初识Spark程序
执行第一个spark程序
普通模式提交任务:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hdp-node-01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.0.2.jar \
10
该算法是利用蒙特·卡罗算法求圆周率PI,通过计算机模拟大量的随机数,最终会计算出比较精确的π。

高可用模式提交任务:
在高可用模式下,因为涉及到多个Master,所以对于应用程序的提交就有了一点变化,因为应用程序需要知道当前的Master的IP地址和端口。这种HA方案处理这种情况很简单,只需要在SparkContext指向一个Master列表就可以了,
如spark://host1:port1,host2:port2,host3:port3,应用程序会轮询列表,找到活着的Master。
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hdp-node-01:7077,hdp-node-02:7077,hdp-node-03:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.0.2.jar \
10
启动Spark-Shell
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
运行spark-shell --master local[N] 读取本地文件
单机模式:通过本地N个线程跑任务,只运行一个SparkSubmit进程。
(1)需求
读取本地文件,实现文件内的单词计数。本地文件words.txt 内容如下:
|
hello me hello you hello her |
(2)运行spark-shell --master local[2]
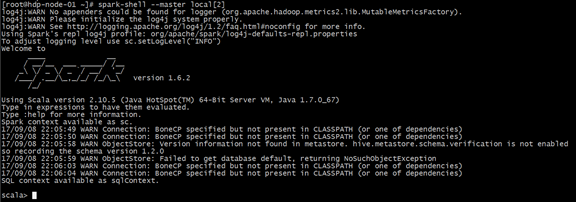
观察启动的进程:

(3)编写scala代码
sc.textFile("file:///root///words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
代码说明:
sc:Spark-Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可。
textFile:读取数据文件
flatMap:对文件中的每一行数据进行压平切分,这里按照空格分隔。
map:对出现的每一个单词记为1(word,1)
reduceByKey:对相同的单词出现的次数进行累加
collect:触发任务执行,收集结果数据。
(4)观察结果:

运行spark-shell --master local[N] 读取HDFS上数据
(1)、整合spark和HDFS,修改配置文件
在spark-env.sh ,添加HADOOP_CONF_DIR配置,指明了hadoop的配置文件后,默认它就是使用的hdfs上的文件
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.4/etc/hadoop

(2)、再启动启动hdfs,然后重启spark集群
(3)、向hdfs上传一个文件到hdfs://hdp-node-01:9000/words.txt
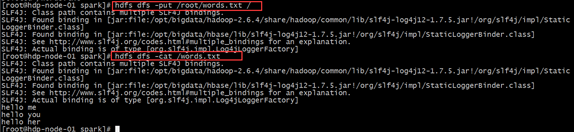
(4)、在spark shell中用scala语言编写spark程序
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
运行spark-shell 指定具体的master地址
(1)需求:
spark-shell运行时指定具体的master地址,读取HDFS上的数据,做单词计数,然后将结果保存在HDFS上。
(2)执行启动命令:
spark-shell \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2
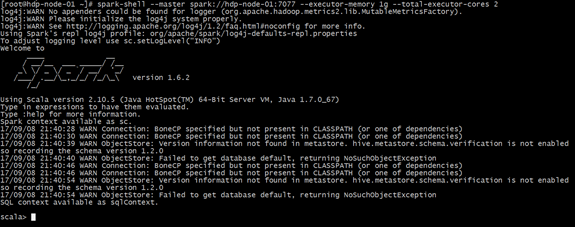
参数说明:
--master spark://hdp-node-01:7077 指定Master的地址
--executor-memory 1g 指定每个worker可用内存为1g
--total-executor-cores 2 指定整个集群使用的cup核数为2个
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
(2)编写scala代码
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/wc")
saveAsTextFile:保存结果数据到文件中
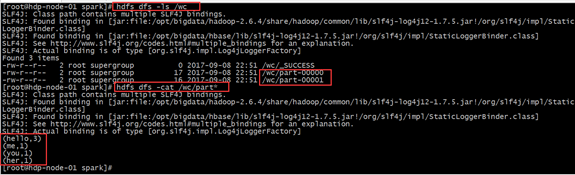
(3)查看hdfs上结果
在IDEA中编写WordCount程序
spark-shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDEA中编写程序,然后打成jar包,最后提交到集群。最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
(1).创建一个项目

(2).选择Maven项目,然后点击next
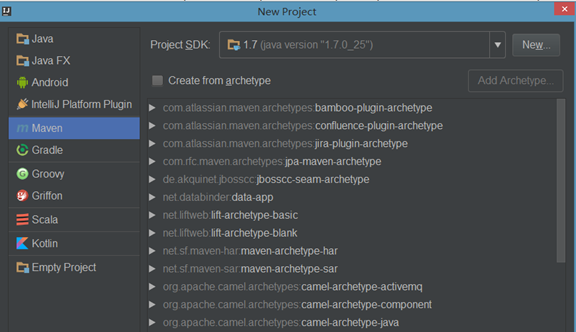
(3).填写maven的GAV,然后点击next
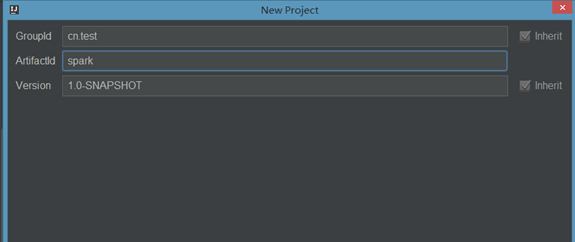
(4)填写项目名称,然后点击finish
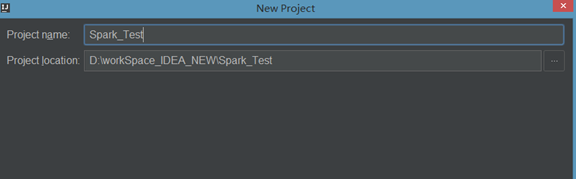
(5).创建好maven项目后,点击Enable Auto-Import
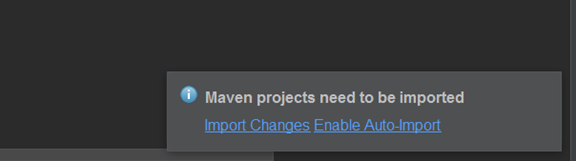
(6)配置Maven的pom.xml
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.4</hadoop.version>
<spark.version>2.0.2</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
(7)添加src/main/scala和src/test/scala,与pom.xml中的配置保持一致


(8)新建一个scala class,类型为Object
(9).编写spark程序
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object WordCount {
def main(args: Array[String]): Unit = {
//设置spark的配置文件信息
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount")
//构建sparkcontext上下文对象,它是程序的入口,所有计算的源头
val sc: SparkContext = new SparkContext(sparkConf)
//读取文件
val file: RDD[String] = sc.textFile(args(0))
//对文件中每一行单词进行压平切分
val words: RDD[String] = file.flatMap(_.split(" "))
//对每一个单词计数为1 转化为(单词,1)
val wordAndOne: RDD[(String, Int)] = words.map(x=>(x,1))
//相同的单词进行汇总 前一个下划线表示累加数据,后一个下划线表示新数据
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//保存数据到HDFS
result.saveAsTextFile(args(1))
sc.stop()
}
}
(10).使用Maven打包:
点击idea右侧的Maven Project选项
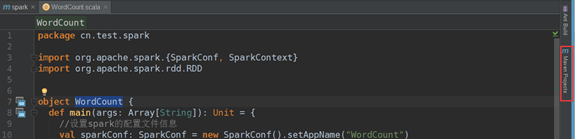
点击Lifecycle,选择package,然后点击Run Maven Build

(11).选择编译成功的jar包,并将该jar上传到Spark集群中的某个节点上
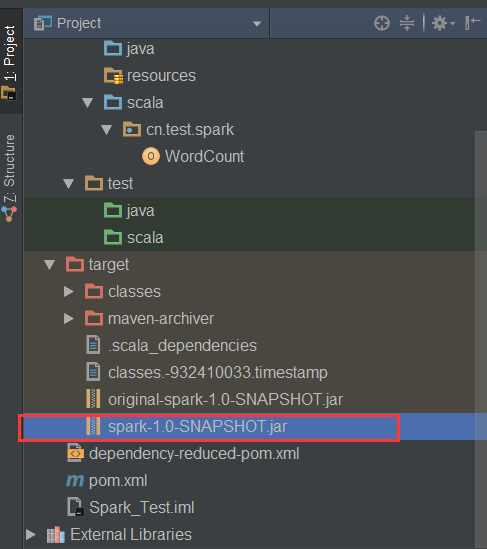
(12).首先启动hdfs和Spark集群
如果采用HA模式,先启动zookeeper集群
启动hdfs
/opt/bigdata/hadoop-2.6.4/sbin/start-dfs.sh
启动spark
/opt/bigdata/spark/sbin/start-all.sh
(13).使用spark-submit命令提交Spark应用(注意参数的顺序)
spark-submit \
--class cn.test.spark.WordCount \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
/root/spark-1.0-SNAPSHOT.jar \
/words.txt \
/spark_out
这里通过spark-submit提交任务到集群上。用的是spark的Standalone模式
Standalone模式是Spark内部默认实现的一种集群管理模式,这种模式是通过集群中的Master来统一管理资源。
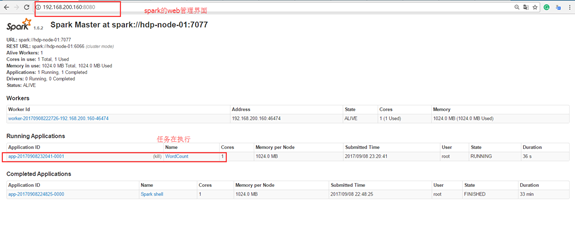
1) 查看Spark的web管理界面
地址: 192.168.200.160:8080
2) 查看HDFS上的结果文件

hdfs dfs -cat /spark_out/part*
(hello,3)
(me,1)
(you,1)
(her,1)
使用java语言编写spark wordcount程序
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays; /**
* java代码实现spark的WordCount
*/
public class WordCountJava {
public static void main(String[] args) {
//todo:1、构建sparkconf,设置配置信息
SparkConf sparkConf = new SparkConf().setAppName("WordCount_Java").setMaster("local[2]"); //todo:2、构建java版的sparkContext
JavaSparkContext sc = new JavaSparkContext(sparkConf); //todo:3、读取数据文件
JavaRDD<String> dataRDD = sc.textFile("d:/data/words1.txt"); //todo:4、对每一行单词进行切分
JavaRDD<String> wordsRDD = dataRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
String[] words = s.split(" ");
return Arrays.asList(words).iterator();
}
}); //todo:5、给每个单词计为 1
// Spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为PairRDD。
// mapToPair函数会对一个RDD中的每个元素调用f函数,其中原来RDD中的每一个元素都是T类型的,
// 调用f函数后会进行一定的操作把每个元素都转换成一个<K2,V2>类型的对象,其中Tuple2为多元组
JavaPairRDD<String, Integer> wordAndOnePairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word, 1);
}
}); //todo:6、相同单词出现的次数累加
JavaPairRDD<String, Integer> resultJavaPairRDD = wordAndOnePairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}); //todo:7、反转顺序
JavaPairRDD<Integer, String> reverseJavaPairRDD = resultJavaPairRDD.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple) throws Exception {
return new Tuple2<Integer, String>(tuple._2, tuple._1);
}
}); //todo:8、把每个单词出现的次数作为key,进行排序,并且在通过mapToPair进行反转顺序后输出
JavaPairRDD<String, Integer> sortJavaPairRDD = reverseJavaPairRDD.sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple) throws Exception {
return new Tuple2<String, Integer>(tuple._2,tuple._1);
//或者使用tuple.swap() 实现位置互换,生成新的tuple;
}
}); //todo:执行输出
System.out.println(sortJavaPairRDD.collect()); //todo:关闭sparkcontext
sc.stop();
}
}
初识Spark程序的更多相关文章
- Spark入门:第4节 Spark程序:1 - 9
五. Spark角色介绍 Spark是基于内存计算的大数据并行计算框架.因为其基于内存计算,比Hadoop中MapReduce计算框架具有更高的实时性,同时保证了高效容错性和可伸缩性.从2009年诞生 ...
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- 如何运行Spark程序
[hxsyl@CentOSMaster spark-2.0.2-bin-hadoop2.6]# ./bin/spark-submit --class org.apache.spark.examples ...
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- Spark认识&环境搭建&运行第一个Spark程序
摘要:Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度.这里总结下对Spark的认识.虚拟机Spark安装.Spark开发环境搭建及编写第一个scala程序.运 ...
- IntelliJ IDEA在Local模式下Spark程序消除日志中INFO输出
在使用Intellij IDEA,local模式下运行Spark程序时,会在Run窗口打印出很多INFO信息,辅助信息太多可能会将有用的信息掩盖掉.如下所示 要解决这个问题,主要是要正确设置好log4 ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 使用IDEA运行Spark程序
使用IDEA运行Spark程序 1.安装IDEA 从IDEA官网下载Community版本,解压到/usr/local/idea目录下. tar –xzf ideaIC-13.1.4b.tar.gz ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
随机推荐
- Orleans框架------基于Actor模型生成分布式Id
一.Actor简介 actor模型是一种并行计算的数学模型. 响应于收到的消息,演员可以:做出决定,创建更多Actor,发送更多消息,并确定如何响应接收到的下一条消息. 演员可以修改自己的状态,但只能 ...
- 【Ubuntu】执行定时任务(cron)
1.打开定时任务配置文件 crontab -e 2.编写定时任务时间 命令和脚本例如: /3 * * * * /soft/config/test.sh 前5个字段为时间,后面的一个为命令 前5个含义为 ...
- 【文档】三、Mysql Binlog事件类文件和类型
在内部,服务器使用C++类文件来表示binlog事件.标准在log_event.h文件中,这些类的方法代码在log_event.cc中. log_event是基础类.其他的详细的事件子类都是来源于他. ...
- 安装win7 64位和win10 64位双系统小结
1.gpt比mbr更先进.与主启动记录 (MBR) 分区方法相比,GPT 具有更多的优点,因为它允许每个磁盘有多达 128 个分区(mbr只支持4个分区),支持高达 18 千兆兆字节的卷大小,允许将主 ...
- 如何阅读复杂的C类型声明
阅读复杂的C类型声明,通常采用右左法则,也就是Clockwise/Spiral Rule (顺时针/螺旋法则). 本文将首先介绍工具(cdecl)(个人比较偏好使用工具提高学习和工作效率),然后中英文 ...
- 话说C语言的关键字volatile
最近搞NVMe驱动需求分析,对volatile这个单词实在是再熟悉不过了. 而在C语言中,有一个关键字就叫做volatile, 其字面意思是"挥发性的, 不稳定的,可改变的". 那 ...
- 事务,约束,范式,视图,索引,pl/sql
1.操作分类: DML. DDL. DCL manipulation definition control 2.transction 事务 起始于DML,遇到 commit ,rollb ...
- SQL:存储过程
1/什么是存储过程及概念 Transact-SQL中的存储过程,非常类似于.Net语言中的方法,它可以重复调用.当存储过程执行一次后,可以将语句缓存中,这样下次执行的时候直接使用缓存中的语句.这样就可 ...
- 微信小程序——动画操作时,rpx 和 px 的转换计算。
嫌长版本: var rpx = 10000; var systemInfo = wx.getSystemInfoSync(); var px = rpx / 750 * systemInfo.wind ...
- 用户IP地址的三个属性的区别(HTTP_X_FORWARDED_FOR,HTTP_VIA,REM_addr)
一.没有使用代理服务器的情况: REMOTE_ADDR = 您的 IP HTTP_VIA = 没数值或不显示 HTTP_X_FORWARDED_FOR = 没数值或不显示 二.使用 ...