ElasticSearch 索引 剖析
ElasticSearch 写操作 剖析
在看ElasticSearch权威指南基础入门中关于:分片内部原理这一小节内容后,大致对ElasticSearch的索引、搜索底层实现有了一个初步的认识。记录一下在看文档的过程中碰到的问题以及我的理解。此外,在文章的末尾,还讨论分布式系统中的主从复制原理,以及采用这种副本复制方案带来的数据一致性问题。
ElasticSearch index 操作背后发生了什么?
更具体地,就是执行PUT操作向ElasticSearch添加一篇文档时,底层发生的一系列操作。
PUT user/profile/10
{
"content":"向user索引中添加一篇id为10的文档"
}
通过PUT请求发起了索引新文档的操作,该操作能够执行的前提是:集群中有“一定数量”的活跃 shards。这个配置由wait_for_active_shards指定。ElasticSearch关于分片有2个重要的概念:primary shard 和 replica。在定义索引的时候指定索引有几个主分片,以及每个主分片有多少个副本。比如:
PUT user
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},

介绍一下集群的环境:ElasticSearch6.3.2三节点集群。定义了一个user索引,该索引有三个主分片,每个主分片2个副本。如图,每个节点上有三个shards:一个 primary shard,二个replica
wait_for_active_shards
To improve the resiliency of writes to the system, indexing operations can be configured to wait for a certain number of active shard copies before proceeding with the operation. If the requisite number of active shard copies are not available, then the write operation must wait and retry, until either the requisite shard copies have started or a timeout occurs.
在索引一篇文档时,通过wait_for_active_shards指定有多少个活跃的shards时,才能执行索引文档的操作。默认情况下,只要primary shard 是活跃的就可以索引文档。即wait_for_active_shards值为1
By default, write operations only wait for the primary shards to be active before proceeding (i.e.
wait_for_active_shards=1)
来验证一下:在只有一台节点的ElasticSearch上:三个primary shard 全部分配在一台节点中,并且存在着未分配的replica
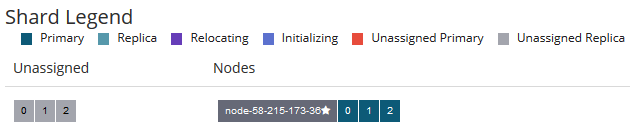
执行:
PUT user/profile/10
{
"content":"向user索引中添加一篇id为10的文档"
}
返回结果:
{
"_index": "user",
"_type": "profile",
"_id": "10",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
在_shards 中,total 为3,说明该索引操作应该在3个(一个primary shard,二个replica)分片中执行成功;但是successful为1 说明 PUT操作 在其中一个分片中执行成功了,就返回给client索引成功的确认。这个分片就是primary shard,因为只有一台节点,另外2个replica 属于 unassigned shards,不可能在2个replica 中执行成功。总之,默认情况下,只要primary shard 是活跃的,就能索引文档(index操作)
现在在单节点的集群上,修改索引配置为:wait_for_active_shards=2,这意味着一个索引操作至少要在2个分片上执行成功,才能返回给client acknowledge。
"settings": {
"index.write.wait_for_active_shards": "2"
}
再次向user索引中PUT 一篇文档:
PUT user/profile/10
{
"content":"向user索引中添加一篇id为10的文档"
}
返回结果:
{
"statusCode": 504,
"error": "Gateway Time-out",
"message": "Client request timeout"
}
由于是单节点的ElasticSearch,另外的2个replica无法分配,因此不可能是活跃的。而我们指定的wait_for_active_shards为2,但现在只有primary shard是活跃的,还差一个replica,因此无法进行索引操作了。
The primary shard assigned to perform the index operation might not be available when the index operation is executed. Some reasons for this might be that the primary shard is currently recovering from a gateway or undergoing relocation. By default, the index operation will wait on the primary shard to become available for up to 1 minute before failing and responding with an error.
索引操作会在1分钟之后超时。再看创建索引的org.elasticsearch.cluster.metadata.MetaDataCreateIndexService源代码涉及到两个参数:一个是wait_for_active_shards,另一个是ackTimeout,就好理解了。
public void createIndex(final CreateIndexClusterStateUpdateRequest request,
final ActionListener<CreateIndexClusterStateUpdateResponse> listener) {
onlyCreateIndex(request, ActionListener.wrap(response -> {
if (response.isAcknowledged()) {
activeShardsObserver.waitForActiveShards(new String[]{request.index()}, request.waitForActiveShards(), request.ackTimeout(),
shardsAcknowledged -> {
if (shardsAcknowledged == false) {
logger.debug("[{}] index created, but the operation timed out while waiting for " +
"enough shards to be started.", request.index());
}
总结一下:由于文档最终是存在在某个ElasticSearch shard下面的,而每个shard又设置了副本数。默认情况下,在进行索引文档操作时,ElasticSearch会检查活跃的分片数量是否达到wait_for_active_shards设置的值。若未达到,则索引操作会超时,超时时间为1分钟。另外,值得注意的是:检查活跃分片数量只是在开始索引数据的时候检查,若检查通过后,在索引文档的过程中,集群中又有分片因为某些原因挂掉了,那么并不能保证这个文档一定写入到 wait_for_active_shards 个分片中去了 。
因为索引文档操作(也即写操作)发生在 检查活跃分片数量 操作之后。试想以下几个问题:
- 问题1:检查活跃分片数量满足
wait_for_active_shards设置的值之后,在持续 bulk index 文档过程中有 shard 失效了(这里的shard是replica),那 难道不能继续索引文档了? - 问题2:在什么时候检查集群中的活跃分片数量?难道要 每次client发送索引文档请求时就要检查一次吗?还是说周期性地隔多久检查一次?
- 问题3:这里的 check-then-act 并不是原子操作,因此
wait_for_active_shards这个配置参数又有多大的意义?
因此,官方文档中是这么说的:
It is important to note that this setting greatly reduces the chances of the write operation not writing to the requisite number of shard copies, but it does not completely eliminate the possibility, because this check occurs before the write operation commences. Once the write operation is underway, it is still possible for replication to fail on any number of shard copies but still succeed on the primary.
- 该参数只是尽可能地保证新文档能够写入到我们所要求的shard数量中(reduce the chance of ....)。比如:
wait_for_active_shards设置为2,那也只是尽可能地保证将新文档写入了2个shard中,当然一个是primary shard,另外一个是某个replica - check 操作发生在 write操作之前,某个doc的写操作check actives shard发现符合要求,但check完之后,某个replica挂了,只要不是primary shard,那该doc的写操作还是会继续进行。但是在返回给用户响应中,会标识出有多少个分片失败了。实际上,ES索引一篇文档时,是要求primary shard写入该文档,然后primary shard将文件并行转发给所有的replica,当所有的replica都"写入"之后,给primary shard响应,primary shard才返回ACK给client。从这里可看出,需要等到primary shard以及所有的replica都写入文档之后,client才能收到响应。那么,
wait_for_active_shards这个参数的意义何在呢?我的理解是:这个参数只是"尽可能"保证doc写入到所有的分片,如果活跃的分片数量未达到wait_for_active_shards,那么写是不允许的,而达到了之后,才允许写,而又由于check-then-act并不是原子操作,并不能保证doc一定是成功地写入到wait_for_active_shards个分片中去了。(总之,在正常情况下,ES client 写请求一篇doc时,该doc在primary shard上写入,然后并行转发给各个replica,在各个replica上也执行写完成(这里的完成有可能是成功,也有可能是失败),primary shard收到各个replica写完成的响应,才返回响应给ES client。参考这篇文章)
最后,说一下wait_for_active_shards参数的取值:可以设置成 all 或者是 1到 number_of_replicas+1 之间的任何一个整数。
Valid values are
allor any positive integer up to the total number of configured copies per shard in the index (which isnumber_of_replicas+1)
number_of_replicas 为索引指定的副本的数量,加1是指:再算上primary shard。比如前面user索引的副本数量为2,那么wait_for_active_shards最多设置为3。
好,前面讨论完了ElasticSearch能够执行索引操作(写操作)了,接下来是在写操作过程中发生了什么?比如说ElasticSearch是如何做到近实时搜索的?在将文档写入ElasticSearch时候发生了故障,那文档会不会丢失?
由于ElasticSearch底层是Lucene,在将一篇文档写入ElasticSearch,并最终能被Client查询到,涉及到以下几个概念:倒排索引、Lucene段、提交点、translog、ElasticSearch分片。这里概念都是参考《ElasticSearch definitive guide》中相关的描述。
In Elasticsearch, the most basic unit of storage of data is a shard. But, looking through the Lucene lens makes things a bit different. Here, each Elasticsearch shard is a Lucene index, and each Lucene index consists of several Lucene segments. A segment is an inverted index of the mapping of terms to the documents containing those terms.
它们之间的关系示意图如下:
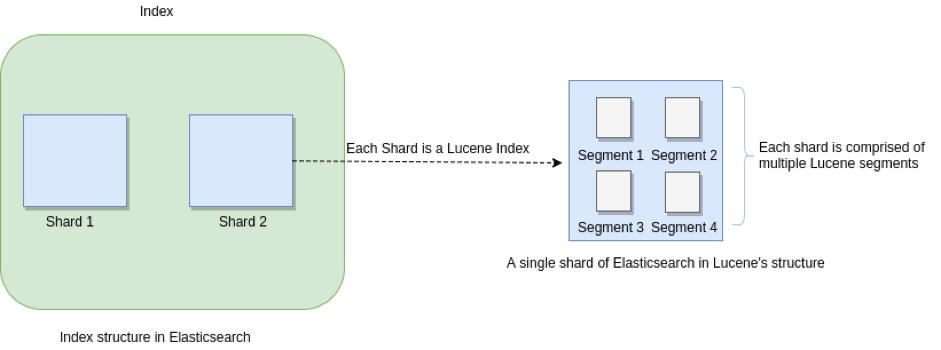
一个ElasticSearch 索引可由多个 primary shard组成,每个primary shard相当于一个Lucene Index;一个Lucene index 由多个Segment组成,每个Segment是一个倒排索引结构表
从文档的角度来看:文章会被analyze(比如分词),然后放到倒排索引(posting list)中。倒排索引之于ElasticSearch就相当于B+树之于Mysql,是存储引擎底层的存储结构。
当文档写入ElasticSearch时,文档首先被保存在内存索引缓存中(in-memeory indexing buffer)。而in-memory buffer是每隔1秒钟刷新一次,刷新成一个个的可搜索的段(file system cache)--下图中的绿色圆柱表示(segment),然后这些段是每隔30分钟同步到磁盘中持久化存储,段同步到磁盘的过程称为 提交 commit。(这里要注意区分内存中2个不同的区域:一个是 indexing buffer,另一个是file system cache。写入indexing buffer中的文档 经过 refresh 变成 file system cache中的segments,从而搜索可见)
But the new segment is written to the filesystem cache first—which is cheap—and only later is it flushed to disk—which is expensive. But once a file is in the cache, it can be opened and read, just like any other file.
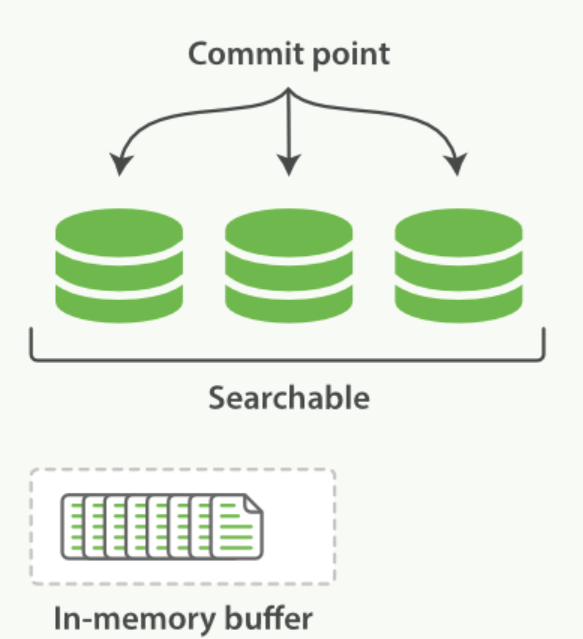
在这里涉及到了两个过程:① In-memory buffer中的文档被刷新成段;②段提交 同步到磁盘 持久化存储。
过程①默认是1秒钟1次,而我们所说的ElasticSearch是提供了近实时搜索,指的是:文档的变化并不是立即对搜索可见,但会在一秒之后变为可见,一秒钟之后,我们写入的文档就可以被搜索到了,就是因为这个原因。另外ElasticSearch提供了 refresh API 来控制过程①。refresh操作强制把In-memory buffer中的内容刷新成段。refresh示意图如下:

比如说,你可以在每次index一篇文档之后就调用一次refresh API,也即:每索引一篇文档就强制刷新生成一个段,这会导致系统中存在大量的小段,由于一次搜索需要查找所有的segments,因此大量的小段会影响搜索性能;此外,大量的小段也意味着OS打开了大量的文件描述符,在一定程度上影响系统资源消耗。这也是为什么ElasticSearch/Lucene提供了段合并操作的原因,因为不管是1s一次refresh,还是每次索引一篇文档时手动执行refresh,都可能导致大量的小段(small segment)产生,大量的小段是会影响性能的。
此外,当我们讨论segments时,该segment既可以是已提交的,也可以是未提交的segment。所谓已提交的segment,就是这些segment是已经fsync到磁盘上持久化存储了的,由于已提交的segments已经持久化了,那么它们对应的translog日志也可以删除了。而未提交的segments中包含的文档是搜索可见的,但是如果宕机,就可能导致未提交的segments包含的文档丢失了,此时可以从translog恢复。
对于过程②,就是将段刷新到磁盘中去,默认是每隔30分钟一次,这个刷新过程称为提交。如果还未来得及提交时,发生了故障,那岂不是会丢失大量的文档数据?这个时候,就引入了translog
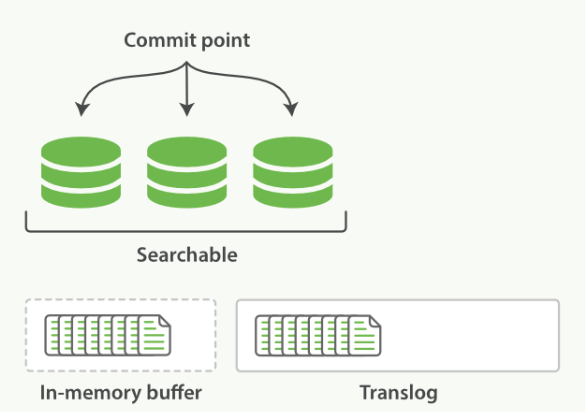
每篇文档写入到In-memroy buffer中时,同时也会向 translog中写一条记录。In-memory buffer 每秒刷新一次,刷新后生成新段,in-memory被清空,文档可以被搜索。
而translog 默认是每5秒钟刷新一次到磁盘,或者是在每次请求(index、delete、update、bulk)之后就刷新到磁盘。每5秒钟刷新一次就是异步刷新,可以通过如下方式开启:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
这种方式的话,还是有可能会丢失文档数据,比如Client发起index操作之后,ElasticSearch返回了200响应,但是由于translog要等5秒钟之后才刷新到磁盘,如果在5秒内系统宕机了,那么这几秒钟内写入的文档数据就丢失了。
而在每次请求操作(index、delete、update、bulk)执行后就刷新translog到磁盘,则是translog同步刷新,比如说:当Client PUT一个文档:
PUT user/profile/10
{
"content":"向user索引中添加一篇id为10的文档"
}
在前面提到的三节点ElasticSearch集群中,该user索引有三个primary shard,每个primary shard2个replica,那么translog需要在某个primary shard中刷新成功,并且在该primary shard的两个replica中也刷新成功,才会给Client返回 200 PUT成功响应。这种方式就保证了,只要Client接收到的响应是200,就意味着该文档一定是成功索引到ElasticSearch中去了。因为translog是成功持久化到磁盘之后,再给Client响应的,系统宕机后在下一次重启ElasticSearch时,就会读取translog进行恢复。
By default, Elasticsearch
fsyncs and commits the translog every 5 seconds ifindex.translog.durabilityis set toasyncor if set torequest(default) at the end of every index, delete, update, or bulk request. More precisely, if set torequest, Elasticsearch will only report success of an index, delete, update, or bulk request to the client after the translog has been successfullyfsynced and committed on the primary and on every allocated replica.
这也是为什么,在我们关闭ElasticSearch时最好进行一次flush操作,将段刷新到磁盘中。因为这样会清空translog,那么在重启ElasticSearch就会很快(不需要恢复大量的translog了)
translog 也被用来提供实时 CRUD 。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
放一张总结性的图,如下:
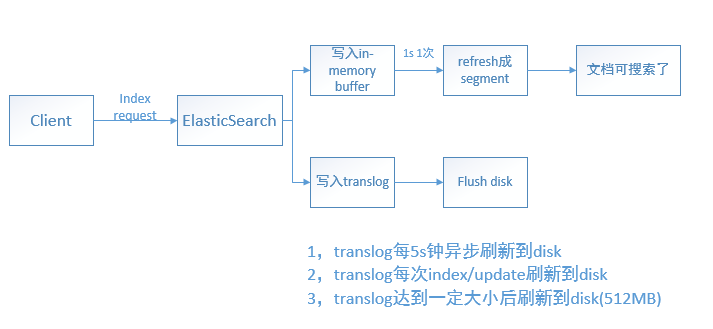
有个问题是:为什么translog可以在每次请求之后刷新到磁盘?难道不会影响性能吗?相比于将 段(segment)刷新到磁盘,刷新translog的代价是要小得多的,因为translog是经过精心设计的数据结构,而段(segment)是用于搜索的"倒排索引",我们无法做到每次将段刷新到磁盘;而刷新translog相比于段要轻量级得多(translog 可做到顺序写disk,并且数据结构比segment要简单),因此通过translog机制来保证数据不丢失又不太影响写入性能。
Changes to Lucene are only persisted to disk during a Lucene commit, which is a relatively expensive operation and so cannot be performed after every index or delete operation.
......
All index and delete operations are written to the translog after being processed by the internal Lucene index but before they are acknowledged. In the event of a crash, recent transactions that have been acknowledged but not yet included in the last Lucene commit can instead be recovered from the translog when the shard recovers.
如果宕机,那些 已经返回给client确认但尚未 lucene commit 持久化到disk的transactions,可以从translog中恢复。
总结一下:
这里一共有三个地方有“刷新操作”,其中 refresh 的应用场景是每个Index/Update/Delete 单个操作之后,要不要refresh一下?而flush 是针对索引而言的:要不要对 twitter 这个索引 flush 一下,使得在内存中的数据是否已经持久化到磁盘上了,这里会引发Lucene的commit,当这些数据持久化磁盘上后,相应的translog就可以删除了(因为这些数据已经持久化到磁盘,那就是可靠的了,如果发生意外宕机,需要借助translog恢复的是那些尚未来得及flush到磁盘上的索引数据)
in-memory buffer 刷新 生成segment
每秒一次,文档刷新成segment就可以被搜索到了,ElasticSearch提供了refresh API 来控制这个过程
translog 刷新到磁盘
由
index.translog.durability来设置,或者由index.translog.flush_threshold_size来设置当translog达到一定大小之后刷新到磁盘(默认512MB)段(segment) 刷新到磁盘(flush)
每30分钟一次,ElasticSearch提供了flush API 来控制这个过程。在段被刷新到磁盘(就是通常所说的commit操作)中时,也会清空刷新translog。
写操作的可靠性如何保证?
数据的可靠性保证是理解存储系统差异的重要方面。比如说,要对比MySQL与ES的异同、对比ES与redis的区别,就可以从数据的可靠性这个点入手。在MySQL里面有redo log、基于 bin log的主从复制、有double write等机制,那ES的数据可靠性保证又是如何实现的呢?
我认为在分布式系统中讨论数据可靠性需要从二个角度出发:单个副本数据的本地刷盘策略 和 写多个副本的之后何时向client返回响应 也即 同步复制、异步复制的问题。
1 单个副本数据的本地刷盘策略
在ES中,这个策略叫translog机制。当向ES索引一篇doc时,doc先写入in-memory buffer,同时写入translog。translog可配置成每次写入之后,就flush disk。这与MySQL写redo log日志的的原理是类似的。2 写多个副本的之后何时向client返回响应
这里涉及到参数wait_for_active_shards,前面提到这个参数虽有一些"缺陷"(check-then-act),但它还是尽可能地保证一篇doc在写入primary shard并且也"写入"(写入并不代表落盘)了若干个replica之后,才返回ack给client。ES中的 wait_for_active_shards参数与Kafka中 broker配置 min.insync.replicas 原理是类似的。
存在的一些问题
这个 issue 和 这个 issue 讨论了index.write.wait_for_active_shards参数的来龙去脉。
以三节点ElasticSearch6.3.2集群,索引设置为3个primary shard,每个primary shard 有2个replica 来讨论:
- client向其中一个节点发起Index操作索引文档,这个写操作请求当然是发送到primary shard上,但是当Client收到200响应时,该文档是否已经复制到另外2个replica上?
- Client将一篇文档成功写入到ElasticSearch了(收到了200响应),它能在replica所在的节点上 GET 到这篇文档吗?Client发起查询请求,又能查询到这篇文档吗?(注意:GET 和 Query 是不一样的)
- 前面提到,当 index 一篇文档时,primary shard 和2个replica 上的translog 要 都刷新 到磁盘,才返回 200 响应,那它是否与参数
index.write.wait_for_active_shards默认值 矛盾?因为index.write.wait_for_active_shards默认值为1,即:只要primary shard 是活跃的,就可以进行 index 操作。也就是说:当Client收到200的index成功响应,此时primary shard 已经将文档 复制 到2个replica 上了吗?这两个 replica 已经将文档刷新成 segment了吗?还是说这两个 replica 仅仅只是 将索引该文档的 translog 刷新到磁盘上了?
ElasticSearch副本复制方式讨论
ElasticSearch索引是一个逻辑概念,囊括现实世界中的数据。比如 定义一个 user 索引存储所有的用户资料信息。索引由若干个primary shard组成,就相当于把用户资料信息 分开成 若干个部分存储,每个primary shard存储user索引中的一部分数据。为了保证数据可靠性不丢失,可以为每个primary shard配置副本(replica)。显然,primary shard 和它对应的replica 是不会存储在同一台机器(node)上的,因为如果该机器宕机了,那么primary shard 和 副本(replica) 都会丢失,那整个系统就丢失一部分数据了。
primary shard 和 replica 这种副本备份方案,称为主从备份。primary shard是主(single leader),replica 是 从 (multiple replica)。由于是分布式环境,可能存在多个Client同时向ElasticSearch发起索引文档的请求,这篇文档会根据 文档id 哈希到某个 primary shard,primary shard写入该文档 并分发给 replica 进行存储。由于采用了哈希,这也是为什么 在定义索引的时候,需要指定primary shard个数,并且 primary shard个数一经指定后不可修改的原因。因为primary shard个数一旦改变,哈希映射 结果就变了。而采用这种主从副本备份方案,这也是为什么 索引操作(写操作、update操作) 只能由 primary shard处理,而读操作既可以从 primary shard读取,也可以从 replica 读取的原因。相对于文档而言,primary shard是single leader,所有的文档修改操作都统一由primary shard处理,能避免一些 并发修改 冲突。但是默认情况下,ElasticSearch 副本复制方式 是异步的,也正如前面 index.write.wait_for_active_shards讨论,只要primary shard 是活跃的就可以进行索引操作,primary shard 将文档 “ 存储 ” 之后,就返回给client 响应,然后primary shard 再将该文档同步给replicas,而这就是异步副本复制方式。在ElasticSearch官方讨论论坛里面,也有关于副本复制方式的讨论:这篇文章提出了一个问题:Client向primary shard写入文档成功,primary shard 是通过何种方式将该文档同步到 replica的?
其实觉得这里的 异步复制 提法 有点不准确,不过放到这里,供大家讨论参考吧
关于primary shard 将文档同步给各个replica,涉及到 in-sync replica概念,在master节点中维护了一个 in-sync 副本列表。
Since replicas can be offline, the primary is not required to replicate to all replicas. Instead, Elasticsearch maintains a list of shard copies that should receive the operation. This list is called the in-sync copies and is maintained by the master node.
当index操作发送到 primary shard时,primary shard 并行转发给 in-sync副本,等待各个in-sync副本给primary 响应。primary shard收到所有in-sync副本响应后,再给Client响应说:Index操作成功。由于副本可能会出故障,当没有in-sync副本,只有primary shard在正常工作时,此时的index操作只在primary shard上执行成功就返回给Client了,这里就存在了所谓的“单点故障”,因为primary shard所在的节点挂了,那 就会丢失 index 操作的文档了。这个时候, index.write.wait_for_active_shards 参数就起作用了,如果将 index.write.wait_for_active_shards 设置为2,那么 当没有in-sync副本,只有primary shard在正常工作时,index 操作就会被拒绝。所以,在这里,index.write.wait_for_active_shards参数起到一个避免单点故障的功能。更具体的细节可参考data-replication model
采用异步副本复制方式带来的一个问题是:读操作能读取最新写入的文档吗?如果我们指定读请求去读primary shard(通过ElasticSearch 的路由机制),那么是能读到最新数据的。但是如果读请求是由某个 replica 接收处理,那也许就不能读取到刚才最新写入的文档了。因此,从刚才Client 读请求的角度来看,ElasticSearch能提供 哪种程度的 一致性呢?而出现这种一致性问题的原因在于:为了保证数据可靠性,采用了副本备份,引入了副本,导致副本和primary shard上的数据不一致,即:存在 replication lag 问题。由于这种副本复制延迟带来的问题,系统需要给Client 某种数据一致性的 保证,比如说:
read your own write
Client能够读取到它自己最新写入的数据。比如用户修改了昵称,那TA访问自己的主页时,能看到自己修改了的昵称,但是TA的好友 可能 并不能立即看到 TA 修改后的昵称。好友请求的是某个 replica 上的数据,而 primary shard还未来得及把刚才修改的昵称 同步 到 replica上。
Monotonic reads
单调读。每次Client读取的值,是越来越新的值(站在Client角度来看的)。比如说NBA篮球比赛,Client每10分钟读一次比赛结果。第10分钟读取到的是 1:1,第20分钟读到的是2:2,第30分钟读到的是3:3,假设在第40分钟时,实际比赛结果是4:4,Cleint在第40分钟读取的时候,读到的值可以是3:3 这意味着未读取到最新结果而已,读到的值也可以是4:4, 但是不能是2:2 。
consistent prefix reads
符合因果关系的一种读操作。比如说,用户1 和 用户2 对话:
用户1:你现在干嘛?
用户2:写代码对于Client读:应该是先读取到“你现在干嘛?”,然后再读取到 “写代码。如果读取结果顺序乱了,Client就会莫名其妙。
正是由于Client 有了系统给予的这种 一致性 保证,那么Client(或者说应用程序)就能基于这种保证 来开发功能,为用户提供服务。
那系统又是如何提供这种一致性保证的呢?或者说ElasticSearch集群又提供了何种一致性保证?经常听到的有:强一致性(linearizability)、弱一致性、最终一致性。对于强一致性,通俗的理解就是:实际上数据有多份(primary shard 以及多个 replica),但在Client看来,表现得就只有一份数据。在多个 client 并发读写情形下,某个Client在修改数据A,而又有多个Client在同时读数据A,linearizability 就要保证:如果某个Client读取到了数据A,那在该Client之后的读取请求返回的结果都不能比数据A要 旧,至少是数据A的当前值(不能是数据A的旧值)。不说了,再说,我自己都不明白了。
至于系统如何提供这种一致性,会用到一些分布式共识算法,我也没有深入地去研究过。关于副本复制方式的讨论,也可参考这篇文章:分布式系统理论之Quorum机制
参考资料
原文:https://www.cnblogs.com/hapjin/p/9821073.html
ElasticSearch 索引 剖析的更多相关文章
- Elasticsearch索引(company)_Centos下CURL增删改
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.Elasticsearch索引说明 a. 通过上面几篇博客已经将Elastics ...
- ES3:ElasticSearch 索引
ElasticSearch是文档型数据库,索引(Index)定义了文档的逻辑存储和字段类型,每个索引可以包含多个文档类型,文档类型是文档的集合,文档以索引定义的逻辑存储模型,比如,指定分片和副本的数量 ...
- Elasticsearch索引和文档操作
列出所有索引 现在来看看我们的索引 GET /_cat/indices?v 响应 health status index uuid pri rep docs.count docs.deleted st ...
- Elasticsearch索引原理
转载 http://blog.csdn.net/endlu/article/details/51720299 最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计 ...
- Elasticsearch 索引、更新、删除文档
一.Elasticsearch 索引(新建)一个文档的命令: curl XPUT ' http://localhost:9200/test_es_order_index/test_es_order_t ...
- Elasticsearch 索引的全量/增量更新
Elasticsearch 索引的全量/增量更新 当你的es 索引数据从mysql 全量导入之后,如何根据其他客户端改变索引数据源带来的变动来更新 es 索引数据呢. 首先用 Python 全量生成 ...
- ElasticSearch 索引模块——全文检索
curl -XPOST http://master:9200/djt/user/3/_update -d '{"doc":{"name":"我们是中国 ...
- Elasticsearch索引按月划分以及获取所有索引数据
项目中数据库根据月份水平划分,由于没有用数据库中间件,没办法一下查询所有订单信息,所有用Elasticsearch做订单检索. Elasticsearch索引和数据库分片同步,也是根据月份来建立索引. ...
- Elasticsearch入门教程(三):Elasticsearch索引&映射
原文:Elasticsearch入门教程(三):Elasticsearch索引&映射 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文 ...
随机推荐
- 使用Visual Studio Code进行ABAP开发
长期以来,我们都使用SAP GUI进行ABAP编码工作,事务代码SE38甚至成了ABAP的代名词. SAP GUI的代码编辑能力和一些专业的IDE比较起来难免相形见绌,为了给开发者们更好的体验,SAP ...
- C# 里面swith的或者
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threa ...
- Ambari——大数据平台的搭建利器之进阶篇
前言 本文适合已经初步了解 Ambari 的读者.对 Ambari 的基础知识,以及 Ambari 的安装步骤还不清楚的读者,可以先阅读基础篇文章<Ambari——大数据平台的搭建利器>. ...
- 前端——HTML
HTML HTML叫做超文本标记语言,是一种制作万维网页面标准语言.相当于定义一套规则,大家都来遵守它,这样浏览器就可以去解释它. 浏览器负责将标签翻译成用户看得懂的格式,呈现给用户. 作为开发者需要 ...
- 使用代码生成工具Database2Sharp快速生成工作流模块控制器和视图代码
在前面随笔<基于Metronic的Bootstrap开发框架--工作流模块功能介绍>和<基于Metronic的Bootstrap开发框架--工作流模块功能介绍(2)>中介绍了B ...
- 迄今为止 .Net 平台功能最强大,性能最佳的 JSON 序列化和反序列化库。
Swifter.Json 这是迄今为止 .Net 平台功能最强大,性能最佳的 JSON 序列化和反序列化库. Github : https://github.com/Dogwei/Swifter.Js ...
- 【Swift 4.2】uuid 取 hashCode(与 Java/Go/Kotlin 一致)
extension String { func hashCode() -> Int32 { let components = self.split(separator: "-" ...
- flask token认证
在前后端分离的项目中,我们现在多半会使用token认证机制实现登录权限验证. token通常会给一个过期时间,这样即使token泄露了,危害期也只是在有效时间内,超过这个有效时间,token过期了,就 ...
- springboot打jar包正常无法访问页面
网上看到太多说版本换成 1.4.2.RELEASE. 可以将程序打成war包发布, 1.启动类改为 @Overrideprotected SpringApplicationBuilder config ...
- RPC----Hadoop核心协议
什么是RPC RPC设计的目的 RPC的作用 远程过程调用(RPC)是一个协议,程序可以使用这个协议请求网络中另一台计算机上某程序的服务而不需要知道网络细节. 必备知识: 网络七层模型 网络四层模型 ...