关于 MapReduce
继续摘抄《Hadoop 权威指南》第二章,跳过不少于我复杂的东西,但依然是捉急的效率,开始觉得看不完另外一本全英文的书,大概每天要看5页吧。。。
以上。
MapReduce 是一种可用于数据处理的编程模型。该模型比较简单,但想要写出有用的程序却不太容易。Hadoop 可以运行各种语言版本的 MapReduce 程序。在本章中,我们将看到同一个程序的 Java、 Ruby、 Python 和 C++语言版本。最重要的是,MapReduce 程序本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。MapReduce 的优势在于处理大规模数据集,所以这里先来看一个数据集。
气象数据集
在我们的例子里,要写一个挖掘气象数据的程序。分布在全球各地的很多气象传感器每隔一小时收集大量日志数据,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 来分析。
数据格式
我们使用的数据来自美国国家气候数据中心(National Climatic Data Center,简称 NCDC)。这些数据按行并以 ASCII 格式存储,其中每一行是一条记录。该存储格式支持丰富的气象要素,其中许多要素可以选择性地列入收集范围或其数据所需的存储长度是可变的。为了简单起见,我们重点讨论一些基本要素(比如气温),这些要素始终都有而且长度都是固定的。
因为有成千上万个气象台,所以整个数据集由大量的小文件组成。通常情况下,处理少量的大型文件更容易、更有效,因此,这些数据需要经过预处理,将每年的数据文件拼接成一个单独的文件。
使用Unix工具来分析数据
在这个数据集中,每年全球气温的最高纪录是多少?我们先不使用 Hadoop 来解决这个问题,因为只有提供了性能基准和结果检查工具,才能和 Hadoop 进行有效对比。
传统处理按行存储数据的工具是 awk,书上的程序脚本处理完一个世纪的气象数据并找出最高气温需要42分钟。为了加快处理速度,我们可以并行处理程序来进行数据分析。也就是说,我们可以使用计算机上所有可用的硬件线程来处理,每个线程负责处理不同年份的数据。但是不同年份的数据文件差异很大,一些线程本可以处理更多的数据,而且总的运行时间仍然取决于处理最长文件所需要的时间。
更好地方法是将输入数据分成固定大小的块(chunk),这样可以充分发挥每个进程的数据处理能力。但是,这又会带来新的问题。同一个年份的数据可能被分成多个块,需要一种精巧的办法来合并结果以得到每年的最高气温。最后,受限于单台计算机的处理能力,至少也需要20分钟的时间来处理这个问题。
另外,某些数据集的增长可能会超出单台计算机的处理能力。一旦开始使用多台计算机,整个大环境中的其他因素就会互相影响,最主要的两个因素是协调性和可靠性。哪个进程负责运行整个作业?我们如何处理失败的进程?
因此,虽然并行处理是可行的,不过实际上也很麻烦。使用 Hadoop 这样的框架来解决这些问题很有帮助。
使用Hadoop来分析数据
为了充分利用 Hadoop 提供的并行处理优势,我们需要将查询表示成 MapReduce 作业。完成某种本地端的小规模测试之后,就可以把作业部署到集群上运行。
map 和 reduce
MapReduce 任务过程分为两个处理阶段:map 阶段和 reduce 阶段。每个阶段都以键值对作为输入和输出,其类型由程序员来选择。程序员还需要写两个函数:map 函数和 reduce 函数。
在本例中,map 函数只是一个数据准备阶段,通过这种方式来准备数据,是 reduce 函数能够继续对它进行处理:即找出每年的最高气温。map 函数还是一个比较适合去除已损记录的地方:此处,我们筛掉缺失的、可疑的或错误的气温数据。
map 阶段输入键值对的键是文件中的行偏移量,不过我们这里不需要,所以不用管它。map 函数的功能仅限于提取年份和气温信息,并将它们作为输出。map 函数的输出经由 MapReduce 框架处理后,最终发送到 reduce 函数。这个处理过程基于键来对键值对进行排序和分组。reduce 函数遍历整个列表并从中找出最大的读数,即每一年的全球最高气温记录。整个数据流如图2-1所示:
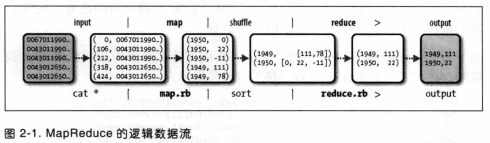
Java MapReduce
明白 MapReduce 的工作原理之后(exm?),下一步就是写代码实现它。我们需要三个东西:map 函数、reduce 函数以及一些用来运行作业的代码。前面两个的实现,代码是看得懂的,后面的作业运行代码就不行了,下面解释后懂了个大概。接着书上开始进行运行测试,需要以独立(本机)模式安装 Hadoop (选择放弃),最后还讨论了下 Java MapReduce 的新旧 API 问题(继续跳过)。想着现在主要只是入门了解,抠这些实现细节意义不大,而且也啃不动,这里只贴出书上部分代码:


横向拓展
前面介绍了 MapReduce 针对少量输入数据是如何工作的,现在我们开始鸟瞰整个系统以及有大量输入时的数据流。为了简单起见,到目前为止,我们的例子都只是用了本地文件系统中的文件。然而,为了实现横向扩展(scaling out),我们需要把数据存储在分布式文件系统中,一般为 HDFS,由此允许 Hadoop 将 MapReduce 计算转移到存储有部分数据的各台机器上。下面我们看看具体过程。
数据流
MapReduce 作业(job)是客户端需要执行的一个工作单元:它包括输入数据、MapReduce 程序和配置信息。Hadoop 将作业分成若干个小任务(task)来执行,其中包括两类任务:map任务和 reduce 任务。
有两类节点控制着作业执行过程:一个 jobtracker 及一系列 tasktracker。jobtracker 通过调度 tasktracker 上运行的任务来协调所有运行在系统上的作业。tasktracker 在运行任务的同时将运行进度报告发送给 jobtracker,jobtracker 由此疾苦每项作业任务的整体进度情况,如果其中一个任务失败,jobtracker 可以在另外一个 tasktracker 节点上重新调度该任务。
Hadoop 将 MapReduce 的输入数据划分成等长的小数据块,称为输入分片(input split)或简称“分片”。Hadoop 为每个分片构建一个 map 任务,并由该任务来运行用户自定义的 map 函数从而处理分片中的每条记录。
拥有许多分片,意味着处理每个分片所需要的时间少于处理整个输入数据所花的时间。因此,如果我们并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好地负载平衡,因为一台比较快的计算机能够处理的数据分片比一台慢的计算机更多,且成一定的比例。即使使用相同的机器,失败的进程或其他同时运行的作业能够实现满意的负载平衡,并且如果分片被切分得更细,负载平衡的会更高。
另一方面,如果分片切分得太小,那么管理分片的总时间和构建 map 任务的总时间将决定作业的整个执行时间。对于大多数作业来说,一个哈利分片大小趋向与 HDFS 的一个块的大小,默认是 64MB,不过可以针对集群调整这个默认值(对新建的所有文件),或对新建的每个文件具体指定。
Hadoop 在存储有输入数据(HDFS 中的数据)的节点上运行 map 任务,可以获得最佳性能。这就是所谓的“数据本地化优化”(data locality optimization),因为它无需使用宝贵的集群带宽资源。但是,有时对于一个 map 任务的输入来说,存储有某个 HDFS 数据块备份的三个节点可能正在运行其他 map 任务,此时作业调度需要在三个备份中的某个数据寻求同个机架中空闲的机器来运行该 map 任务。仅仅在非常偶然的情况下(该情况基本上不会发生),会使用其他机架中的机器运行该 map 任务,这将导致机架与机架之间的网络传输。图2-2显示了这三种可能性。

现在我们应该清楚为什么最佳分片的大小应该与块大小相同:因为它是确保可以存储在单个节点上的最大输入块的大小。如果分片跨越两个数据块,那么对于任何一个 HDFS 节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需要通过网络传输到 map 任务节点。与使用本地数据运行整个 map任务相比,这种方法显然效率更低。
map 任务将其输出写入本地硬盘,而非 HDFS 。这是为什么?因为 map 的输出是中间结果:该中间结果是由 reduce 任务处理后才产生最终输出结果,而且一旦作业完成,map 的输出结果就可以删除。因此,如果把它存储在 HDFS 中并实现备份,难免有些小题大做。如果该节点上运行的 map 任务在将 map 中间结果传送给 reduce 任务之前失败,Hadoop 将在另一个节点上重新运行这个 map 任务以再次构建 map 中间结果。
reduce 任务并不具备数据本地化的优势——单个 reduce 任务的输入通常来自于所有 mapper 的输出。在本例中,我们仅有有个 reduce 任务,其输入时所有 map 任务的输出。因此,排过序的 map 输出需通过网络传输发送到运行 reduce 任务的节点。数据在 reduce 端合并,然后由用户定义的 reduce 函数处理。reduce 的输出通常存储在 HDFS 中以实现可靠存储。因此,将 reduce 的输出写入 HDFS 确实需要占用网络带宽,但这与正常的 HDFS 流水线写入消耗一样。
一个 reduce 任务的完整数据流如图2-3所示。虚线框表示节点,虚线箭头表示节点内部的数据传输,而实现箭头表示不同节点之间的数据传输。
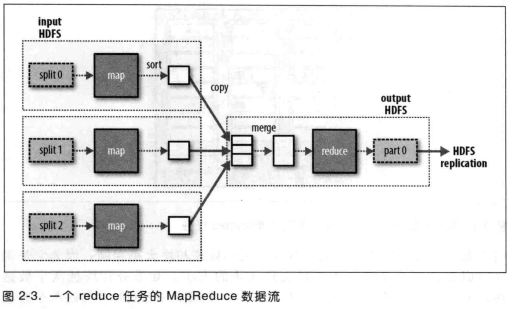
reduce 任务的数量并非由输入数据的大小决定,而是独立指定的。如果有好多个 reduce 任务,每个 map 任务就会针对输出进行分区(partition),即为每个 reduce 任务建一个分区。每个分区有许多键(及其对应的值),但每个键对应的键/值对记录都在同一分区中。分区由用户定义的 partition 函数控制,但通常用默认的 partition 通过哈希函数来区分,很高效。
一般情况下,多个 reduce 任务的数据流如图2-4所示。该图清楚地表明了为什么 map 任务和 reduce 任务之间的数据流成为 shuffle (混洗),因为每个 reduce 任务的输入都来自许多 map 任务。shuffle 一般比图中所示的更加复杂,而且调整混洗参数对作业总执行时间的影响非常大。

最后,当数据处理可以完全并行,即无需混洗时,可能会出现无 reduce 任务的情况。在这种情况下,唯一的非本地节点数据传输是 map 任务将结果写入 HDFS (参见图2-5)。
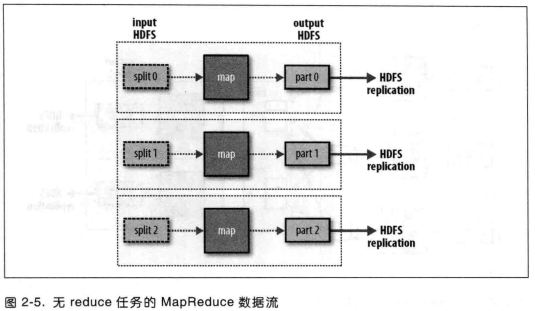
combiner函数
集群上的可用带宽限制了 MapReduce 作业的数量,因此尽量避免 map 和 reduce 任务之间的数据传输是有利的。Hadoop 允许用户针对 map 任务的输出指定一个 combiner(就像 mapper 和 reduce 一样)——combiner 函数的输出作为 reduce 函数的输入。由于 combiner 属于优化方案,所以 Hadoop 无法确定要对 map 任务输出记录调用多少次 combiner(如果需要)。换而言之,不管调用 combiner 多少次,0 次、1 次或多次,reduce 的输出结果都是一样的。
举个例子来说,就以先前计算最高气温的问题为例。1950年的读数由两个 map 任务处理,因为它们在不同的分片中。假设第一个 map 的输出如下:(1950, 0) (1950, 20) (1950, 10) 第二个 map 的输出如下:(1950, 25) (1950,15)reduce 函数被调用时,输入如下:(1950,[0, 20, 10, 23, 15]) 因为25是该列数据中最大的,所以它的输出如下: (1950, 25) 我们可以使用 combiner 找出每个 map 任务输出结果中的最高气温,调用 reduce 时的输入就会变成 (1950, [20, 25]) reduce 输出结果和原来一样,但是传输的数据量减少了。
需要注意的是,并不是所有的问题都可以这样做,并不是所有函数都像 max 这样可以直接用自己作为 combiner,像问题变成计算平均气温就不可以。而且,combiner 不能取代 reduce 函数,我们仍然需要 reduce 函数来处理不同 map 输出中具有相同键的记录。combiner 能有效减少 mapper 和 reducer 之间的数据传输量,在 MapReduce 作业中使用 combiner 函数需要慎重考虑。
运行分布式的MapReduce作业
上面提到的计算最高气温的 Java MapReduce 就可以指定一个 combiner 来加快速度,具体的实现嘛,从简,不会展开。这个程序无需修改便可以在一个完整的数据集上直接运行。这是 MapReduce 的优势:它可以根据数据量的大小和硬件规模进行扩展。
Hadoop Streaming
Hadoop 提供了 MapReduce 的 API,允许你使用非 Java 的其他语言来写自己的 map 和 reduce 函数。 Hadoop Streaming 使用 Unix 标准流作为 Hadoop 和应用程序之间的接口,所以我们可以使用任何编程语言通过标准输入/输出来写 MapReduce 程序。
Streaming 天生适合用于文本处理。 map 的输入数据通过标准输入流传递给 map 函数,并且是一行一行地传输,最后将结果行写到标准输出。map 输出的键/值对是以一个制表符分隔的行,并且写入标准输出 reduce 函数的输入格式与之相同(通过制表符来分隔的键/值对)并通过标准输入流进行传输。reduce 函数从标准输入流中读取输入行,该输入已由 Hadoop 框架根据键排过序,最后将结果写入标准输出。
继续跳过书上使用 Streaming 来重写按年份查找最高气温的 MapReduce 程序,还有 Ruby 和 Python 两个版本。
Hadoop Pipes
Hadoop Pipes 是 Hadoop MapReduce 的 C++ 接口名称。不同于使用标准输入和输出来实现 map 代码和 reduce 代码之间的 Streaming,Hadoop Pipes使用套接字作为 tasktracker 与 C++ 版本 map 函数或 reduce 函数的进程之间的通道,而未使用 JNI(Java Native Interface,JAVA本地调用)。
用 C++ 重写本章的气温示例,然后用 Hadoop Pipes来运行,当然是跳过。
关于 MapReduce的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
随机推荐
- UVM序列篇之一:新手上路
声明:本人所有权属路科验证,本人仅为个人学习方便将文章整理至此. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 有了UVM的世界观,知道这座城市的建 ...
- 大数据sql引擎
Hive:把sql解析后用MapReduce跑 SparkSQL:把sql解析后用Spark跑,比hive快点 Phoenix:一个绕过了MapReduce运行在HBase上的SQL框架 Drill/ ...
- ES6 读书笔记
一.let和const命令 二.变量的解构赋值 三.字符串的扩展 四.数值的扩展 五.正则的扩展 六.数组的扩展 七.函数的扩展 八.对象的扩展 九.symbol 十.proxy和reflect 十一 ...
- pureMVC与strangeIoc框架对比
前言 最近有机会了解到了StrangeIoc框架,就拿来跟自己比较熟悉的pureMVC进行一下简要的对比.这两套开源框架都是基于MVC模式的扩展,pureMVC是一个跨平台跨语言的MVC轻量级应用框架 ...
- ant使用小结
使用builder.xml的方式:完成的工作:打jar包并运行,其中引用了第三方jar和配置文件: <?xml version="1.0" encoding="UT ...
- EntityFramework CodeFirst 学习
个人学习笔记仅供分享,如有错误还请指出 demo结构:models类库和控制台程序 1.首先在model中建立,ADO.NET 实体数据模型---空模型,然后新建数据实体,并且生成数据库 2.控制台想 ...
- Zookeeper配置要点必看
注意点 zookeeper需要在各个节点的机器上搭建,它的启动也要在各个节点的$ZOOKEEPER_HOME/bin 下启动. 环境搭建 下载安装包并解压. 在$ZOOKEEPER_HOME/conf ...
- 从Linux系统安装到Web应用启动教程
概述 本文讲述web应用服务器安装配置教程,其中包括:Linux系统安装,Mysql数据库安装配置,Redis安装配置,Tomcat安装配置,MongoDB安装配置,Linux JDK安装使用,Ngi ...
- Linux之Ubuntu基本命令提炼,分条列出
Ubuntu系统的root用户有时没有安装,我们可以先输入一个root,他会有一个提示命令,然后我们输入该命令,进行安装,安装完后,使用sudopasswd 命令设置密码,设置完后的密码就是root用 ...
- Jenkins2.138配置slave节点时,启动方法只有两个选项
Jenkins2.138配置slave节点时,启动方法只有两个选项,并没有通过javaweb代理启动这个选项 解决办法 全局安全配置->代理->选择随机选取