爬虫模块介绍--request(发送请求模块)
爬虫:可见即可爬 # 每个网站都有爬虫协议
基础爬虫需要使用到的三个模块
requests 模块 # 模拟发请求的模块
PS:python原来有两个模块urllib和urllib的升级urllib2,这两个模块使用很繁琐,后来在这两个模块上做了封装就出现了requests模块
beautifulsoup 模块 #数据解析库,re模块正则匹配解析库
senium 模块 # 控制浏览器模块
scrapy 模块 # 把上面三个模块进行一个封装,做成一个大框架,可以做分布式爬虫
requests的基本使用 # 使用 pip3 install requests
requests.get请求
requests.get方法就是帮你凑出一个http请求发送
有三个参数
url : 就是访问的地址
headers: 请求头
params : 输入的内容和页码
响应response的参数
response.text 文本内容 # 文本内容取值
response.content 二进制内容 # 如果是图片和视频就要用这个方法取值
rsponse.iter_content() # 如果一个视频或者图片文件非常大,如果一次性取值就会撑爆内存,所以要用这个iter_content,相当于for循环接收保存
response.status_code 状态码 # 用来获取状态码
response.headers 响应头 # 以字典形式
response.cookies 返回的cookie
response.cookies.get_dict() 把取到的cookie转成字典形式
response.cookies.items() 和字典的items同理
response.url 拿出要重定向的地址
response.history 拿出正常返回的数据 # 和text相同
response.encoding 返回数据的编码格式
response.apparent_encoding # 获取当前页码的编码格式
PS:现在网站都有反扒技术,所以在模拟发送请求的时候尽量的要模拟的像浏览器一样,否则容易被反扒技术拦截,就算返回200状态码,也是网站返回的假状态码
Request Headers # 这些是请求头的内容,这个直接从浏览器里面复制即可
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9
Cache-Control:max-age=0
Connection:keep-alive
'''正常的cookie写在请求头中,但是因为要经常用,所有requests模块把这个单独拿出来做了处理,请求头中最有用的一个参数就是user_session,当然也可以把整个cookie复制过来'''
Cookie:BAIDUID=8472CC0AF18E17091C3918C619E26E6D:FG=1; BIDUPSID=8472CC0AF18E17091C3918C619E26E6D; PSTM=1553224384; BD_UPN=1a314353; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_645EC=d40c8VmPu6D48Clciaof7nl3ZoeWgKbduZIrfnNW%2FgKxKTRWYmN4scXUrJA; delPer=0; BD_HOME=0; H_PS_PSSID=1462_21120_28771_28721_28557_28833_28585_28640_26350_28604
Host:www.baidu.com # 可以用来判断是不是当前的域,这个用的少
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400 # 这个是浏览器类型,包含浏览器的信息,一般在发送请求的时候都要携带这个
PS:在爬虫的时候一直失败,肯定是模拟的不够像浏览器,所以用浏览器访问一次网站,查看下请求头的内容
request的基本使用和get请求实例
import requests # 爬虫需要用到的模块,模拟发送请求 '''requests的基本使用''' # 输入中文和特殊字符需要编码
# 如果 查询关键词是中文或者是其他特殊符号,则不的不进行url编码,否则会乱码 'https://www.baidu.com/s?wd=%E8%A5%BF%E7%93%9C'这里地址内的乱码符号就是被转码后的中文或者特殊字符
# 可以from urllib.parse import urlencode #使用这个模块对输入的中文或特殊字符进行编码,但是requests自带了一个参数,param可以实现编码并且自动拼接到地址的后面 key = input('请输入需要的内容: ')
# 发送get请求有返回结果
url = 'https://www.baidu.com' # 正常的cookie写在请求头中,但是因为要经常用,所有requests模块把这个单独拿出来做了处理
cookies = {'user_session':'BAIDUID=8472CC0AF18E17091C3918C619E26E6D:FG=1; BIDUPSI'} # 反扒信息之一,要携带头信息的浏览器信息
res = requests.get(url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
# baidu的页码规律是0=1,10=2的一个10倍数的跳转,所以params里面也可以拼地址进去直接跳转到指定的页数,就是get形式携带的参数
params={'wd': key, 'pn': 70},
cookies=cookies
) # 这里将获取到的页面内容写入文件,用来验证是否成功
with open('a.html', 'w', encoding='utf-8')as f:
f.write(res.text) # 请求回来的内容,text是整个页面的内容
print(res.text) # 请求回来的状态码
print(res.status_code)
request的基本使用和post请求实例
post请求参数 # 和get请求类似
param # 输入的内容和页码
headers # 请求头
Cookie # cookie
data # 请求体的数据,默认用urlencode格式
json # 传字典,这样发送的请求编码格式是 'content-type':'application/json'
allow_redirects=False # 是否允许重定向,不写就是默认True,通常不会关闭后续操作可能会出问题
PS:先用错误的账号密码登陆,就可以在检查里看到请求发送的地址以及请求发送的数据格式 # 看图
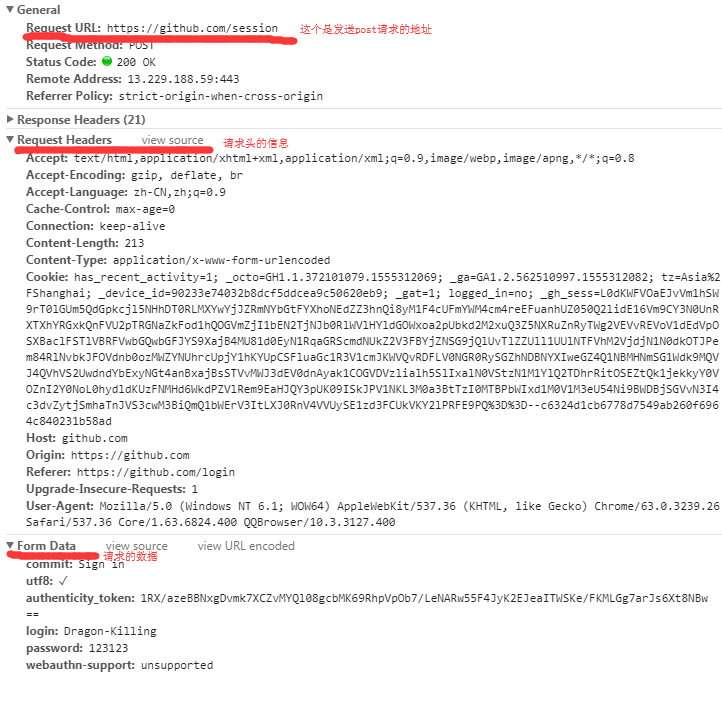
import requests, re # 第一步
res_login = requests.get('https://github.com/login') # 访问页面获得返回数据
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"',res_login.text,re.S)[0] # .*?正则表达式贪婪匹配,()是分组匹配,取出来的是一个列表,取索引位0的数据,re.S把字符串看成一行忽略字符串中的换行符
login_cookie = res_login.cookies.get_dict() # 这里获取一个没有经过认证的cookie
# 第二步
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': 'Dragon-Killing',
'password': 'Dk581588',
'webauthn-support': 'unsupported',
} # 这个就是网页里面Form Data携带的数据,就是请求体的数据 res = requests.post(url='https://github.com/session',
data=data,
# 这里也需要携带一个未认证的cookie,现在很多网站都在首次登陆时候都要求携带未认证的cookie,这也是一种反扒手段
cookies=login_cookie) # 正常登陆成功,返回cookie,下次发送请求携带者cookie
res_cookie = res.cookies.get_dict() #res是一个对象,从对象中获取cookie,然后转成字典 # 第三步
url='https://github.com/settings/emails'
res = requests.get(url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
# baidu的页码规律是0=1,10=2的一个10倍数的跳转,所以params里面也可以拼地址进去直接跳转到指定的页数,就是get形式携带的参数
cookies=res_cookie
) print('邮箱号' in res.text) # 这里判断邮箱是否在返回的数据中,成功就是True
requests模块中的session方法 # 返回一个对象,用这个方法发送get和post请求,只要网站返回的cookie,则发送请求的时候自动携带cookis,不用再手动获取然后再写入
import requests
import re session = requests.session() # 第一次发送请求
r1 = session.get('https://github.com/login')
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"',r1.text)[0] #从页面中拿到CSRT_TOKEN
print(authenticity_token) #第二次请求
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': 'Dragon-Killing',
'password': 'Dk581588',
} r2=session.post('https://github.com/session',data=data) #第三次请求
r3=session.get('https://github.com/settings/emails') print('402821597@qq.com' in r3.text)
前端往后台发送数据,有三种方式
1、urlencode # data发送数据就是默认这个格式
2、formdate # 传文件的编码
3、json # 如果后端要求发送的是json格式,就用这个格式
requests.post (url='http://xxx.com',data={'xxx':'yyy'}) # 如果没有指定请求头,则默认的请求头就是:application/x-www-form-urlencoed
# 如果定义的请求头是application/json,并且用data传值,则服务端取不到值
requests.post(url='',data={'xxx':'xxx'},headers={'content-type':'appilcation/json'}) # 这里用data传值,但是指定了json请求头,所以服务端取不到数据
request.post(url='',json={'xxx':1}) # 这里用json传值,但是没有指定请求头,则默认根据传值的类型匹配请求头,这里就是默认是application/json格式请求头
如果在爬去页面的时候发生乱码,则肯定是编码问题,通过下面实例的方式解决编码的问题
import requests
response = requests.get('http://www.autohome.com/news')
ret = response.apparent_encoding # 获取当前页码的编码格式
response.encoding=ret # 指定解码的格式
print(response.text)
对于图片和视频的爬取保存,必须是二进制形式保存,所以要用content获取二进制流保存
import requests
response = requests.get('https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=2602558426,100251765&fm=26&gp=0.jpg')
with open('a.jpg','wb')as f:
f.write(response.content)
对于很大的视频文件,一次性取值则肯定很耗费内存,则用iter_content比较合适
import requests # 这里发请求的时候一定要跟一个stream=True
response = requests.get('https://gs33.baidu.com/eer7rer7e878df7d8f7d8f.mp4',stream=True) # 这样就迭代的一行一行取值,用来爬视频
with open('a.mp4','wb')as f:
for line in response.iter_content():
f.write(line)
解析json格式的数据
import requests,json
response = requests.get('http://httpbin.org/get') #加入这里返回的格式是json格式 # res = json.loads(response.text) 用内置的方法去转换则要异步
res = response.json() # resquests实例化对象后可以直接获取json数据,就是封装了json的方法,直接转成数据原有的格式
requests模块的高级用法
SSL Cert Verification 以前大部分网站都要验证证书,需要用到这个参数
#证书验证(大部分网站都是https)
import requests
respone=requests.get('https://www.12306.cn') #如果是ssl请求,首先检查证书是否合法,不合法则报错,程序终端 #改进1:去掉报错,但是会报警告
import requests
respone=requests.get('https://www.12306.cn',verify=False) #不验证证书,报警告,返回200
print(respone.status_code) #改进2:去掉报错,并且去掉警报信息
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #关闭警告
respone=requests.get('https://www.12306.cn',verify=False)
print(respone.status_code) #改进3:加上证书
#很多网站都是https,但是不用证书也可以访问,大多数情况都是可以携带也可以不携带证书
#知乎\百度等都是可带可不带
#有硬性要求的,则必须带,比如对于定向的用户,拿到证书后才有权限访问某个特定网站
import requests
respone=requests.get('https://www.12306.cn',
cert=('/path/server.crt', # 这里是证书本地地址
'/path/key'))
print(respone.status_code)
使用ip代理
#代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情)
import requests
proxies={
'http':'http://egon:123@localhost:9743',# 带用户名密码的代理,@符号前是用户名与密码
'http':'http://localhost:9743',
'https':'https://localhost:9743',
}
respone=requests.get('https://www.12306.cn',
proxies=proxies) # 这个参数就是用代理发送 print(respone.status_code)
#支持socks代理,安装:pip install requests[socks]
import requests
proxies = {
'http': 'socks5://user:pass@host:port',
'https': 'socks5://user:pass@host:port'
}
respone=requests.get('https://www.12306.cn',
proxies=proxies) print(respone.status_code)
超时设置 # 在发送请求的时候如果时间过长没有收到回复,则要设置超时时间,否则程序会一直等待
# 两种超时:float or tuple
#timeout=0.1 # 代表接收数据的超时时间
#timeout=(0.1,0.2)#0.1代表链接超时 0.2代表接收数据的超时时间 import requests
respone=requests.get('https://www.baidu.com',
timeout=0.0001) # 这里就是设置超时时间
异常处理
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型 try:
r=requests.get('http://www.baidu.com',timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa') except RequestException:
print('Error')
上传文件 import requests
files={'file':open('a.jpg','rb')}
respone=requests.post('http://httpbin.org/post',files=files)
print(respone.status_code)
项目实例 (单线程爬取梨视频)
import requests,re '''通用通过地址获取页面的方法'''
def get_page(url):
ret = requests.get(url)
if ret.status_code == 200: # 使用status_code获取页面数据内的连接状态,通过判断返回码执行程序
return ret.text # 返回码200就是成功则将所有页面信息全部返回 '''这个用来解析地址'''
def parse_res(text):
# 使用正则匹配匹配出上面的标签中需要的字符串,urls是一个列表,就是匹配到的视频名称
urls = re.findall(r'class="categoryem".*?href="(.*?)"',text,re.S)
for url in urls:
# 循环获取到的视频名字列表列表
# 使用生成器拼接地址,只有for循环时候才会往下读一条,并且返回已读取的数据
yield 'https://www.pearvideo.com/' + url def parse_detail(text):
print(text)
# 这里用分组匹配,因为传入的是整个的页面地址,从页面中获取真实的数据地址
movie_url = re.findall('srcUrl="(.*?)"',text,re.S)[0]
print('视频文件的实际地址: ',movie_url)
return movie_url def download_movie(url):
import time
movie_content = requests.get(url)
with open(r'e:\\%s%s'%(str(time.time()),'.mp4'),'wb')as f:
f.write(movie_content.content) if __name__ == '__main__':
# 这里向页面发送get请求,获得返回信息
res = get_page('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=13')
urls = parse_res(res) # 这里将返回信息传给地址解析的函数,并且获得返回值
for url in urls:
try: # 一定要异常捕获,因为可能数据内一部分是空的,如果不捕获程序则直接奔溃
res_detail = get_page(url) # 这里for循环parse_res的返回值就是一个视频的地址传给get_page,再次访问获得页面数据
movie_url = parse_detail(res_detail) # 这里将视频的数据传入,然后通过分组获取真实的地址返回给函数
download_movie(movie_url) # 将真实的下载地址传给保存函数进行下载
except Exception as e:
print(e)
项目实例 (多线程爬取梨视频)
import requests,re
from concurrent.futures import ThreadPoolExecutor # 线程池模块 # 生成一个60个线程的线程池
pool = ThreadPoolExecutor(60) # 实例化线程池传入数字就是多少个线程 '''通用通过地址获取页面的方法'''
def get_page(url):
ret = requests.get(url)
if ret.status_code == 200: # 使用status_code获取页面数据内的连接状态,通过判断返回码执行程序
return ret.text # 返回码200就是成功则将所有页面信息全部返回 '''这个用来解析地址'''
def parse_res(text):
# add_done_callback不会直接将上个函数的返回结果传递进来,所以要用text.result()取得上个函数的返回结果
text = text.result()
#使用正则匹配匹配出上面的标签中需要的字符串,urls是一个列表,就是匹配到的视频名称
urls = re.findall(r'class="categoryem".*?href="(.*?)"',text,re.S)
for url in urls:
pool.submit(get_page,'https://www.pearvideo.com/' + url).add_done_callback(parse_detail) def parse_detail(text):
# add_done_callback不会直接将上个函数的返回结果传递进来,所以要用text.result()取得上个函数的返回结果
text = text.result()
# 这里用分组匹配,因为传入的是整个的页面地址,从页面中获取真实的数据地址
movie_url = re.findall('srcUrl="(.*?)"',text,re.S)[0]
print('真实的视频下载地址: ',movie_url)
pool.submit(download_movie,movie_url) def download_movie(url):
import time
movie_content = requests.get(url)
with open(r'e:\\%s%s'%(str(time.time()),'.mp4'),'wb')as f:
f.write(movie_content.content) if __name__ == '__main__':
for i in range(5): # 这里range用来规定页数的数字
# 开始页是0
url = 'https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=%s'%(i*12+1)
# 得到地址的f放入线程池,add_done_callback()当该线程执行完成后执行的方法这里不用传参数会默认将前面执行的结果当参数传入
pool.submit(get_page,url).add_done_callback(parse_res) # 将要执行的方法和参数传入,方法不要加()
beautifulsoup 模块实例 #数据解析库,re模块正则匹配解析库
如果复杂的网站用正则非常麻烦,所以有bs4模块可以代替正则
安装: pip3 install Beautifulsoup4
项目实例 (爬取汽车之家的新闻)
import requests,time
from bs4 import BeautifulSoup for i in range(1,10):
url = 'https://www.autohome.com.cn/news/%s/#liststart'%i
ret = requests.get(url)
print(ret.status_code) # 查看返回状态 200 # 把页面返回的所有信息放到了对象中并且指定解析库进行实例化
soup = BeautifulSoup(ret.text,'lxml') # find找出页面指定条件最近的一个,name就是指定的字符,attrs标签的属性,可以写class也可以写id,class(id):名
ul = soup.find(name='ul',attrs={'class':'article'})
# 上面把整个页面中的ul已经获取到,在ul中继续再往下找,这个写法就是找到所有ul下条件为li的元素放入列表中
li_s = ul.find_all(name='li')
# for循环获取到的所有li元素
for li in li_s:
try:
# 每次循环取a标签的herf的值,取到新闻的链接地址
news_url ='http:'+ li.find(name='a').get('href')
# 取出新闻的标题
news_title = li.find(name='h3').text
# 取出新闻的简介文本,如果li下有多个p标签,则需要用findall取出所有的p标签
news_desc = li.find(name='p').text
# 取出新闻的图片链接
news_img = 'http:' + li.find(name='img').get('src')
print(
'''
新闻标题:%s
新闻摘要:%s
新闻地址:%s
新闻图片地址:%s
'''%(news_title,news_desc,news_url,news_img)
)
# 下载新闻的图片
respons = requests.get(news_img)
with open('img/%s.jpg'%str(time.time()),'wb')as f:
f.write(respons.content)
except Exception as e:
print(e)
项目实例 (抽屉网自动点赞)
失败案例
import requests '''模拟登陆,抽屉网登陆成功是9999,不同的网站登陆状态码不同'''
ret = requests.post('https://dig.chouti.com/login',
headers={'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
data={'phone': 8615618935321,
'password': 'Seep58158',
'oneMonth': 1}) # 一个月自动登录,1就是True,0就是False # 登陆成功取出cookies
cookie = ret.cookies.get_dict() # 给文章点赞,向https://dig.chouti.com/link/vote?linksId=25703491发送post请求
res = requests.post('https://dig.chouti.com/link/vote?linksId=25703491',
headers={'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
cookies=cookie)
PS:这样登陆虽然返回状态码是9999,表示登陆成功,但是点赞是失败的,返回的9999是反扒技术返回的假信息
登陆并点赞成功案例
import requests # 打开抽屉首页
ret = requests.get('https://dig.chouti.com/',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'
})
# 网站登陆时候会携带一个首页的cookies用来做反扒验证,所以这里从首页获取
cookie_first = ret.cookies.get_dict() # 模拟登陆
ret = requests.post('https://dig.chouti.com/login',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
data={'phone': 8615618935321,
'password': 'Seep58158',
'oneMonth': 1},# 一个月自动登录,1就是True,0就是False
cookies = cookie_first
)
# cookie = ret.cookies.get_dict() 正常的思维是拿着登陆后的cookie去访问网站,但是这个抽屉网是用首页未登陆的cookie去验证全网,所以用登陆后的cookie是无效的
# 这里点赞成功
res = requests.post('https://dig.chouti.com/link/vote?linksId=25703491',
headers={'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
cookies=cookie_first)
print(res.text)
使用bs4模块实现查找数据进行自动点赞和取消点赞
import requests
from bs4 import BeautifulSoup
# 打开抽屉首页
ret = requests.get('https://dig.chouti.com/',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'
})
# 网站登陆时候会携带一个首页的cookies用来做反扒验证,所以这里从首页获取
cookie_first = ret.cookies.get_dict() # 模拟登陆
ret = requests.post('https://dig.chouti.com/login',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
data={'phone': 8615618935321,
'password': 'Seep58158',
'oneMonth': 1},# 一个月自动登录,1就是True,0就是False
cookies = cookie_first
) # 登陆成功再次进入首页,用bs4模块匹配出文章id进行点赞
s = {}
s = set(s)
for i in range(1,3):
rex = requests.get('https://dig.chouti.com/all/hot/recent/%s'%i,
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'
}) soup = BeautifulSoup(rex.text,'lxml')
# 用bs4模块找到总的标签,find是最近的一个
div_all = soup.find(name='div',attrs={'class':'content-list','id':'content-list'})
# 然后用bs4模块在上面找到数据里面做指定元素匹配div标签,findall的结果是以列表形式
div_list = div_all.find_all(name='div')
for div in div_list:
try:
# 循环到的值在进行就近匹配指定类名的标签
div_id = div.find(name='a',attrs={'class':'pinglun close-comt'})
# 如果匹配到
if div_id:
# 则取里面的lang元素的值,这个值就是文章的id
article_id = div_id.get('lang')
# 上面的数据有重复所以放入集合去重
s.add(article_id)
except Exception as e:
print(e)
for s1 in s:
# 取到文章id动态传入post请求的地址,进行点赞
res = requests.post('https://dig.chouti.com/link/vote?linksId=%s'%s1,
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
cookies=cookie_first)
# 这里是返回点赞的信息
print(res.text) # 这里是取消点赞,手动取消
ret = requests.post('https://dig.chouti.com/vote/cancel/vote.do',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
data={'linksId':'25701656'}, # 这个网站就是想vote.do发送这个字段做点赞去掉
cookies = cookie_first
)
# 返回的取消点赞信息
print(ret.text)
使用bs4模块实现自动评论
import requests
from bs4 import BeautifulSoup # 打开抽屉首页
ret = requests.get('https://dig.chouti.com/',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'
})
# 网站登陆时候会携带一个首页的cookies用来做反扒验证,所以这里从首页获取
cookie_first = ret.cookies.get_dict() # 模拟登陆
ret = requests.post('https://dig.chouti.com/login',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
data={'phone': 8615618935321,
'password': 'Seep58158',
'oneMonth': 1}, # 一个月自动登录,1就是True,0就是False
cookies=cookie_first
) # 自动评论
rep = requests.post('https://dig.chouti.com/comments/create',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
cookies=cookie_first,
# data 里的参数先取网站做一个评论,看一下网站评论发送的地址和数据格式,拷贝过来即可
data={
'jid': 'cdu_55547782293',
'linkId': '25705361',
'isAssent': '',
'content': '这个小说好看吗',
'sortType': 'score',
}
)
# 查看评论的结果
print(rep.text)
爬虫模块介绍--request(发送请求模块)的更多相关文章
- Python爬虫(二)——发送请求
1. requests库介绍 在python中有许多支持发送的库.比如:urlib.requests.selenium.aiohttp--等.但我们当前最常用的还是requests库,这个库是基于 ...
- 微信小程序开发 [05] wx.request发送请求和妹纸图
1.wx.request 微信小程序中用于发起网络请求的API就是wx.request了,具体的参数太多,此处就不再一一详举了,基本使用示例如下: wx.request({ url: 'test.ph ...
- Python day21模块介绍4(logging模块,configparser模块)
1.日志等级从上往下依次降低 logging.basicConfig(#日志报错打印的基础配置 level=logging.DEBUG, filename="logger.log" ...
- 爬虫之request相关请求
一.解析json格式数据 (1) # (1)解析json 对象数据 # import requests # 返回的数据进行解析 # response = requests.get('http://ht ...
- 第1章—Spring之旅—Spring模块介绍
Spring模块介绍 Spring7大核心模块: 核心容器(Spring Core) 核心容器提供Spring框架的基本功能.Spring以bean的方式组织和管理Java应用中的各个组件及其关系.S ...
- 模拟axios的创建[ 实现调用axios()自身发送请求或调用属性的方法发送请求axios.request() ]
1.axios 函数对象(可以作为函数使用去发送请求,也可以作为对象调用request方法发送请求) ❀ 一开始axios是一个函数,但是后续又给它添加上了一些属性[ 方法属性] ■ 举例子(axio ...
- 使用HttpClient发送请求、接收响应
使用HttpClient发送请求.接收响应很简单,只要如下几步即可. 1.创建HttpClient对象. CloseableHttpClient httpclient = HttpClients.c ...
- 使用HttpClient发送请求接收响应
1.一般需要如下几步:(1) 创建HttpClient对象.(2)创建请求方法的实例,并指定请求URL.如果需要发送GET请求,创建HttpGet对象:如果需要发送POST请求,创建HttpPost对 ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
随机推荐
- shell脚本中给字符串添加颜色
shell脚本中echo显示内容带颜色显示,echo显示带颜色,需要使用参数-e 格式如下: echo -e "\033[字背景颜色:文字颜色m字符串\033[0m" 例如: ec ...
- MyBatis工具类
package cn.word.util; import java.io.IOException;import java.io.InputStream;import java.util.Enumera ...
- iOS 判断一个类是否存在,NSStringFromClass 不用 import 就可以获取类
Class myCls = NSClassFromString(@"Person"); NSString *str = NSStringFromClass(myCls); if ( ...
- Python字典的使用与处理
在Python中,字典{dict}是比较常用的一个数据类型,使用键-值(key-value)存储 与列表[list]相比,字典具有极快的查找和插入速度,不会随着key-value的增加而变慢,但是相应 ...
- ubuntu1604使用之旅——Qt交叉编译移植
1.手头已有Qt-Embedded-5.7.0.tar.gz 2.解压 3.sudo cp Qt-Embedded-5.7.0 -r /usr/local/ 4.sudo vim ~/.bashrc ...
- echarts折线图
https://echarts.baidu.com/examples/#chart-type-bar
- IDEA2017 免费激活方法
选择license server,然后填下面地址,选择一个就好. http://intellij.mandroid.cn/ http://idea.imsxm.com/ http://idea.ite ...
- shell编程(二)
第三十二次课 shell编程(二) 目录 十五.shell中的函数 十六.shell中的数组 十七.告警系统需求分析 十八.告警系统主脚本 十九.告警系统配置文件 二十.告警系统监控项目 二十一.告警 ...
- /usr/lib/x86_64-linux-gnu/libopencv_highgui.so:对‘TIFFReadRGBAStrip@LIBTIFF_4.0’未定义的引用
LIBRARIES += boost_thread stdc++ boost_regex https://github.com/rbgirshick/fast-rcnn/issues/52
- ORACLE取字段中的注释
select * from (SELECT 'comment on column '|| t.table_name||'.'||t.colUMN_NAME||' is '|| ''''||t1.COM ...