hadoop生态之mapReduce-Yarn
一、inputSplit
1.什么是block
块是以 block size 进行划分数据。 因此,如果群集中的 block size 为 128 MB,则数据集的每个块将为 128 MB,除非最后一个块小于block size(文件大小不能被 block size 完全整除)。例如下图中文件大小为513MB,513%128=1,最后一个块(e)小于block size,大小为1MB。 因此,块是以 block size 的硬切割,并且块甚至可以在逻辑记录结束之前结束(blocks can end even before a logical record ends)。
假设我们的集群中block size 是128 MB,每个逻辑记录大约100 MB(假设为巨大的记录)。所以第一个记录将完全在一个块中,因为记录大小为100 MB小于块大小128 MB。但是,第二个记录不能完全在一个块中,因此第二条记录将出现在两个块中,从块1开始,在块2中结束
2.什么是inputSplit
如果分配一个Mapper给块1,在这种情况下,Mapper不能处理第二条记录,因为块1中没有完整第二条记录。因为HDFS不知道文件块中的内容,它不知道记录会什么时候可能溢出到另一个块(because HDFS has no conception of what’s inside the file blocks, it can’t gauge when a record might spill over into another block)。InputSplit这是解决这种跨越块边界的那些记录问题,Hadoop使用逻辑表示存储在文件块中的数据,称为输入拆分(InputSplit)。
当MapReduce作业客户端计算InputSplit时,它会计算出块中第一个完整记录的开始位置和最后一个记录的结束位置。在最后一个记录不完整的情况下,InputSplit 包括下一个块的位置信息和完成该记录所需的数据的字节偏移(In cases where the last record in a block is incomplete, the input split includes location information for the next block and the byte offset of the data needed to complete the record)。下图显示了数据块和InputSplit之间的关系:
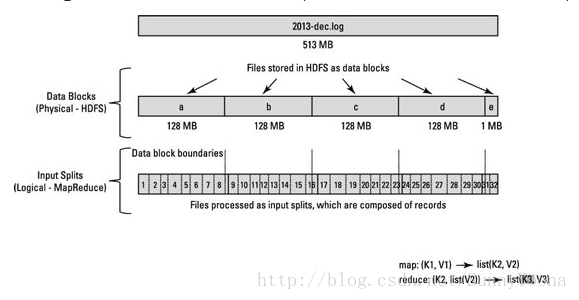
块是磁盘中的数据存储的物理块,其中InputSplit不是物理数据块。 它是一个Java类,指向块中的开始和结束位置。 因此,当Mapper尝试读取数据时,它清楚地知道从何处开始读取以及在哪里停止读取。 InputSplit的开始位置可以在块中开始,在另一个块中结束。InputSplit代表了逻辑记录边界,在MapReduce执行期间,Hadoop扫描块并创建InputSplits,并且每个InputSplit将被分配给一个Mapper进行处理。
hadoop生态之mapReduce-Yarn的更多相关文章
- Hadoop生态集群YARN详解
一,前言 Hadoop 2.0由三个子系统组成,分别是HDFS.YARN和MapReduce,其中,YARN是一个崭新的资源管理系统,而MapReduce则只是运行在YARN上的一个应用,如果把YAR ...
- Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现. (1)0.20.0~0.20.2: Hadoop的0.20分支非常稳定,虽然看起来有些落后,但是经过生产环境考验,是 Hadoop历史上 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop生态常用数据模型
Hadoop生态常用数据模型 一.TextFile 二.SequenceFile 1.特性 2.存储结构 3.压缩结构与读取过程 4.读写操作 三.Avro 1.特性 2.数据类型 3.avro-to ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- 每天收获一点点------Hadoop之初始MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
随机推荐
- 基于GitLab的Code Review教程
一.前言 1.本文主要内容 GitLab Code Review机制说明 Git Workflow 与 Git Code Review Workflow GitLab Code Review 配置说明 ...
- 经典51道SQL查询练习题
数据表介绍 --1.学生表 Student(SId,Sname,Sage,Ssex) --SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 --2.课程表 Course( ...
- Cannot read property 'validate' of undefined
在使用element-UI表单验证中一直报错,'Error in event handler for “click”: “TypeError: Cannot read property ‘valida ...
- .Net Core 在Linux服务器下部署程序--(1). Windows 连接 Linux服务器
下载Linux服务器连接软件,市面上有Putty,FinalShell等,我以FinalShell为例,下载地址为 :http://www.hostbuf.com/t/988.html,软件安装结束后 ...
- Python入门测试
1.比如自然数10以下能被3或者5整除的有,3,5,6和9,那么这些数字的和为23. 求能被3或者5整除的1000以内数字的和 multiple_of_threes=[] for multiple_o ...
- Windows下查看硬连接引用技术
Win10有了bash,可以方便的进入并用ll查看文件的硬连接数. 但是用powershell直接查看就比较麻烦了,比较曲折的找到了方法: fsutil hardlink list [filename ...
- (light oj 1102) Problem Makes Problem (组合数 + 乘法逆元)
题目链接:http://lightoj.com/volume_showproblem.php?problem=1102 As I am fond of making easier problems, ...
- 菜鸟学python之程序初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2684 1.字符串操作: 解析身份证号:生日.性别.出生地等. def id ...
- beanshell断言模版
if("${createTime_1}".equals("${createTime_2}")){ Failure = false; FailureMessage ...
- ArrayList循环遍历并删除元素的几种情况
如下代码,想要循环删除列表中的元素b,该怎么处理? public class ListDemo { public static void main(String[] args) { ArrayList ...