Elasticsearch学习(4) spring boot整合Elasticsearch的聚合操作
之前已将spring boot原生方式介绍了,接下将结介绍的是Elasticsearch聚合操作。聚合操作一般来说是解决一下复杂的业务,比如mysql中的求和和分组,由于博主踩的坑比较多,所以博客可能更多的会介绍这些坑。
一、application.properties配置文件
##端口号
server.port=8880
##es地址
spring.data.elasticsearch.cluster-nodes =127.0.0.1:9300
二、创建一个Bean层
import org.springframework.data.elasticsearch.annotations.Document; @Document(indexName = "article",type = "center")
public class Zoo {
private int id;
private String animal;
private Integer num;
private String breeder;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getAnimal() {
return animal;
}
public void setAnimal(String animal) {
this.animal = animal;
}
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public String getBreeder() {
return breeder;
}
public void setBreeder(String breeder) {
this.breeder = breeder;
}
public Zoo(int id, String animal, Integer num, String breeder) {
super();
this.id = id;
this.animal = animal;
this.num = num;
this.breeder = breeder;
}
public Zoo() {
super();
} }
bean层代码
三、创建一个dao层
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository; @Configuration
public interface ZooMapper extends ElasticsearchRepository<Zoo,Integer>{ }
dao层代码
四、创建一个Controller层,编写聚合代码
import java.util.Map; import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.metrics.sum.InternalSum;
import org.elasticsearch.search.aggregations.metrics.sum.SumAggregationBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.ResultsExtractor;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController; @RestController
public class UserController { @Autowired
ZooMapper zooMapper; @Autowired
private ElasticsearchTemplate elasticsearchTemplate;
// 访问接口地址:localhost:8880/find
//存储数据
@GetMapping("find")
public Object save(){
//创建查询条件,这里表示查询所有文档
QueryBuilder queryBuilder=QueryBuilders.boolQuery();
//构造sql组装容器
NativeSearchQueryBuilder nativeSearchQueryBuilder =new NativeSearchQueryBuilder();
//创建聚合条件,求和函数
SumAggregationBuilder sumAgg = AggregationBuilders.sum("sum_num").field("num"); //将查询条件和聚合条件放入sql组装容器中
nativeSearchQueryBuilder.withQuery(queryBuilder);
nativeSearchQueryBuilder.addAggregation(sumAgg); //封装sql组装容器
SearchQuery query = nativeSearchQueryBuilder.build();
//执行sql,此时容器中的sql1为
//select SUM(num) from zoo
Aggregations aggregations = elasticsearchTemplate.query(query, new ResultsExtractor<Aggregations>() {
@Override
public Aggregations extract(SearchResponse response) {
return response.getAggregations();
}
});
//将aggregations转换成map集合
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//得到聚合的值,参数是自己定义的别名
InternalSum internalSum=(InternalSum) aggregationMap.get("sum_num");
return internalSum.getValue();
} }
controller层代码
在测试之前,我们需要在ES中添加索引:

访问 localhost:8880/find
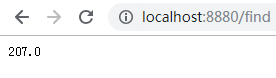
本文只介绍了求和的聚合方式,至于其他聚合方式可以参考:
http://blog.csdn.net/u010454030/article/details/63266035
五、遇到的问题
ES中text类型无法聚合问题,错误代码:
java.lang.IllegalArgumentException: Fielddata is disabled on text fields by default. Set fielddata=true on [geoip.city_name] in order to load fielddata in memory by uninverting the inverted index.
Note that this can however use significant memory. Alternatively use a keyword field instead.at org.elasticsearch.index.mapper.TextFieldMapper$TextFieldType.fielddataBuilder(TextFieldMapper.java:336)
解决方案:
通过get请求地址:http://127.0.0.1:9200/你的索引名/你的type名/_search
参数为:
{"你的type名字":
{"properties":
{"你要设置的字段名":
{"type":"text","fielddata":true}
}
}
}
Elasticsearch学习(4) spring boot整合Elasticsearch的聚合操作的更多相关文章
- Elasticsearch学习(3) spring boot整合Elasticsearch的原生方式
前面我们已经介绍了spring boot整合Elasticsearch的jpa方式,这种方式虽然简便,但是依旧无法解决我们较为复杂的业务,所以原生的实现方式学习能够解决这些问题,而原生的学习方式也是E ...
- Elasticsearch学习(1) Spring boot整合Elasticsearch
本文的Spring Boot版本为1.5.9,Elasticsearch版本为2.4.4,话不多说,直接上代码. 一.启动Elasticsearch 在官网上下载Elasticsearch后,打开bi ...
- Spring Boot整合Elasticsearch
Spring Boot整合Elasticsearch Elasticsearch是一个全文搜索引擎,专门用于处理大型数据集.根据描述,自然而然使用它来存储和搜索应用程序日志.与Logstash和K ...
- 【spring boot】【elasticsearch】spring boot整合elasticsearch,启动报错Caused by: java.lang.IllegalStateException: availableProcessors is already set to [8], rejecting [8
spring boot整合elasticsearch, 启动报错: Caused by: java.lang.IllegalStateException: availableProcessors ], ...
- Spring Boot 项目学习 (四) Spring Boot整合Swagger2自动生成API文档
0 引言 在做服务端开发的时候,难免会涉及到API 接口文档的编写,可以经历过手写API 文档的过程,就会发现,一个自动生成API文档可以提高多少的效率. 以下列举几个手写API 文档的痛点: 文档需 ...
- Spring Boot 整合 Elasticsearch,实现 function score query 权重分查询
摘要: 原创出处 www.bysocket.com 「泥瓦匠BYSocket 」欢迎转载,保留摘要,谢谢! 『 预见未来最好的方式就是亲手创造未来 – <史蒂夫·乔布斯传> 』 运行环境: ...
- spring boot 整合 elasticsearch 5.x
spring boot与elasticsearch集成有两种方式.一种是直接使用elasticsearch.一种是使用data中间件. 本文只指针使用maven集成elasticsearch 5.x, ...
- Spring Boot 整合 elasticsearch
一.简介 我们的应用经常需要添加检索功能,开源的 ElasticSearch 是目前全文搜索引擎的 首选.他可以快速的存储.搜索和分析海量数据.Spring Boot通过整合Spring Data E ...
- Spring Boot整合ElasticSearch和Mysql 附案例源码
导读 前二天,写了一篇ElasticSearch7.8.1从入门到精通的(点我直达),但是还没有整合到SpringBoot中,下面演示将ElasticSearch和mysql整合到Spring Boo ...
随机推荐
- JSON.parse() 方法解析一个JSON字符串
JSON.parse() 方法解析一个JSON字符串,构造由字符串描述的JavaScript值或对象.可以提供可选的reviver函数以在返回之前对所得到的对象执行变换. 语法EDIT JSON.pa ...
- java把流抛给浏览器下载时,当下载的文件文件名为中文时,出现中文名被替换为“----------”的情况
比如说,下载的文件名为: 软件分析报告.docx,当使用流抛给浏览器下载时,浏览器下载的文件为:-----------.docx 出现这种情况的原因:大体的原因就是header中只支持ASCII,所以 ...
- MySQL学习2---索引
MySQL 索引 MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 索引分单列索引和组合索引.单列索引,即一个索引只包含单个列,一个表可以有多个单列索引, ...
- wcf将一个服务同时绑定到http和tcp的写法
服务器端:<?xml version="1.0" encoding="utf-8" ?><configuration> <con ...
- Golang作用域—坑
先举个栗子,全局作用域变量,与 := 符号声明赋值新变量 package main import "fmt" var a = "GG" func main() ...
- Qt的安装和使用中的常见问题(详细版)
对于太长不看的朋友,可参考Qt的安装和使用中的常见问题(简略版). 目录 1.引入 2.Qt简介 3.Qt版本 3.1 查看安装的Qt版本 3.2 查看当前项目使用的Qt版本 3.3 查看当前项目使用 ...
- Linux addr2line命令
一.简介 Addr2line (它是标准的 GNU Binutils 中的一部分)是一个可以将指令的地址和可执行映像转换成文件名.函数名和源代码行数的工具.这种功能对于将跟踪地址转换成更有意义的内容来 ...
- [Training Video - 2] [Groovy Introduction]
Building test suites, Test cases and Test steps in SOAP UI Levels : test step level test case level ...
- jvm编译环境搭建 win Vc篇
/************************************************************** 技术博客 http://www.cnblogs.com/itdef/ ...
- linux git server 简易搭建 (ssh访问)
git的服务器搭建,如果无需权限控制,仅团队内部使用,初始化一个服务器仓库,其他人通过ssh访问这个文件夹即可.如需复杂的管理,建议使用gitlab. yum install git -y id gi ...