排序算法以及其java实现
一、术语了解
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
- 不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
- 内排序:所有排序操作都在内存中完成;
- 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
- 时间复杂度: 一个算法执行所耗费的时间。
- 空间复杂度:运行完一个程序所需内存的大小。

图片名词解释:
- n: 数据规模
- k: “桶”的个数
- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
二、基础算法
1、冒泡算法
(1)思想:两两比较,每一趟都把最大或最小的数浮出
(2)优化:设置一个boolean isOrdered ;
在第一轮排序中一旦a[j] > a[j+1],就把isOrdered设为false,否则isOrdered设为true,然后我们在每趟排序前检查isOrdered,一旦发现它为false,即认为排序已完成。
(3)时间复杂度:要进行的比较次数为: (n-1) + (n-2) + ... + 1 = n*(n-1) / 2,因此冒泡排序的时间复杂度为O(n^2)。
最好的为O(n):数组已经有序,比较次数为n-1
public static void bubbleSort(int[] arr) {
int i,j,temp;
boolean isOrdered = true;
for(i=0;i<arr.length-1;i++) {
for(j=0;j<arr.length-i-1;j++) {
if(arr[j]>arr[j+1]) {
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
isOrdered = false;
}
}
if(!isOrdered) {
break;
}
}
}
2、选择排序算法
(1)思想:用第一个数与其他数进行比较,选出序列中最小的数;把最小的数与第一个数交换位置;依次进行
(2)时间复杂度:要进行的比较次数为: (n-1) + (n-2) + ... + 1 = n*(n-1) / 2,因此选择排序的时间复杂度为O(n^2)。
public static void selectSort(int[] a) {
int N = a.length;
for (int i = 0; i < N - 1; i++) {
int min = i;
for (int j = i + 1; j < N; j++) {
if (a[j] < a[min]) {
min = j;
}
}
exchange(a, i, min);
}
}
public static void exchange(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
3、直接插入排序算法
(1)思想:在一组序列中,假设前面(n-1)[n>=2]个元素都已经拍好序,现在把第n个数插入到前面的有序序列中,使得这n个数都有序。
(2)分析:以抓牌过程来举例,i为刚抓的牌的索引,i-1为我们刚排好的牌中的最后一张的索引,赋值给 j = i - 1 。在内层循环中,若a[ i ] < a[ j ],则 j--,
继续向前比较,直到找到 a[ i ] < a[ j ],就会跳出内层循环,这时我们把a[i]插入到a[j]后(把大于a[ i ]的数往后挪一个位置),就把刚抓的牌插入
到已排好牌中的合适的位置了。重复以上过程就能完成待排序数组的排序。
(3)时间复杂度:在平均情况下以及最坏情况下,它的时间复杂度均为O(n^2),而在最好情况下(输入数组完全有序),插入排序的时间复杂度能够提升至O(N)
(4)适合场景 :插入排序对于部分有序的数组十分高效,也很适合小规模的数组。
public static void insertSort(int[] a) {
int i, j;
//可以想象是把数组分为两边,左边是排好序的 j(0~i-1), 右边是未排序的 i(1~a.length)
for (i = 1; i < a.length; i++) {
for (j = i - 1; j >= 0 && a[i] < a[j]; j--) {
}
// 将a[i]插入到a[j]后面,把大于a[i]的数往后挪一个位置
int temp = a[i];
for (int k = i; k > j + 1; k--) {
a[k] = a[k - 1];
}
a[j + 1] = temp;
}
}
4、希尔排序算法
(1)思想:先将待排序列按某个增量h分为若干组,然后对每个组中的子序列进行插入排序,缩小增量,再分组排序,当增量为1时,排序完成。
(2)分析:希尔排序是对直接插入排序的优化。 实际上,h的取值序列的选取会影响到希尔排序的性能。引用结论:
使用递增序列1, 4, 13, 40, 121, 364, ...的希尔排序所需的比较次数不会超过数组尺寸的若干倍乘以递增序列的长度。即h = 3 * k + 1,其中k为[0, N/3)区间内的整数。
(3)时间复杂度:在通常情况下,希尔排序的复杂度要比O(n^2)好得多。实际上,最坏情况下希尔排序所需要的比较次数与O(n^1.5)成正比,
在实际使用中,希尔排序要比插入排序和选择排序、冒泡排序快得多。而且尽管待排序数组很大,希尔排序也不会比快速排序等高级算法慢很多。平均复杂度为O(nlogn)
public static void ShellSort(int[] a) {
int N = a.length;
int h=1;
while(h<N/3) {
h = h*3+1;
}
while(h>=1) {
int n,i,j,k;
//划分为n个子序列,每个子序列进行插入排序
for(n=0;n<h;n++) {
for(i=n+h;i<N;i+=h) {
for(j=i-h;j>=0&&a[j]>a[i];j-=h) {}
int temp = a[i];
//往后挪一个位置
for(k=i;k>j+h;k-=h) {
a[k]=a[k-h];
}
//腾出的位置复制给a[i]
a[j+h] = temp;
}
}
h=h/3;
}
}
5、基础算法的比较:希尔排序要比其他三种排序都快,而插入排序要比选择排序、冒泡排序快,冒泡排序在实际执行性能最差。
二、高级算法
1、归并排序算法
(1)思想:归并排序的主要思想是:将待排序数组递归的分解成两半,分别对它们进行排序,然后将结果“归并”(递归的合并)起来。

(2)缺点:所需的额外空间与待排序数组的尺寸成正比,需要重新创建一个大小与原数组一样的的数组来存放结果
(3)时间复杂度:归并排序的时间复杂度为O(nlogn)
2、快速排序算法
快速排序是目前应用最广泛的排序算法之一,它是一般场景中大规模数据排序的首选,它的实际性能要好于归并排序。通常情况下,快速排序的时间复杂度为O(nlogn),但在最坏情况下它的时间复杂度会退化至O(n^2),除了实际执行性能好,快速排序的另一个优势是它能够实现“原地排序”,也就是说它几乎不需要额外的空间来辅助排序。
(1)思想:选取一个基准点,分别从数组两端想中间扫描数组。设置两个标志low,high ;
首先从后半部分开始往low方向扫描,如果发现元素值小于基准点,则交换low,high,
然后从前半部分向high方向开始扫描,如果发现元素值大于基准点的值,就换low,high位置,重复这两步,知道low=high,完成一趟排序;
然后递归左右子数组。
(2)优化:
a、对于尺寸比较小的数组,插入排序要比快速排序快,因此当递归调用切分方法到切分所得数组已经很小时,我们不妨用插入排序来排序小数组。
b、三数取中:当输入的数组已经有序时,每次划分就只能使得待排序列减一,最坏情况下它的时间复杂度会退化至O(n^2)
(3)时间复杂度:通常情况下,快速排序的时间复杂度为O(nlogn)
//三数取中
public static int SelectPivotMedianOfThree(int arr[], int start, int end) {
int mid = (start + end) / 2;
if (arr[end] < arr[start]) {
swap(arr, start, end);
}
if (arr[end] < arr[mid]) {
swap(arr, mid, end);
}
if (arr[start] < arr[mid]) {
swap(arr, mid, start);
}
return arr[start];
} private static void swap(int[] arr, int start, int end) {
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
}
//完成一趟划分
public static int partition(int[] a, int low, int high) {
int key = SelectPivotMedianOfThree(a, low, high);
while (low < high) {
while (a[high] >= key && high > low) {
high--;
}
a[low] = a[high];
while (a[low] <= key && high > low) {
low++;
}
a[high] = a[low];
}
a[high] = key;
return high;
} public static void fastSort(int[] a, int low, int high) {
if (low >= high)
return; //在这里可以使用插入排序进行优化 if(high <= low + size) insertSort(a,low ,high) size为一个常数,可以是5~15
int index = partition(a, low, high);
fastSort(a, low, index - 1);
fastSort(a, index + 1, high);
}
3、堆排序算法
(1)思想:堆排序是将数据看成完全二叉树,根据完全二叉树的特性来进行排序的一种算法。堆分为大顶堆和小顶堆。
(2)时间复杂度:时间复杂度为O(nlogn)
(3)适用:堆排序是我们所知的唯一能够同时最优地利用空间和时间的方法——在最坏情况下他也能保证~2NlgN次比较和恒定的额外空间。

public static void maxHeapDown(int[]a,int currentRootNode,int size) {
int c = currentRootNode;
int left = 2*c+1; //左孩子
//进行根节点与左右孩子的比较
for(;left<=size;c=left,left=left*2+1) {
if(left<size && a[left]<a[left+1])//选出左右孩子中较大的一个
left++;
if(a[c]>=a[left]);//较大的孩子与父节点进行比较
else {
int temp = a[c];
a[c] = a[left];
a[left] = temp;
}
}
}
public static void heapSort(int[]a) {
int n = a.length;
int i,temp;
//一趟排序,得到一个根元素最大的二叉堆
for(i=n/2-1;i>=0;i--) {
maxHeapDown(a, i, n-1);
}
for(i=n-1;i>0;i--) {
temp = a[0];
a[0] = a[i];
a[i] = temp;
maxHeapDown(a, 0, i-1);//缩小范围a[1..n-1]
}
}
4、计数排序算法
(1)思想:找出数组中的最大值和最小值;
创建另外一个数组c[min~max]来统计每个元素中出现的次数,并求前缀和;
创建临时数组b来输出结果,反向遍历原数组a
i = 8 , a[9] = 3 ; c[3] = 7; b[7] = 3, c[3]--
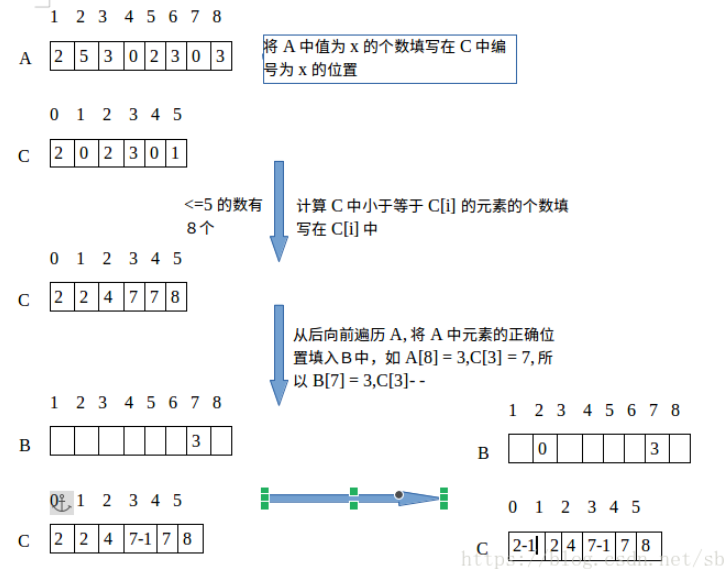
(2)适用:适用于元素值分布连续,跨度小的情况
(3)时间复杂度:O(n+k),k为数组中的最大值
5、桶排序算法
(1)桶排序的思想:
- 根据输入建立适当个数的桶,每个桶可以存放某个范围内的元素;
- 将落在特定范围内的所有元素放入对应的桶中;
- 对每个非空的桶中元素进行排序,可以选择通用的排序方法,比如插入、快排;
- 按照划分的范围顺序,将桶中的元素依次取出。排序完成。
举个例子,假如被排序的元素在0~99之间,我们可以建立10个桶,每个桶按范围顺序依次是[0, 10)、[10, 20]......[90, 99),注意是左闭右开区间。对于待排序数组[0, 3, 2, 80, 70, 75, 72, 88],[0, 3, 2]会被放到[0, 10)这个桶中,[70 ,75, 72]会被放到[70, 80)这个桶中,[80, 88]会被放到[80, 90)这个桶中,对这三个桶中的元素分别排序。得到
- [0, 10)桶中的元素: [0, 2, 3]
- [70, 80)桶中的元素: [70, 72, 75]
- [80, 90)桶中的元素: [80, 88]
依次取出三个桶中元素,得到序列[0, 2, 3, 70, 72, 75, 80, 88]已经排序完成。
可以用一个数组bucket[]存放各个桶,每个桶用链表表示,用于存放处于同一范围内的元素。上面建立桶的方法是根据输入范围为0~99,建立了10个桶,每个桶可以装入10个元素,这将元素分布得很均匀,在桶排序中保证元素均匀分布到各个桶尤为关键。
要注意:如何选择桶的个数,以及使用哪个映射函数将元素转换成桶的索引都是不一定的。
例如:
- 建立的桶个数与待排序数组个数相同,这个简单的数字虽然大多数情况下会浪费许多空间(很多桶是空的),但也正因为桶的数量多,也很好地避免了大量元素都装入同一个桶中的情况。
- 对于待排序数组中每个元素,使用如下映射函数将每个元素放到合适的桶中。这相当于每个桶能装的元素个数为
- bucketIndex = (value * arr.length) / (maxValue + 1)
桶排序可以是稳定的。这取决于我们对每个桶中的元素采取何种排序方法,比如桶内元素的排序使用快速排序,那么桶排序就是不稳定的;如果使用的是插入排序,桶排序就是稳定的。桶排序和计数排序有个共同的缺点:耗费大量空间。
桶排序也不能很好地应对元素值跨度很大的数组。比如[3, 2, 1, 0 ,4, 8, 6, 999],按照上面的映射规则,999会放入一个桶中,剩下所有元素都放入同一个桶中,在各个桶中元素分布极不均匀,这就失去了桶排序的意义。
6、基数排序算法
(1)思想:将整数按位数切割成不同的数字,然后利用桶排序算法存储和分别比较每个位数,并进行排序。
(2)实现:首先把序列统一长度,采取高位补0,然后从最低位开始,依次排序。
public static int get_max( int[] a) {
int max=a[0];
for(int i=1;i<a.length;i++) {
if(a[i]>max)
max = a[i];
}
return max;
}
public static void count_sort(int []a,int exp) {
int i;
int output[] = new int[a.length];//存储结果
int buckets[] = new int[10];//10个桶
//统计频数
for(i=0;i<a.length;i++) {
buckets[(a[i]/exp)%10]++;
}
//求前缀和,第一个没有前缀,从第二个开始
for(i=1;i<10;i++) {
buckets[i] += buckets[i-1];
}
//反向遍历
for(i=a.length-1;i>=0;i--) {
output[buckets[(a[i]/exp)%10]-1] = a[i];
buckets[(a[i]/exp)%10]--;
}
for(i=0;i<a.length;i++)
a[i] = output[i];
}
public static void RadixSort(int []a) {
int max = get_max(a);
int exp;
for(exp=1;(max/exp)%10>0;exp*=10) {
count_sort(a,exp);
}
}
借鉴博客:https://www.cnblogs.com/sun-haiyu/p/7859252.html
https://www.cnblogs.com/lizr-ithouse/p/5839384.html
https://www.cnblogs.com/guoyaohua/p/8600214.html
排序算法以及其java实现的更多相关文章
- 排序算法总结(基于Java实现)
前言 下面会讲到一些简单的排序算法(均基于java实现),并给出实现和效率分析. 使用的基类如下: 注意:抽象函数应为public的,我就不改代码了 public abstract class Sor ...
- 常见排序算法题(java版)
常见排序算法题(java版) //插入排序: package org.rut.util.algorithm.support; import org.rut.util.algorithm.Sor ...
- 八大排序算法总结与java实现(转)
八大排序算法总结与Java实现 原文链接: 八大排序算法总结与java实现 - iTimeTraveler 概述 直接插入排序 希尔排序 简单选择排序 堆排序 冒泡排序 快速排序 归并排序 基数排序 ...
- 第二章:排序算法 及其他 Java代码实现
目录 第二章:排序算法 及其他 Java代码实现 插入排序 归并排序 选择排序算法 冒泡排序 查找算法 习题 2.3.7 第二章:排序算法 及其他 Java代码实现 --算法导论(Introducti ...
- 排序算法总结及Java实现
1. 整体介绍 分类 排序大的分类可以分为两种,内排序和外排序.在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序.主要需要理解的都是内排序算法: 内排序可以分为 ...
- 常见排序算法总结(java版)
一.冒泡排序 1.原理:相邻元素两两比较,大的往后放.第一次完毕,最大值在最大索引处. 即使用相邻的两个元素一次比价,依次将最大的数放到最后. 2.代码: public static void bub ...
- 排序算法之冒泡排序Java实现
排序算法之冒泡排序 舞蹈演示排序: 冒泡排序: http://t.cn/hrf58M 希尔排序:http://t.cn/hrosvb 选择排序:http://t.cn/hros6e 插入排序:ht ...
- 动画展现十大经典排序算法(附Java代码)
0.算法概述 0.1 算法分类 十种常见排序算法可以分为两大类: 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序. 非比较类排序: ...
- 排序算法大汇总 Java实现
一.插入类算法 排序算法的稳定性:两个大小相等的元素排序前后的相对位置不变.{31,32,2} 排序后{2,31,32},则称排序算法稳定 通用类: public class Common { pub ...
- 排序算法代码实现-Java
前言 为了准备面试,从2月开始将排序算法认认真真得刷了一遍,通过看书看视频,实践打代码,还有一部分的leetcode题,自己感觉也有点进步,将笔记记录总结发出来. 冒泡排序 该排序就是一种像泡泡浮到水 ...
随机推荐
- Bubble Babble Binary Data Encoding的简介以及bubblepy的安装使用方法
Bubble Babble Binary Data Encoding是由Antti Huima创建的一种编码方法,可以把二进制信息表示为由交替的元音和辅音组成的伪词(pseudo-words),主要用 ...
- webservice调用和生成
webservice简介: Web Service技术, 能使得运行在不同机器上的不同应用无须借助附加的.专门的第三方软件或硬件, 就可相互交换数据或集成.依据Web Service规范实施的应用之间 ...
- 646. Maximum Length of Pair Chain(medium)
You are given n pairs of numbers. In every pair, the first number is always smaller than the second ...
- Solving the Top ERP and CRM Metadata Challenges with erwin & Silwood
Registrationhttps://register.gotowebinar.com/register/3486582555108619010 Solving the Top ERP and CR ...
- Linux operating system basic knowleadge
1.Linux目录系统结构 It makes sense to explore the Linux filesystem from a terminal window. In fact, that ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):1. 自定义窗口部件 (widget)
1. 框架代码 用 PyCharm 新建一个名为 SimplePaintApp 的项目,然后新建一个名为 simple_paint_app.py 的 Python 源文件, 在代码编辑器中,输入以下框 ...
- SpringCloud学习笔记:熔断器Hystrix(5)
1. Hystrix简介 在分布式系统中,服务与服务之间相互依赖,一种不可避免的情况是某些服务会出现故障,导致依赖于它们的其他服务出现远程调度的线程阻塞. Hystrix提供熔断器功能,能够阻止分布式 ...
- 18.flannel的配置
Kubernetes网络通信: (1) 容器间通信:同一个Pod内的多个容器间的通信, lo (2) Pod通信:Pod IP <--> Pod IP (3) Pod与Service通信: ...
- 【Machine Translation】CMU的NMT教程论文:最全面的神经机器翻译学习教程
这是一篇CMU发的神经机器翻译教程论文,很全很详细,适合新手阅读,即使没有什么MT.DNN.RNN的基础知识. 另外它还配套了CMU自己的一个框架DyNet的练习. 全文共9章,从统计语言模型到DNN ...
- Transaction check error: file /etc/rpm/macros.ghc-srpm from install of redhat-rpm-config-9.1.0-80.el7.centos.noarch conflicts with file from package epel-release-6-8.noarch Error Summary ----------
./certbot-auto certonly 报错: Transaction check error: file /etc/rpm/macros.ghc-srpm from install of ...