Hadoop-2.9.2单机版安装(伪分布式模式)(一)
一、环境
硬件:虚拟机VMware、win7
操作系统:Centos-7 64位
主机名: hadoopServerOne
安装用户:root
软件:jdk1.8.0_181、Hadoop-2.9.2
二、安装jdk
1.到普通用户目录/home/lims
2.下载jdk-8u181-linux-x64.tar.gz移动到hadoop目录下,解压。
tar -zxvf jdk-8u181-linux-x64.tar.gz
mv jdk1..0_181 jdk1.8.0

三、配置ssh无密码登录
(我并没有这一步,前面配置过)
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
验证ssh,# ssh localhost
不需要输入密码即可登录。
四、安装Hadoop
1.下载Hadoop-2.9.2
2,解压安装
1),复制 Hadoop-2.9.2.tar.gz 到/home/lims目录下,
然后#tar -xzvf hadoop-2.9.2.tar.gz 解压,解压后目录为:/home/lims/hadoop-2.9.2
2),在/home/lims/目录下,建立tmp、hdfs/name、hdfs/data目录,执行如下命令 (PS:可以略过,格式化namenode时会根据配置文件创建)
#mkdir /home/lims/tmp
#mkdir /home/lims/hdfs
#mkdir /home/lims/hdfs/data
#mkdir /home/lims/hdfs/name
3),设置环境变量,#vi ~/.bash_profile
编辑insert
保存退出esc :wq :q!(退出不保存)
# set hadoop path
export HADOOP_HOME=/home/lims/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
4),使环境变量生效,$source ~/.bash_profile
3,Hadoop配置
进入$HADOOP_HOME/etc/hadoop目录,配置 hadoop-env.sh等。涉及的配置文件如下:
hadoop-2.9.2/etc/hadoop/hadoop-env.sh
hadoop-2.9.2/etc/hadoop/yarn-env.sh
hadoop-2.9.2/etc/hadoop/core-site.xml
hadoop-2.9.2/etc/hadoop/hdfs-site.xml
hadoop-2.9.2/etc/hadoop/mapred-site.xml
hadoop-2.9.2/etc/hadoop/yarn-site.xml
1)配置hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/hadoop/jdk1.8.0
2)配置yarn-env.sh
#export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/hadoop/jdk1.8.0
3)配置core-site.xml
添加如下配置(为了让Windows浏览器能访问到,写虚拟机地址,而不是localhost):
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.3.132:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/lims/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
4),配置hdfs-site.xml
添加如下配置
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/lims/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property> <property>
<name>dfs.data.dir</name>
<value>/home/lims/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property> <property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
5),配置mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6),配置yarn-site.xml
添加如下配置(端口改为了8099):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8099</value>
</property>
</configuration>
4.安装后启动步骤:
1).格式化hdfs文件系统
bin/hadoop namenode -format
2).启动namenode
sbin/hadoop-daemon.sh start namenode
3).启动datanode
sbin/hadoop-daemon.sh start datanode
4).启动yarn
sbin/start-yarn.sh
5.验证
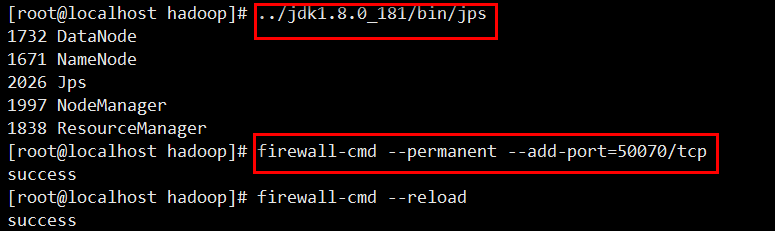
1)执行jps命令,有如下进程,说明Hadoop正常启动

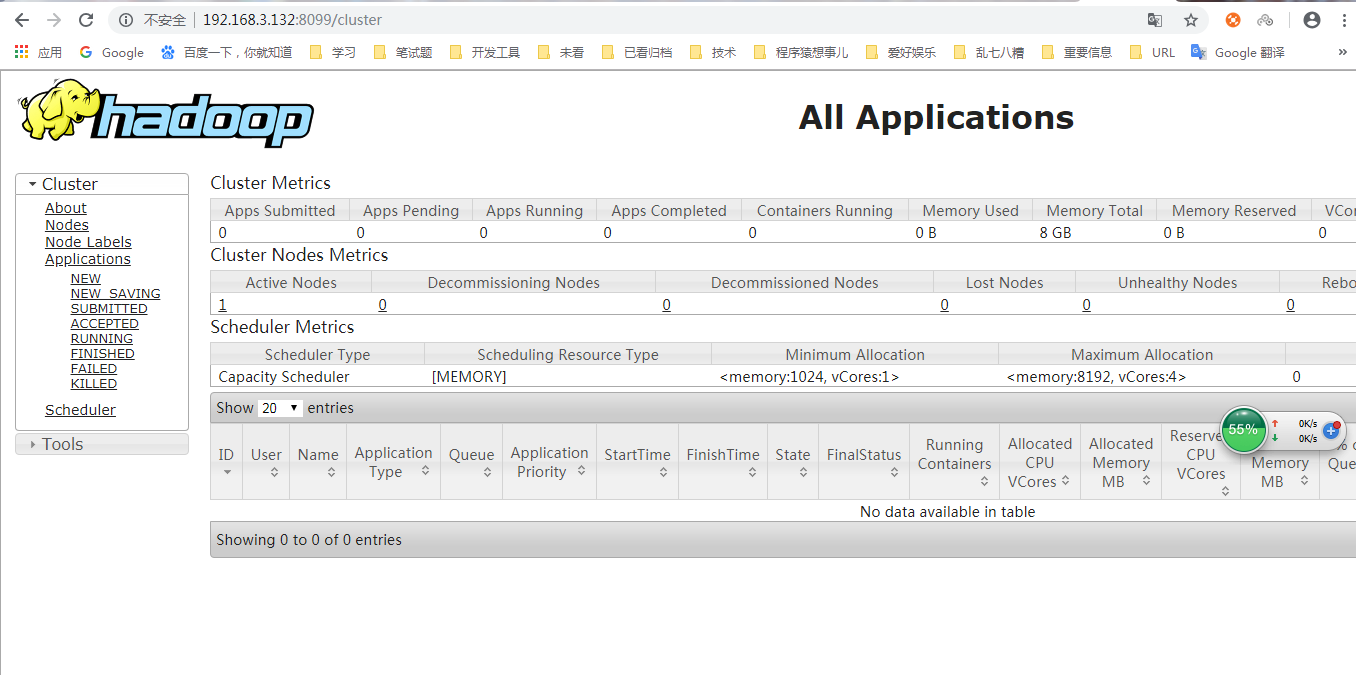
2)在浏览器中输入:http://192.168.2.2:8099/cluster 即可看到YARN的ResourceManager的界面。PS:默认端口是8088,这里设置了yarn.resourcemanager.webapp.address为:${yarn.resourcemanager.hostname}:8099
namenode查看:http://192.168.2.2:50070

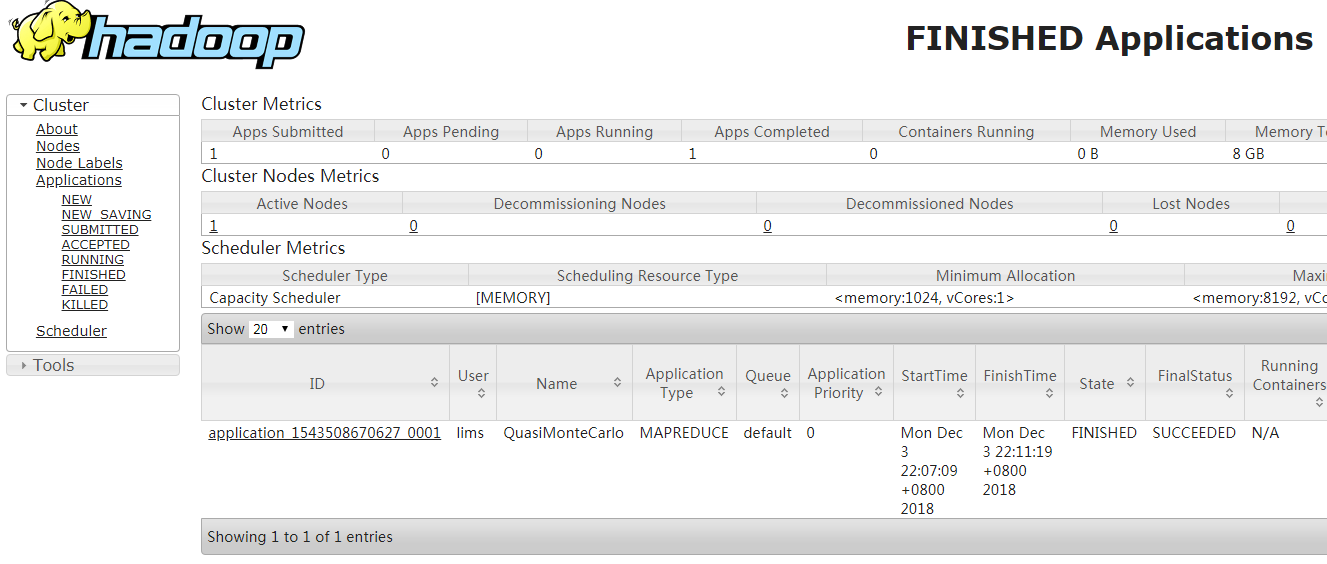
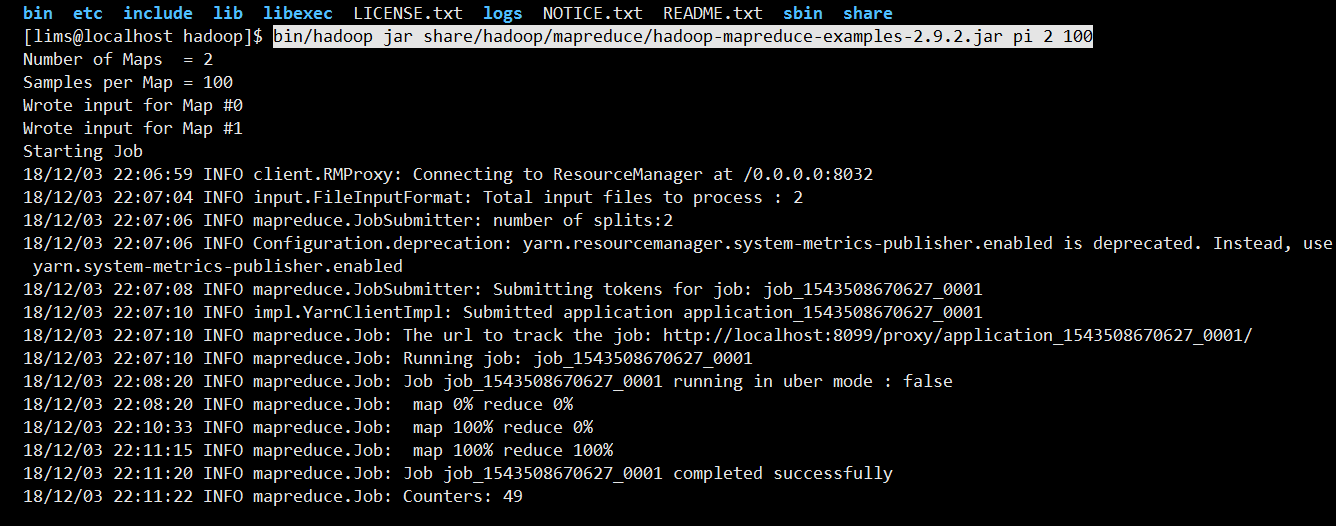
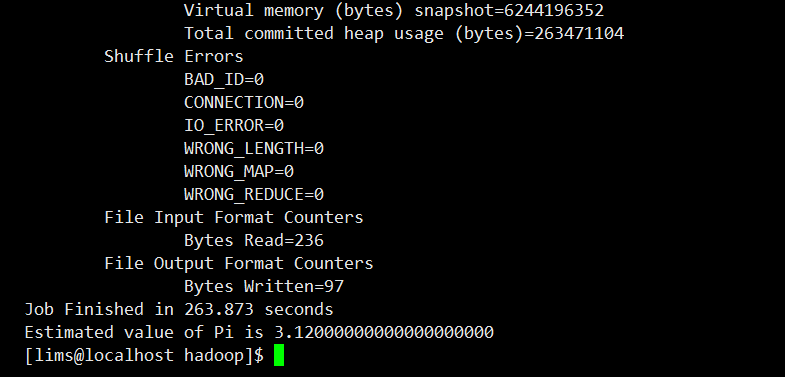
启动MapReduce作业运行查看结果
进入Hadoop目录
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9..jar pi
注意(linux防火墙打开端口)
PS:在Windows浏览器中访问虚拟机中的Linux,需要centos防火墙打开相应端口
打开8099端口:
firewall-cmd --permanent --add-port=/tcp
重新载入:
firewall-cmd --reload
宿主机访问页面需要开启的端口
1. 50070(HDFS端口)
2. 8099(yarn页面端口)
3. 50075(datanode页面端口)
4. 8042(作业运行过程yarn页面查看application端口)
常见问题:
1. 采用虚拟机安装后,每次重启虚拟机Hadoop无法启动成功
在core-site.xml中增加两个配置:
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/lims/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/lims/hadoop/dfs/data</value>
</property>
Hadoop-2.9.2单机版安装(伪分布式模式)(一)的更多相关文章
- Hadoop Single Node Setup(hadoop本地模式和伪分布式模式安装-官方文档翻译 2.7.3)
Purpose(目标) This document describes how to set up and configure a single-node Hadoop installation so ...
- Ubuntu下伪分布式模式Hadoop的安装及配置
1.Hadoop运行模式Hadoop有三种运行模式,分别如下:单机(非分布式)模式伪分布式(用不同进程模仿分布式运行中的各类节点)模式完全分布式模式注:前两种可以在单机运行,最后一种用于真实的集群环境 ...
- 云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
一.实验目的 1. 掌握Linux虚拟机的安装方法. 2. 掌握Hadoop的伪分布式安装方法. 二.实验内容 (一)Linux基本操作命令 Linux常用基本命令包括: ls,cd,mkdir,rm ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- HBase入门基础教程之单机模式与伪分布式模式安装(转)
原文链接:HBase入门基础教程 在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Had ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Ubuntu 14.10 下安装伪分布式hdoop 2.5.0
折腾了一天,其间配置SSH时候出现了问题,误删了ssh-keygen相关文件,导致配置SSH彻底萎了,又重装了系统.... 采用伪分布式模式,即hadoop将所有进程运行于同一台主机上,但此时Hado ...
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
- HBase入门基础教程 HBase之单机模式与伪分布式模式安装
在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Hadoop完全分布式环境,搭建Hado ...
随机推荐
- Mysql漏洞修复方法思路及注意事项
[系统环境] 系统环境:Red Hat Enterprise Linux Server release 5.4 (Tikanga) + 5.7.16 MySQL Community Server ...
- [再寄小读者之数学篇](2014-10-18 利用 Lagrange 中值定理求极限)
试求 $$\bex \vlm{n}n^2\sex{x^\frac{1}{n}-x^\frac{1}{n+1}},\quad x>0. \eex$$ 解答: $$\beex \bea \mbox{ ...
- SQL注入关联分析
在Web攻防中,SQL注入绝对是一个技能的频繁项,为了技术的成熟化.自动化.智能化,我们有必要建立SQL注入与之相关典型技术之间的关联规则.在分析过程中,整个规则均围绕核心词进行直线展开,我们简单称之 ...
- MD1——2 Corner
基本句型 被分为 5 种全然因为[动词] 造成的. 那么补语 就是因为 动词被解释成“是”的时候所需要的一种补足. [补语 Complement 传统的毒瘤说法] 不完全不及物动词 不完全及物动词~~ ...
- Contest2156 - 2019-3-7 高一noip基础知识点 测试2 题解版
传送门 预计得分:100+70+100+50=320 实际得分100+63+77+30=270 Ctrl_C+Ctrl_V时不要粘贴翻译的,直接粘原文, In a single line of the ...
- vue父子组件之间互相获取data值&调用方法(非props)
vue 子组件调用父组件方法&数据 vue有$parent这么一个属性,在子组件中就能拿到父组件的数据 this.$parent.xxx 就能调用父组件的方法 this.$parent.xxx ...
- C语言malloc函数为一维,二维,三维数组分配空间
c语言允许建立内存动态分配区域,以存放一些临时用的数据,这些数据不必在程序的声明部分定义,也不必等到函数结束时才释放,而是需要时随时开辟,不需要时随时释放,这些数据存储在堆区.可以根据需要,向系统申请 ...
- Android串口通信(Android Studio)
gilhub上已有开源项目: https://github.com/cepr/android-serialport-api 可以直接使用
- hadoop的master和slave模式
hadoop的集群是基于master/slave模式. namenode和jobtracker属于master,datanode和tasktracker属于slave,master只有一个,而slav ...
- kafka_2.11-2.1.0测试
kafka测试启动创建topic ./kafka-topics.sh --create --zookeeper dip005:2181,dip006:2181,dip007 --replication ...