【原创】大叔经验分享(6)Oozie如何查看提交到Yarn上的任务日志
通过oozie job id可以查看流程详细信息,命令如下:
oozie job -info 0012077-180830142722522-oozie-hado-W
流程详细信息如下:
Job ID : 0012077-180830142722522-oozie-hado-W
------------------------------------------------------------------------------------------------------------------------------------
Workflow Name : test_wf
App Path : hdfs://hdfs_name/oozie/test_wf.xml
Status : KILLED
Run : 0
User : hadoop
Group : -
Created : 2018-09-25 02:51 GMT
Started : 2018-09-25 02:51 GMT
Last Modified : 2018-09-25 02:53 GMT
Ended : 2018-09-25 02:53 GMT
CoordAction ID: -
Actions
------------------------------------------------------------------------------------------------------------------------------------
ID Status Ext ID Ext Status Err Code
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@:start: OK - OK -
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@test_spark_task ERROR application_1537326594090_5663FAILED/KILLEDJA018
------------------------------------------------------------------------------------------------------------------------------------
0012077-180830142722522-oozie-hado-W@Kill OK - OK E0729
------------------------------------------------------------------------------------------------------------------------------------
失败的任务定义如下
<action name="test_spark_task">
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>${job_tracker}</job-tracker>
<name-node>${name_node}</name-node>
<master>${jobmaster}</master>
<mode>${jobmode}</mode>
<name>${jobname}</name>
<class>${jarclass}</class>
<jar>${jarpath}</jar>
<spark-opts>--executor-memory 4g --executor-cores 2 --num-executors 4 --driver-memory 4g</spark-opts>
</spark>
在yarn上可以看到application_1537326594090_5663对应的application如下
application_1537326594090_5663 hadoop oozie:launcher:T=spark:W=test_wf:A=test_spark_task:ID=0012077-180830142722522-oozie-hado-W Oozie Launcher
查看application_1537326594090_5663日志发现
2018-09-25 10:52:05,237 [main] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1537326594090_5664
yarn上application_1537326594090_5664对应的application如下
application_1537326594090_5664 hadoop TestSparkTask SPARK
即application_1537326594090_5664才是Action对应的spark任务,为什么中间会多一步,类结构和核心代码详见 https://www.cnblogs.com/barneywill/p/9895225.html
简要来说,Oozie执行Action时,即ActionExecutor(最主要的子类是JavaActionExecutor,hive、spark等action都是这个类的子类),JavaActionExecutor首先会提交一个LauncherMapper(map任务)到yarn,其中会执行LauncherMain(具体的action是其子类,比如JavaMain、SparkMain等),spark任务会执行SparkMain,在SparkMain中会调用org.apache.spark.deploy.SparkSubmit来提交任务
如果提交的是spark任务,那么按照上边的方法就可以跟踪到实际任务的applicationId;
如果你提交的hive2任务,实际是用beeline启动,从hive2开始,beeline命令的日志已经简化,不像hive命令可以看到详细的applicationId和进度,这时有两种方法:
1)修改hive代码,使得beeline命令和hive命令一样有详细日志输出
详见:https://www.cnblogs.com/barneywill/p/10185949.html
2)根据application tag手工查找任务
oozie在使用beeline提交任务时,会添加一个mapreduce.job.tags参数,比如
--hiveconf
mapreduce.job.tags=oozie-9f896ad3d40c261235dc6858cadb885c
但是这个tag从yarn application命令中查不到,只能手工逐个查找(实际启动的任务会在当前LuancherMapper的applicationId上递增),
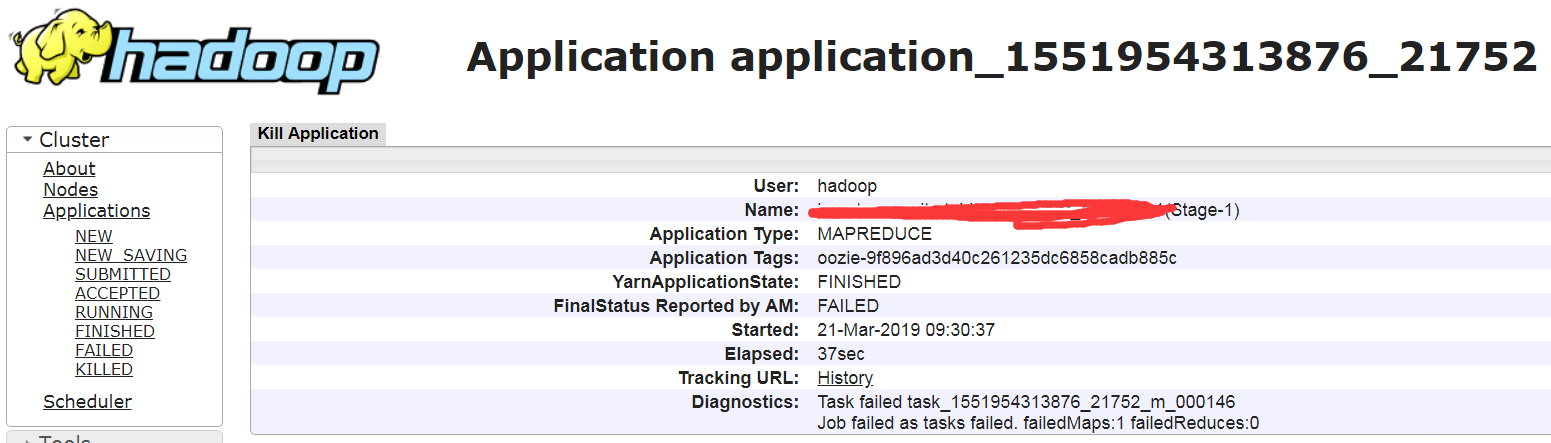
然后就可以看到实际启动的applicationId了
另外还可以从job history server上看到application的详细信息,比如configuration、task等
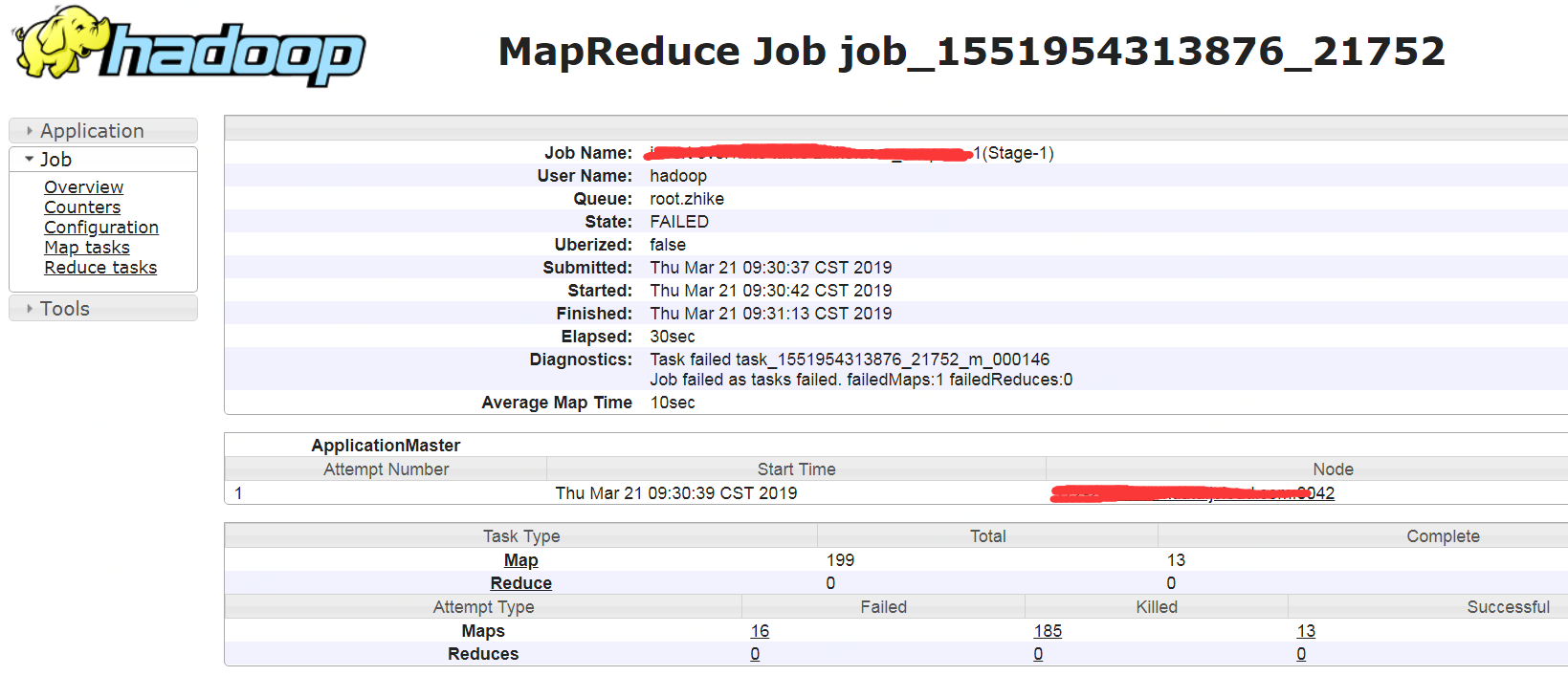
查看hive任务执行的完整sql详见:https://www.cnblogs.com/barneywill/p/10083731.html
【原创】大叔经验分享(6)Oozie如何查看提交到Yarn上的任务日志的更多相关文章
- 【原创】大叔经验分享(46)用户提交任务到yarn报错
用户提交任务到yarn时有可能遇到下面的错误: 1) Requested user anything is not whitelisted and has id 980,which is below ...
- 【原创】大叔经验分享(1)在yarn上查看hive完整执行sql
hive执行sql提交到yarn上的任务名字是被处理过的,通常只能显示sql的前边一段和最后几个字符,这样就会带来一些问题: 1)相近时间提交了几个相近的sql,相互之间无法区分: 2)一个任务有问题 ...
- 【原创】经验分享:一个小小emoji尽然牵扯出来这么多东西?
前言 之前也分享过很多工作中踩坑的经验: 一个线上问题的思考:Eureka注册中心集群如何实现客户端请求负载及故障转移? [原创]经验分享:一个Content-Length引发的血案(almost.. ...
- 【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql
spark 2.1.1 hive正在执行中的sql可以很容易的中止,因为可以从console输出中拿到当前在yarn上的application id,然后就可以kill任务, WARNING: Hiv ...
- 【原创】大叔经验分享(5)oozie提交spark任务如何添加依赖
spark任务添加依赖的方式: 1 如果是local方式运行,可以通过--jars来添加依赖: 2 如果是yarn方式运行,可以通过spark.yarn.jars来添加依赖: 这两种方式在oozie上 ...
- 【原创】大叔经验分享(49)hue访问hdfs报错/hue访问oozie editor页面卡住
hue中使用hue用户(hue admin)访问hdfs报错: Cannot access: /. Note: you are a Hue admin but not a HDFS superuser ...
- 【原创】大叔经验分享(48)oozie中通过shell执行impala
oozie中通过shell执行impala,脚本如下: $ cat test_impala.sh #!/bin/sh /usr/bin/kinit -kt /tmp/impala.keytab imp ...
- 【原创】大叔经验分享(59)kudu查看table size
kudu并没有命令可以直接查看每个table占用的空间,可以从cloudera manager上间接查看 CM is scrapping and aggregating the /metrics pa ...
- 【原创】大叔经验分享(21)yarn中查看每个应用实时占用的内存和cpu资源
在yarn中的application详情页面 http://resourcemanager/cluster/app/$applicationId 或者通过application命令 yarn appl ...
随机推荐
- docker WARNING: IPv4 forwarding is disabled 问题解决
问题: [yuyongxr@localhost ~]$sudo docker run -d --name nginx -p : nginx WARNING: IPv4 forwarding is di ...
- wget命令使用报错 certificate common name 'xxx' doesn't match requestde host name
使用wget命令 wget http://www.monkey.org/~provos/libevent-1.2.tar.gz 报如下错 error:certificate common name & ...
- How to DUMP the vba code protected by Unviewable+ VBA?
原始出处:http://www.cnblogs.com/Charltsing/p/unviewable.html QQ: 564955427 Email: charltsing@gmail.com 有 ...
- XSS原理及防范
Xss(cross-site scripting)攻击指的是攻击者往Web页面里插入恶意html标签或者javascript代码.比如:攻击者在论坛中放一个看似安全的链接,骗取用户点击后,窃取cook ...
- python爬虫爬取赶集网数据
一.创建项目 scrapy startproject putu 二.创建spider文件 scrapy genspider patubole patubole.com 三.利用chrome浏览器 ...
- kafka相关问题集锦
参考地址:https://blog.csdn.net/gao23191879/article/details/80815078?utm_source=blogxgwz5 你在写java 版的 kafk ...
- Socket通信例子
Server端 using System; using System.Collections.Generic; using System.ComponentModel; using System.Da ...
- HttpPost方式调用接口的3种方式
第一种:需要httpclient的依赖包 <dependency> <groupId>org.apache.httpcomponents</groupId> < ...
- [BZOJ 2242] [SDOI 2011] 计算器
Description 你被要求设计一个计算器完成以下三项任务: 给定 \(y,z,p\),计算 \(y^z \bmod p\) 的值: 给定 \(y,z,p\),计算满足 \(xy≡ z \pmod ...
- ☆ [WC2006] 水管局长 「LCT动态维护最小生成树」
题目类型:\(LCT\)动态维护最小生成树 传送门:>Here< 题意:给出一张简单无向图,要求找到两点间的一条路径,使其最长边最小.同时有删边操作 解题思路 两点间路径的最长边最小,也就 ...