基于密度峰值的聚类(DPCA)
1、背景介绍
密度峰值算法(Clustering by fast search and find of density peaks)由Alex Rodriguez和Alessandro Laio于2014年提出,并将论文发表在Science上。Science上的这篇文章《Clustering by fast search and find of density peaks》主要讲的是一种基于密度的聚类方法,基于密度的聚类方法的主要思想是寻找被低密度区域分离的高密度区域。 密度峰值算法(DPCA)基于这样的假设:(1)类簇中心点的密度大于周围邻居点的密度;(2)类簇中心点与更高密度点之间的距离相对较大。因此,DPCA主要有两个需要计算的量:第一,局部密度;第二,与高密度点之间的距离。
2、局部密度
数据对象的局部密度
定义为:
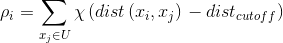
其中,表示截断距离
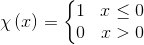 ,这个公式的含义是说找到与第
,这个公式的含义是说找到与第个数据点之间的距离小于截断距离
的数据点的个数,并将其作为第i个数据点真的密度。
3、定义聚类中心距离
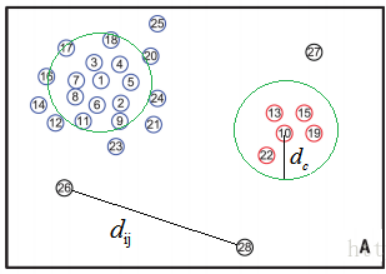
密度峰聚类算法的巧妙之处:就是在于聚类中心距离 δi的选定。根据局部密度的定义,我们可以计算出上图中每个点的密度,依照密度确定聚类中心距离 δi。
1.首先将每个点的密度从大到小排列: ρi > ρj > ρk > ….;密度最大的点的聚类中心距离与其他点的聚类中心距离的确定方法是不一样的;
2.先确定密度最大的点的聚类中心距离–i点是密度最大的点,它的聚类中心距离δiδi等于与i点最远的那个点n到点i的直线距离 d(i,n);
3. 再确定其他点的聚类中心距离——其他点的聚类中心距离是等于在密度大于该点的点集合中,与该点距离最小的的那个距离。例如i、j、k的密度都比n点的密度大,且j点离n点最近,则n点的聚类中心距离等于d(j,n);
4. 依次确定所有的聚类中心距离δ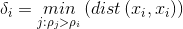
4、聚类效果
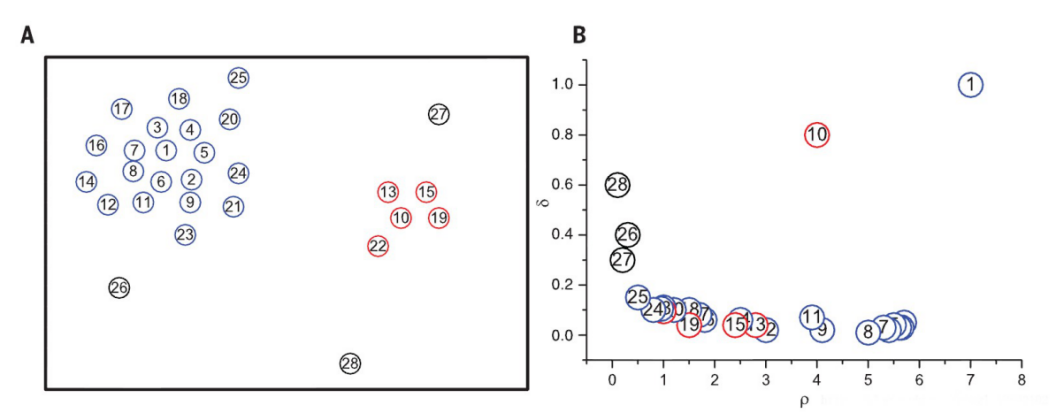
将所有点的聚类中心密度都统计出来后,将其值按 δi和pi作为坐标轴作图可以得到如图所示结果。可以看到图中1,10两个聚类中心同时远离坐标轴。普通点则是靠近p轴,异常点靠近 δ轴。
5、基于python的实现:
python代码如下,其中要引入numpy等一些包,pycharm中引入包还是比较简单的。
# -*- coding:utf- -*-
# -*- python3.
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors min_distance = 4.6 # 邻域半径
points_number = # 随机点个数 # 计算各点间距离、各点点密度(局部密度)大小
def get_point_density(datas,labers,min_distance,points_number):
# 将numpy.ndarray格式转为list格式,并定义元组大小
data = datas.tolist()
laber = labers.tolist()
distance_all = np.random.rand(points_number,points_number)
point_density = np.random.rand(points_number) # 计算得到各点间距离
for i in range(points_number):
for n in range(points_number):
distance_all[i][n] = np.sqrt(np.square(data[i][]-data[n][])+np.square(data[i][]-data[n][]))
print('距离数组:\n',distance_all,'\n') # 计算得到各点的点密度
for i in range(points_number):
x =
for n in range(points_number):
if distance_all[i][n] > and distance_all[i][n]< min_distance:
x = x+
point_density[i] = x
print('点密度数组:', point_density, '\n')
return distance_all, point_density # 计算点密度最大的点的聚类中心距离
def get_max_distance(distance_all,point_density,laber):
point_density = point_density.tolist()
a = int(max(point_density))
# print('最大点密度',a,type(a)) b = laber[point_density.index(a)]
# print("最大点密度对应的索引:",b,type(b)) c = max(distance_all[b])
# print("最大点密度对应的聚类中心距离",c,type(c)) return c # 计算得到各点的聚类中心距离
def get_each_distance(distance_all,point_density,data,laber):
nn = []
for i in range(len(point_density)):
aa = []
for n in range(len(point_density)):
if point_density[i] < point_density[n]:
aa.append(n)
# print("大于自身点密度的索引",aa,type(aa))
ll = get_min_distance(aa,i,distance_all, point_density,data,laber)
nn.append(ll)
return nn # 获得:到点密度大于自身的最近点的距离
def get_min_distance(aa,i,distance_all, point_density,data,laber):
min_distance = []
"""
如果传入的aa为空,说明该点是点密度最大的点,该点的聚类中心距离计算方法与其他不同
"""
if aa != []:
for k in aa:
min_distance.append(distance_all[i][k])
# print('与上各点距离',min_distance,type(nn))
# print("最小距离:",min(min_distance),type(min(min_distance)),'\n')
return min(min_distance)
else:
max_distance = get_max_distance(distance_all, point_density, laber)
return max_distance def get_picture(data,laber,points_number,point_density,nn):
# 创建Figure
fig = plt.figure()
# 用来正常显示中文标签
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
# 用来正常显示负号
matplotlib.rcParams['axes.unicode_minus'] = False # 原始点的分布
ax1 = fig.add_subplot()
plt.scatter(data[:,],data[:,],c=laber)
plt.title(u'原始数据分布')
plt.sca(ax1)
for i in range(points_number):
plt.text(data[:,][i],data[:,][i],laber[i]) # 聚类后分布
ax2 = fig.add_subplot()
plt.scatter(point_density.tolist(),nn,c=laber)
plt.title(u'聚类后数据分布')
plt.sca(ax2)
for i in range(points_number):
plt.text(point_density[i],nn[i],laber[i]) plt.show() def main():
# 随机生成点坐标
data, laber = ds.make_blobs(points_number, centers=points_number, random_state=)
print('各点坐标:\n', data)
print('各点索引:', laber, '\n') # 计算各点间距离、各点点密度(局部密度)大小
distance_all, point_density = get_point_density(data, laber, min_distance, points_number)
# 得到各点的聚类中心距离
nn = get_each_distance(distance_all, point_density, data, laber)
print('最后的各点点密度:', point_density.tolist())
print('最后的各点中心距离:', nn) # 画图
get_picture(data, laber, points_number, point_density, nn)
"""
距离归一化:就把上面的nn改为:nn/max(nn)
""" if __name__ == '__main__':
main()
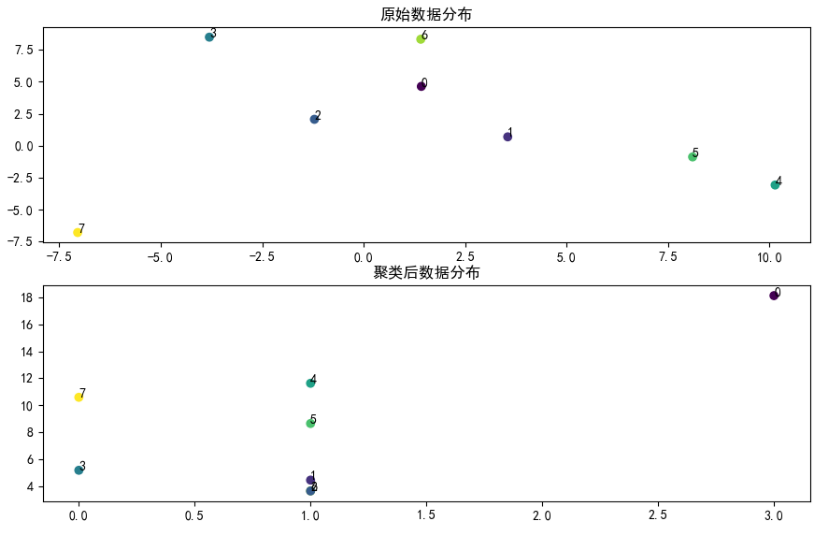
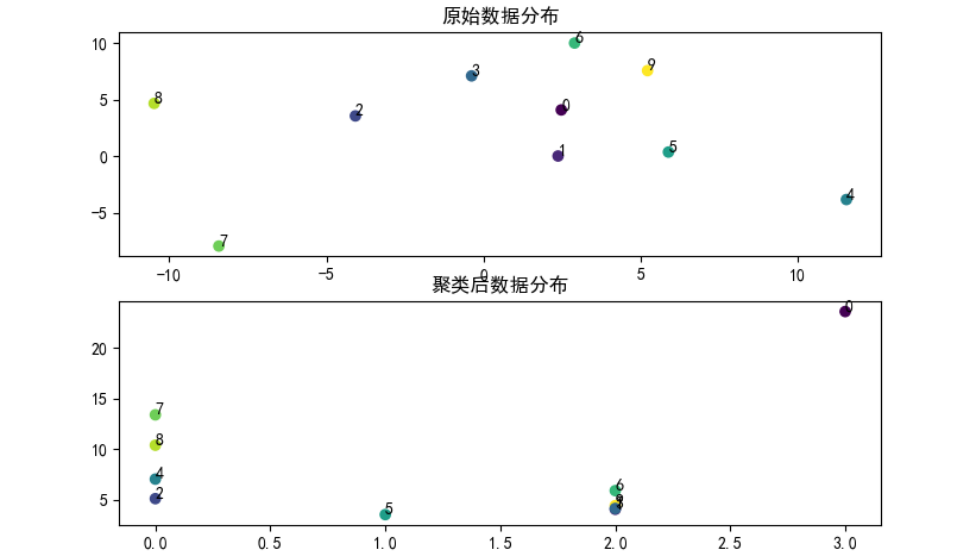
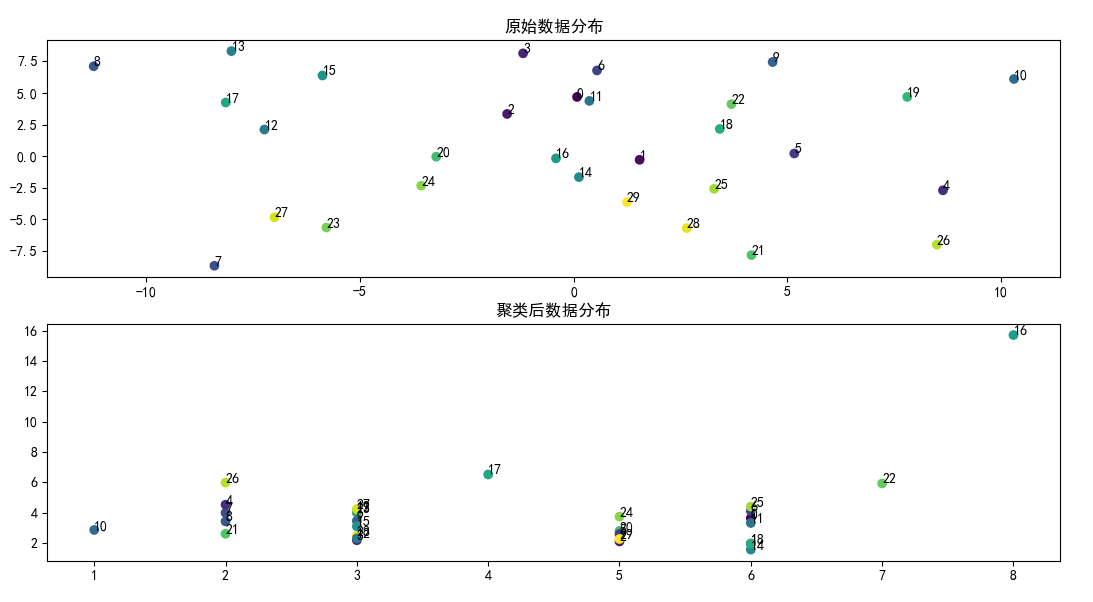
代码运行效果如下图:
基于密度峰值的聚类(DPCA)的更多相关文章
- 聚类-DBSCAN基于密度的空间聚类
1.DBSCAN介绍 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- 密度峰值聚类算法(DPC)
密度峰值聚类算法(DPC) 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 简介 基于密度峰值的聚类算法全称为基于快速搜索和发现密度峰值的聚类算法(cl ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
- 密度峰值聚类算法原理+python实现
密度峰值聚类(Density peaks clustering, DPC)来自Science上Clustering by fast search and find of density peaks ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 【机器学习】DBSCAN Algorithms基于密度的聚类算法
一.算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层 ...
随机推荐
- 如何定制Linux外围文件系统?
本文由云+社区发表 作者:我是乖宝宝哦 一般来说,我们所说的Linux系统指的是各种基于Linux Kernel和GNU Project的操作系统发行版.为了掌握Linux操作系统的使用,了解 Lin ...
- springmvc 项目完整示例02 项目创建-eclipse创建动态web项目 配置文件 junit单元测试
包结构 所需要的jar包直接拷贝到lib目录下 然后选定 build path 之后开始写项目代码 配置文件 ApplicationContext.xml <?xml version=" ...
- Nginx 初識
今天簡單了解了一下Nginx,并在本機安裝,并簡單配置了一下,道理什麼的還不懂,就是看能不能跑起來. 1.安裝從官網下載就好,把文件隨便解壓在一個英文目錄裡面. 然後修改配置文件,修改的內容如下: 2 ...
- year 和 weak year 的区别
java 中使用 SimpleDateFormat 时,会遇到 year 和 week year 这两个概念,特此记录. google 答案: A week year is in sync with ...
- 【代码笔记】Web-CSS-CSS Padding(填充)
一,效果图. 二,代码. <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- opencv3.2.0图像处理之高斯滤波GaussianBlur API函数
/*高斯滤波:GaussianBlur函数 函数原型: void GaussianBlur( InputArray src, OutputArray dst, Size ksize, double s ...
- 0.react学习笔记-环境搭建与脚手架
0.环境搭建 笔者使用的是deepin/mac两种系统,因为两个电脑经常切换用.环境搭建没什么区别. 0.1 node安装 按照node官网叙述安装 # Using Debian, as root c ...
- SuperMap iClient 如何使用 WMTS 地图服务(转载)
原文链接: WMTS服务初步理解与读取 https://blog.csdn.net/supermapsupport/article/details/76806670 SuperMap iClient ...
- python地理处理包——pySAL使用
Pysal是基于Python的开源地理处理库,能提供高层次的空间分析功能.
- WebGIS中以version方式实现代码更新后前端自动读取更新代码的方法
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 前言 GIS代码进行更新后,由于用户前端已有缓存,导致更新的功能不 ...