置的单词“document”共1次、第3个位置的单词“first”共1次、第4个位置的单词“is”共1次、第9个位置的单词“this”共1词。
所以,每个句子都会得到一个词频向量。
3.2 TfidfTransformer
TfidfTransformer用于统计vectorizer中每个词语的TF-IDF值。具体用法如下
# coding:utf-8
from sklearn.feature_extraction.text import CountVectorizer #语料
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X = vectorizer.fit_transform(corpus)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
print word
#查看词频结果
print X.toarray() # ---------------------------------------------------- from sklearn.feature_extraction.text import TfidfTransformer #类调用
transformer = TfidfTransformer()
print transformer
#将词频矩阵X统计成TF-IDF值
tfidf = transformer.fit_transform(X)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
print tfidf.toarray()输出结果入下所示:
4 一个迷你的完整例子
一般情况下需要同时进行词频统计并计算TF-IDF值,则使用核心代码:
vectorizer=CountVectorizer()
transformer=TfidfTransformer()
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))# coding:utf-8
__author__ = "liuxuejiang"
import jieba
import jieba.posseg as pseg
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer if __name__ == "__main__":
corpus=["我 来到 北京 清华大学",#第一类文本切词后的结果,词之间以空格隔开
"他 来到 了 网易 杭研 大厦",#第二类文本的切词结果
"小明 硕士 毕业 与 中国 科学院",#第三类文本的切词结果
"我 爱 北京 天安门"]#第四类文本的切词结果
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
for i in range(len(weight)):#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
print u"-------这里输出第",i,u"类文本的词语tf-idf权重------"
for j in range(len(word)):
print word[j],weight[i][j]输出如下:
-------这里输出第 0 类文本的词语tf-idf权重------ #该类对应的原文本是:"我来到北京清华大学"
中国 0.0
北京 0.52640543361
大厦 0.0
天安门 0.0
小明 0.0
来到 0.52640543361
杭研 0.0
毕业 0.0
清华大学 0.66767854461
硕士 0.0
科学院 0.0
网易 0.0
-------这里输出第 1 类文本的词语tf-idf权重------ #该类对应的原文本是: "他来到了网易杭研大厦"
中国 0.0
北京 0.0
大厦 0.525472749264
天安门 0.0
小明 0.0
来到 0.414288751166
杭研 0.525472749264
毕业 0.0
清华大学 0.0
硕士 0.0
科学院 0.0
网易 0.525472749264
-------这里输出第 2 类文本的词语tf-idf权重------ #该类对应的原文本是: "小明硕士毕业于中国科学院“
中国 0.4472135955
北京 0.0
大厦 0.0
天安门 0.0
小明 0.4472135955
来到 0.0
杭研 0.0
毕业 0.4472135955
清华大学 0.0
硕士 0.4472135955
科学院 0.4472135955
网易 0.0
-------这里输出第 3 类文本的词语tf-idf权重------ #该类对应的原文本是: "我爱北京天安门"
中国 0.0
北京 0.61913029649
大厦 0.0
天安门 0.78528827571
小明 0.0
来到 0.0
杭研 0.0
毕业 0.0
清华大学 0.0
硕士 0.0
科学 0.0
# coding:utf-8 __author__ = "liuxuejiang"import jieba import jieba.posseg as pseg import os import sys from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer if __name__ == "__main__": corpus=["我 来到 北京 清华大学",#第一类文本切词后的结果,词之间以空格隔开 "他 来到 了 网易 杭研 大厦",#第二类文本的切词结果 "小明 硕士 毕业 与 中国 科学院",#第三类文本的切词结果 "我 爱 北京 天安门"]#第四类文本的切词结果 vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频 transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值 tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵 word=vectorizer.get_feature_names()#获取词袋模型中的所有词语 weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重 for i in range(len(weight)):#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 printu"-------这里输出第",i,u"类文本的词语tf-idf权重------"for j in range(len(word)): print word[j],weight[i][j]
python使用scikit-learn计算TF-IDF的更多相关文章
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
随机推荐
- HDU 4272 LianLianKan (状压DP+DFS)题解
思路: 用状压DP+DFS遍历查找是否可行.假设一个数为x,那么他最远可以消去的点为x+9,因为x+1~x+4都能被他前面的点消去,所以我们将2进制的范围设为2^10,用0表示已经消去,1表示没有消去 ...
- Matlab绘图基础——用print函数批量保存图片到文件(Print figure or save to file)
一.用法解析 1.1. 分辨率-rnumber 1.2. 输出图片的“格式”formats 二.用法示例 2.1. 设置输出图片的“图像纵横比” 2.2. Batch Processing(图片保存 ...
- git入门篇
git是一个分布式版本管理软件,总之是一个软件. github是一个代码托管平台,总之是一个网站. github这个网站使用git这个版本管理软件来托管代码. 相当于本地.公司服务器.Github网站 ...
- Java Redis的Pipeline管道,批量操作,节省大量网络往返时间 & Redis批量读写(hmset&hgetall) 使用Pipeline
一般情况下,大家使用redis去put/get都是先拿到一个jedis实例,然后操作,然后释放连接:这种模式是 请求-响应,请求-响应 这种模式,下一次请求必须得等第一次请求响应回来之后才可以,因为r ...
- 《高级Web应用程序设计》课程学习(20170911)
一.课程内容 本学期课件,点击查看 二.作业相关 上交作业的方法 访问ftp://192.168.42.254:22,登录后找到自己的姓名文件夹,放入作业即可.登录账号为stu1,密码为空 作业列表, ...
- hdu4292网络流dinic
因为数组开小了,导致tle了一整天:( tle的几点原因:http://blog.csdn.net/ameir_yang/article/details/53698478 思路都是对的,把每个人进行拆 ...
- oracle 10g 用dbms_xmlgen将数据表转成xml格式
oracle 10g 用dbms_xmlgen将数据表转成xml格式 oracle 10g 用dbms_xmlgen将数据表转成xml格式 oracle用plsql将sql查询的所有数据导出为xml
- VM虚拟机上在NAT模式下设置静态IP的做法
1.问题:由于业务需要,个人笔记本电脑上用Vmware安装了3台Ubuntu虚拟机,现要求pc机连入局域网后,四台机器(3台ubuntu虚拟机+1台宿主机)能上网,并且,虚拟机要使用某一网段的固定IP ...
- Qt enum使用总结
一.enum 自省 const QMetaObject &mo = [ClassName]::staticMetaObject; int index = mo.indexOfEnumerato ...
- 快速切题 sgu135. Drawing Lines
135. Drawing Lines time limit per test: 0.25 sec. memory limit per test: 4096 KB Little Johnny likes ...