皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)
Pearson's r,称为皮尔逊相关系数(Pearson correlation coefficient),用来反映两个随机变量之间的线性相关程度。
用于总体(population)时记作ρ (rho)(population correlation coefficient):
给定两个随机变量X,Y,ρ的公式为:

其中: 


用于样本(sample)时记作r(sample correlation coefficient):
给定两个随机变量x,y,r的公式为:

其中: 



r的取值在-1与1之间。取值为1时,表示两个随机变量之间呈完全正相关关系;取值为-1时,表示两个随机变量之间呈完全负相关关系;取值为0时,表示两个随机变量之间线性无关。
(注:我们用样本相关系数r作为总体相关系数ρ的估计值,要判断r值是不是由抽样误差或偶然因素导致的,需要进行假设检验。)
那么皮尔逊相关系数是怎么得来的呢?(参考:https://blog.csdn.net/ichuzhen/article/details/79535226)
要理解皮尔逊相关系数,首先要理解协方差(Covariance)
。协方差可以反映两个随机变量之间的关系,如果一个变量跟随着另一个变量一起变大或者变小,那么这两个变量的协方差就是正值,就表示这两个变量之间呈正相关关系,反之相反。协方差的公式如下:
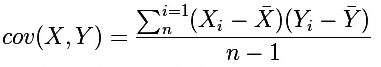
如果协方差的值是个很大的正数,我们可以得到两个可能的结论:
(1) 两个变量之间呈很强的正相关性
(2) 两个变量之间并没有很强的正相关性,协方差的值很大是因为X或Y的标准差很大
那么到底哪个结论正确呢?只要把X和Y变量的标准差,从协方差中剔除不就知道了吗?协方差能告诉我们两个随机变量之间的关系,但是却没法衡量变量之间相关性的强弱。因此,为了更好地度量两个随机变量之间的相关程度,引入了皮尔逊相关系数。可以看到,皮尔逊相关系数就是用协方差除以两个变量的标准差得到的。
皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)的更多相关文章
- 皮尔逊相关系数与余弦相似度(Pearson Correlation Coefficient & Cosine Similarity)
之前<皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)>一文介绍了皮尔逊相关系数.那么,皮尔逊相关系数(Pearson Corre ...
- 【ML基础】皮尔森相关系数(Pearson correlation coefficient)
前言 参考 1. 皮尔森相关系数(Pearson correlation coefficient): 完
- [Statistics] Comparison of Three Correlation Coefficient: Pearson, Kendall, Spearman
There are three popular metrics to measure the correlation between two random variables: Pearson's c ...
- PCC值average pearson correlation coefficient计算方法
1.先找到task paradise 的m1-m6: 2.根据公式Dy=D1* 1/P*∑aT ,例如 D :t*k1 a:k2*k1: Dy :t*k2 Dy应该有k2个原子,维度是t: 3.依 ...
- Pearson product-moment correlation coefficient in java(java的简单相关系数算法)
一.什么是Pearson product-moment correlation coefficient(简单相关系数)? 相关表和相关图可反映两个变量之间的相互关系及其相关方向,但无法确切地表明两个变 ...
- Pearson Correlation Score
[http://www.statisticshowto.com/what-is-the-pearson-correlation-coefficient/] Correlation between se ...
- Python 余弦相似度与皮尔逊相关系数 计算
夹角余弦(Cosine) 也可以叫余弦相似度. 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异. (1)在二维空间中向量A(x1,y1)与向量B(x2,y2 ...
- 协同过滤算法中皮尔逊相关系数的计算 C++
template <class T1, class T2>double Pearson(std::vector<T1> &inst1, std::vector<T ...
- 斯皮尔曼等级相关(Spearman’s correlation coefficient for ranked data)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
随机推荐
- BIM特点及格式文件说明
BIM行业是建筑与IT结合而形成的一个新兴行业,既然能说是行业,说明它包含的内容非常丰富,懂一点和完全懂是两码事,就好像一滴水和一片大海的范围一样.现在国内有很多高校开设了BIM专业,并对口招收了学生 ...
- 环境设置——pyCharm环境下导入MySQLdb遇到的一系列问题
本文转自http://blog.sina.com.cn/s/blog_135031dae0102yc8l.html 安装好pyCharm后想要import MySQL,结果发现了一系列问题,像推到了塔 ...
- Android系统的三种分屏显示模式
Google在Android 7.0中引入了一个新特性——多窗口支持,允许用户一次在屏幕上打开两个应用.在手持设备上,两个应用可以在"分屏"模式中左右并排或上下并排显示.在电视设备 ...
- Linux压缩打包tar命令总结
命令简介 在Linux系统的维护.管理中,tar命令是一个使用频率很高的命令,tar命令的功能主要是将众多文件打包成一个tar文件并压缩,并且能保持文件的权限属性.tar其实最开始是用来做磁带 ...
- [20190402]对比_mutex_wait_scheme不同模式cpu消耗.txt
[20190402]对比_mutex_wait_scheme不同模式cpu消耗.txt --//前几天做了sql语句在mutexes上的探究.今天对比不同_mutex_wait_scheme模式cpu ...
- Linux Mysql数据库安全配置
Linux Mysql数据库安全配置 目录: 1.修改mysql管理员账号root的密码(2种方法) 2.修改mysql管理员账号root 3.mysql管理员root账号密码遗忘解决办法(2种方法 ...
- java每日一总结
一, 1.安装jdk时路径中不能有空格或者中文. 二, 1.进入文件夹:cd+文件夹名称. 2.进入多级文件夹:cd+文件夹1\文件夹2\文件夹3. 3.返回上一级:cd 空格+... 4.返回根路径 ...
- SQL MID() 函数
MID() 函数 MID 函数用于从文本字段中提取字符. SQL MID() 语法 SELECT MID(column_name,start[,length]) FROM table_name 参数 ...
- 正益移动推出新产品正益工作 实现PaaS+SaaS新组合
近期,正益移动不仅将其AppCan 移动平台云化,还通过发布全新 SaaS 产品 -- 正益工作,这款集合了企业信息聚合.应用聚合.社交聚合为一体的企业移动综合门户,与 AppCan 平台一起实现了P ...
- 两台主机,ssh端口不同,如何拷贝文件
A主机ip:172.26.225.199 ssh端口12995 B主机ip:172.26.225.200 ssh端口12991 将B主机的文件拷贝到A主机 [root@test2019030517 s ...